




カード1枚あたりの性能はNVIDIAにはかなわないが
消費電力が低いのでNVIDIAより圧倒的に高効率
ここからは性能の話だ。性能を何で比較するのが公平か? に関しては連載613回でも少し触れたが、IPS/Wを採用する方向のベンダーが次第に増えつつある。Qualcommもその方向性ではあるのだが、HotChipsではその前段階としてTOPs/Wの数字が示された。

Cloud AI 100の性能。実のところ10TOPs/Wを超えているのはTDP 15WのDM.2eのものだけで、サーバー向けのPCIeカード(TDP 75W)では5.24 TOPs/Wとだいぶ悪化しているのは、想像できたことではある
数字が3種類あるのは、もともとCloud AI 100には連載583回で紹介したように3種類のSKUが存在し、それぞれ異なるTDP(15W/25W/75W)になっているためだ。これは別にCloud AI 100に限った話ではなく、それこそCore iやRyzenなども同じだが、性能効率を上げたければ動作周波数を落とした方が効果的である。

Cloud AI 100にはDM.2e、DM.2、PCIe/HHHLの3つのSKUがある
動作周波数が低い時にはかなり動作電圧を落とせるが、あるところから先は動作周波数の上がり方より電圧の上がり方が急になる。消費電力は電圧の2乗に比例することを考えれば、一番動作周波数が低いと思われるDM.2eタイプのものが一番効率が良いのは当然だ。
とはいえ、実シリコンで10TOPs/Wを超えたというのはなかなかインパクトのある話である。もう少し現実的な数字として、推論についてIPSおよびIPS/Wを示したのが下の画像だ。
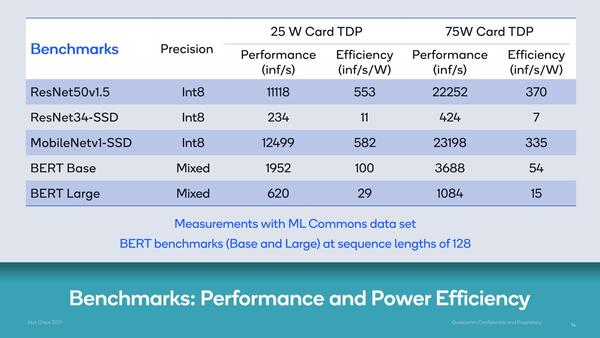
25Wカードは75Wのほぼ半分の性能といったところで、一方消費電力は1/3なので、25Wの方が効率が良いのは明白である。おそらく15Wカードではさらに効率は上がるだろうが、絶対的な性能が低すぎることになる
バッチサイズと性能の関係が下の画像であり、Qualcommが提供するAIMET(AI Model Efficiency Toolkit)というツールを利用してネットワークを圧縮した場合の性能向上率と精度の悪化率をまとめたのがさらにその下の画像となっている。
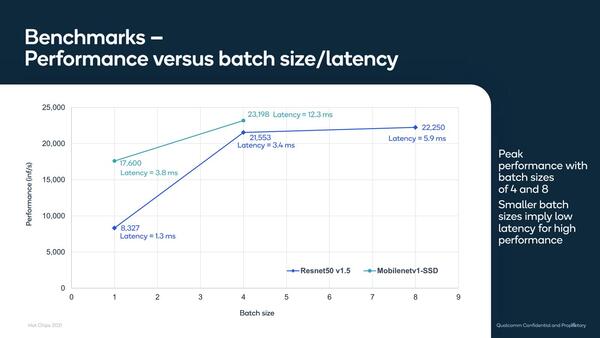
バッチサイズと性能の関係。GPUではバッチサイズを最低でも16、できれば128にしないとフルの性能が出しにくい(もちろんネットワークにもよるが)のに対し、Cloud AI 100ではバッチサイズ=4あたりでほぼピーク性能に近いところまで達しているのがわかる
