




2種類のプロセッサーを搭載するAiOnIc
肝心のAIプロセッサーであるが、なんとAiOnIcは2種類のプロセッサーを搭載している。もともと、“RISC-V w/SMT”とGPGPUの2つのプロセッサーコアが存在することが、前ページにあるchichibuチップの内部構造の画像で明らかにされているが、Int 2/4/8を使った(つまり精度がそれほど必要ない)用途向けにLow Power AIプロセッサーが、fp8/fp16を使った精度が必要な用途向けには汎用プロセッサーが用意されている。
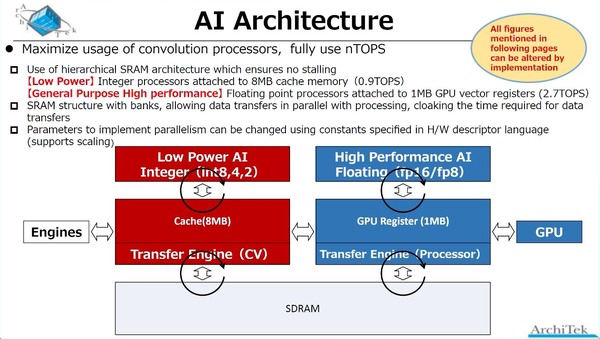
Low Power AIは0.9TOPS、High Performance AIは2.7TOPSで「逆じゃないか?」という気もするが、その代わりLow Power AIを使うと消費電力が大幅に抑えられる、ということだろう
まずLow Power AIの方であるが、前ページにあるchichibuチップの内部構造画像でGPGPUという書き方をしていた。実際は? というと、下の画像のように16bitのMACエンジンの塊になっており、なるほどこれはDSPというよりはGPGPUに近いなと思う。
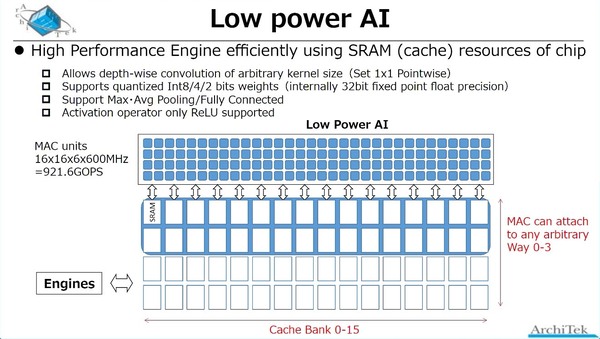
Low Power AIの概要。数字の試算はInt 2の場合と思われる。Int 4なら460.8GOPS、Int 8なら230.4GOPSであろう
本当にもう畳み込みをするだけに特化したエンジンという感じである。また最大/平均のプーリングや全結合などもハードウェア的に実装されており、余分な手間なしで処理できる。その一方で、活性化関数はReLUのみ実装、というあたりはいろいろ割り切ったことが見られる。
一方High Performance AIの方であるが、先のchichibuチップの内部構造画像と併せて考えると、これはSMTに対応したRISC-Vコア(おそらくこちらもRV32系だろう)にVector Extensionを付けたコアが実装されており、このVector Extensionをブン廻すことで対応する形だ。
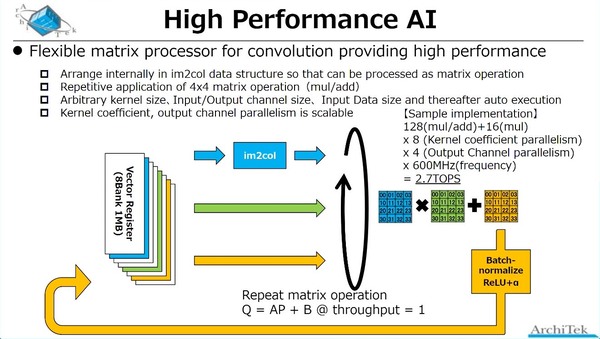
High Performance AIの概要。おそらくchichibuチップは、このRV32Vチップを4つ搭載する前提だと思われる。それにしても、×8のKernel coefficient parallelismの意味がよくわからない
市販のIPでこの目的に適うものは存在しないが、例えば連載594回で紹介したEsperantoのET-Mineonは、こちらもSMTに対応したRV32コアで、ただしRVV(RISC-V Vector)をサポートしている。SMTの目的はメモリーアクセス待ちなどのレイテンシー遮蔽であり、これはAiOnIcでも同じことだと思われる。
