




異様にアクセラレーターが充実している「chichibu」
さてこれらの目標に向けて試作したbeppuチップ、まずは一般的な評価ボードと、AIカメラ向け評価ボードの2つの開発キットが用意された。
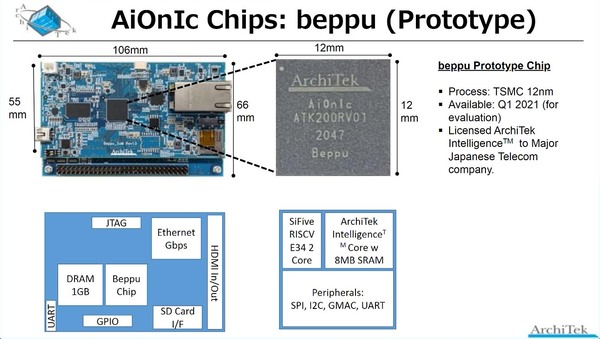
DRAMが外付けになっている時点で前の画像で言う“1 Chip Solution”ではない気がするが、これはおそらくE34コア用のものだろう。ライセンスの話は後述する

AIカメラ用にはDRAMが8GBに増えているのは、それだけバッファメモリーが必要ということだろうか?
ただ今回はそのbeppuチップの中身ではなく、beppuチップを基にしたchichibuチップの内部構造が紹介されたのだが、少し変である。Processor GroupはRISC-VエンジンとGPGPUエンジン、GEMMエンジン、それとGEMM用のDMAからなるが、それとは別に異様に充実したアクセラレーターが搭載されている。
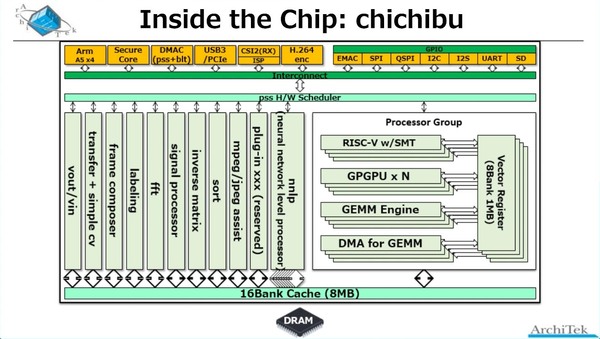
chichibuチップの内部構造。FFT専用アクセラレーターまで搭載されているのはさすがである。このあたりは画像のフィルタリング向けと思われる。mpeg/jpeg assistはイメージ展開用だろうか?
AiOnIcでは暗部補正、逆光補正といった撮影映像の補正や、SLAM(Simultaneous Localization and Mapping:自走ロボットの制御などで使われる自己位置推定と環境地図作成)、人物検出、パレット認識など、いくつかのアプリケーションシナリオが用意され、そのシナリオに応じてこの豊富なアクセラレーターとProcessor Groupで提供されるAIエンジンを適時組み合わせ、必要な処理を行なう。この際のデータの受け渡しは16バンク構成の8MBキャッシュ経由になる模様だ。
ちなみにそのアクセラレーターの中で、nnlp(Neural Network Level Processor)なるものだけは複数存在しているように見えるが、これがなにをしているのかは説明がなかった。名前からすると、畳み込みニューラルネットワークの重みというかネットワークの係数のハンドリングを処理するプロセッサーだろうか?
逆に詳細が説明されたのがFrame Composerで、これはOpenCVの処理をハンドリングできるものという話であった。これらの固定機能アクセラレーターを組み合わせることで、例えばAffine変換(画像の拡大縮小や回転、平行移動など)は1命令で処理可能としている。
特徴的なのはこのアクセラレーターとAIプロセッサーは同じ扱いであり、全部スケジューラー(上の画像で“pss H/W Scheduler”と書かれている部分)から制御され、おそらくはサイクルレベルでこれらを順次切り替えることで、同時に多数のスレッドを動かすことだ。
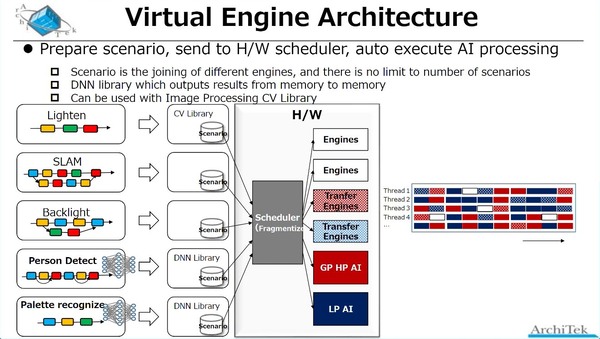
ここで言うスレッドは、ある特定の処理の流れ(それこそ映像補正やSLAMなど)の1つ1つを指すことになる。CPU内部のスレッドとは異なる意味合いと思われるので注意
つまり、1つのAiOnIcで、複数のアプリケーションを同時に動かすことが可能というわけだ。実際、下の画像のように12種類のアルゴリズムを同時に動かすというデモも示された。

ただ実際のアプリケーションで、これらを同時に行なうというニーズがどの程度あるのかは不明である。もちろんないわけではないとは思うのだが
逆に言えば、1種類だけのアプリケーションを高速に動かすようなケースでは、特定のアクセラレーターあるいはAIプロセッサーの能力が先に飽和してしまいそうではある。このあたりはバーターなのであろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ










とBTO PCならではの特注PCパーツに大興奮")
























ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