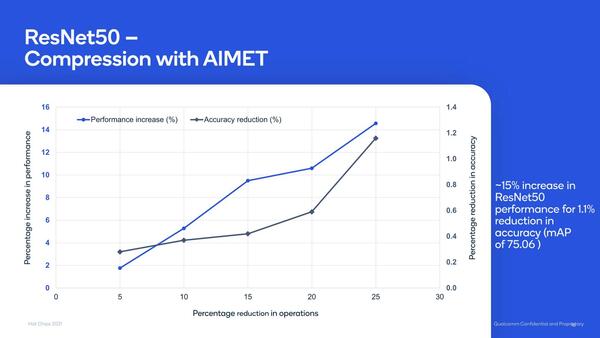
横軸が圧縮率。青が性能向上率、黒が精度悪化率で、例えば5%圧縮にすると2%の性能向上と0.3%程度の精度悪化、25%圧縮にすると14%強の性能向上と1.1%強の精度悪化になる。おそらく15%圧縮あたりが、性能と精度のバーターで一番美味しいあたりになるだろう
これらの数字はMLPerf 1.0ベースでの結果であり、数字そのものはかなり優秀な部類に入るのだが、MLPerf 1.0はそもそも結果があまり集まっていないこともあって、今一つそのすごさが伝わりにくかった。
そこで、MLCommonsがMLPerf 1.1の結果を発表したのに合わせ、QualcommもそのMLPerf 1.1に関するサマリーを公表している。ちなみにMLPerf 1.1はデータセンター向けとエッジ向けの、しかも推論のみが公開されている。昔のロードマップでは、推論に先駆けて学習向けが先に実施される予定だったはずだが、少しずれた格好だ。
このMLPerf 1.1で、QualcommはNVIDIAを非常に強く意識した説明をした。ここではTOPs/Wではなく、IPS/W(Inference Per Second/W)を意識した結果になっており、NVIDIAの製品と比較して圧倒的に効率が良いとしている。
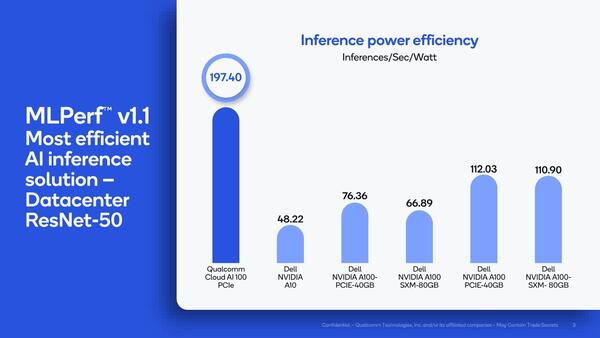
もっとも、MLPerf 1.1でもOpen-Power(消費電力の測定までしてその結果を公開したもの)はあまりなく、事実上QualcommとNVIDIAの一騎打ちになっているというあたり、必然的にこうなってしまった感もある
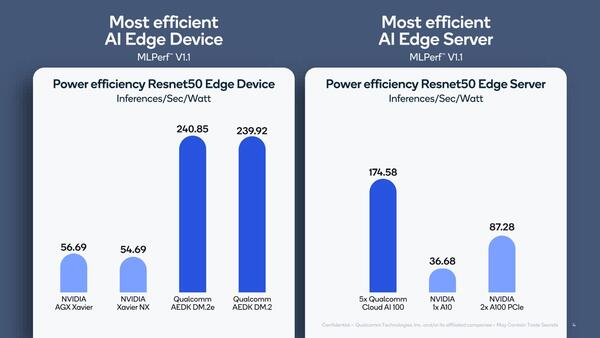
サーバー向けがCloud AI 100カード×5となっているのは、絶対性能で言えばNVIDIAのA100の方が「1枚あたりの性能は」ずっと高いためである
下の画像が実際にMLPerf 1.1に登録された数字である。

上の2つはデータセンター向け、下の2つはエッジ向けに登録されている
この連載の記事
-
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 - この連載の一覧へ

















の1台が今ならオトク!")



























")