おそらくRV32コアそのものは、アプリケーションプロセッサー(兼システム制御用)のSiFive E34コアと同等の、In-Order Single Issueで5~6段程度のパイプラインという比較的小さなコアで、このコアそのもののエリアサイズはそう大きくはないと思うのだが、問題はVector UnitとLoad/Store Unitはそれなりの面積になりそうなことだ。
これを4つも入れたら冒頭に書いた「80~90mm2前後」どころか「120mm2」も怪しそうな気はするのだが、これはプロセスの微細化が前提なのだろう。逆に言えばbeppuチップは、おそらくRISC-Vコアは1つだけだろうし、Low Power AIの方ももう少し規模が小さいと思われる。
そのあたりのロードマップが下の画像だ。現在はTSMCのN12でbeppuチップを製造しているが、おそらくchichibuチップはTSMCだとするとN7あたりに移行して製造されるものと思われる。
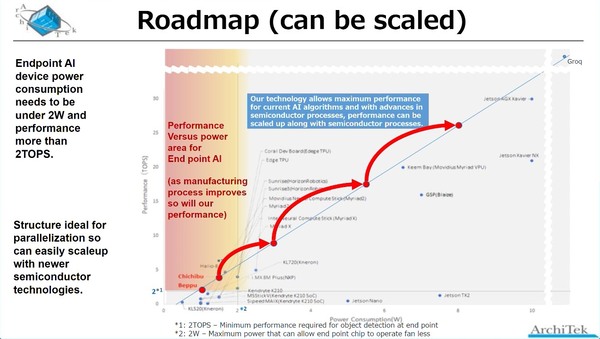
Low Power AIを使う場合が1W/1TOPS、High Performance AIを使う場合が2W/2.7TOPSというあたりだろうか
ちなみにN7を使う場合、ウェハーの製造コストは9300ドルほどになる。したがって、冒頭に出て来たチップ単価10ドルを実現するためには、最低でもウェハー1枚から900個、実際には1000個程度取らないと実現できないことになる。
1000個だとするとダイサイズは最大で70mm2、実際には50~60mm2あたりで抑える必要があるだろう。幸いにもN12→N7でトランジスタ密度そのものは3倍程度になるため、ダイサイズが減っても利用できるトランジスタ数は1.5倍近くになるので、一応微細化の意味はあると言える。
もっとも、プロセス微細化よりも(単価アップには目をつむって)回路規模を大きくする方が性能をスケーラブルに上げられるとしており、実際同社からこのAiOnIcのIPの提供を受けた顧客の場合、400TOPSのチップを製造しているとする。
同じTSMCの12nmであっても、例えばもう少し動作周波数を下げて、その分アクセラレーターやプロセッサーの数を増やすことで消費電力をそれほど上げずに大幅に性能向上を実現できた、というあたりと思われる
同社はチップを提供、というよりもソリューションを提供することを志向しているようで、ただなにもないと開発にも困るのでとりあえずbeppuチップを製造、ついで本番向けにchichibuチップを製造する予定ではあるが、むしろbeppuチップを評価の上でIPの供給を受けて自社でAiOnIcベースのチップを製造する顧客を増やす、というのがビジネスの方向性のように思われる。
ベンチャー企業がチップの製造をメインに据えるといろいろ難しさが出てくるというのは、例えばETA Computeのケースでも紹介した通りで、IP売りをベースにSoC設計サービスなども行ないつつ基本はソリューション提供、というのは堅実な方法なのかもしれない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























