




カードを増やせば16枚までは性能が上がるが
17枚以上の構成に課題が残る
さて、このあたりからいろいろ話がややこしくなる。下の画像は、実際の構成に近い。つまりQualcommは8~16枚のカードを、NVIDIAのものは8~10枚のカードをそれぞれ装着した場合の推論性能を比較したものだ。
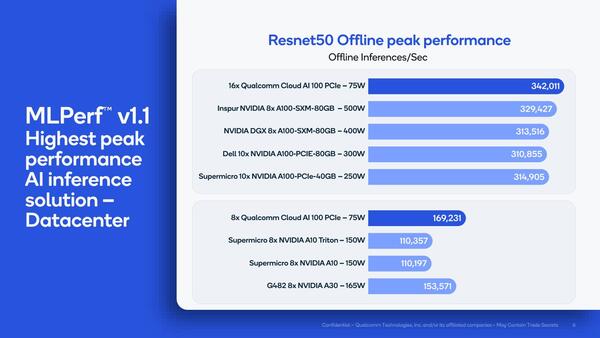
推論性能を比較したもの。NVIDIAの場合、複数のベンダーがA100を利用した結果をMLPerfに登録しているのでグラフが多い
Qualcommの場合、PCIeがx8になっているので、1P/2PのEPYCサーバーでは最大16枚の装着が可能である。カード1枚あたりの絶対性能そのものは前述の通りNVIDIA A100には敵わない。その一方で、同じPCIeバスなら2倍のカードが装着できるし、TDPはモジュールタイプのA100が最大500Wに達するのに対し、Cloud AI 100は75Wなので、2倍の枚数を装着しても消費電力は10分の3という計算になる。
問題は枚数を増やした時に、どの程度性能が上がるかという話であるが、Qualcommのテストによればさすがに完全に直線というわけではないにしても、かなり上昇するとしている。
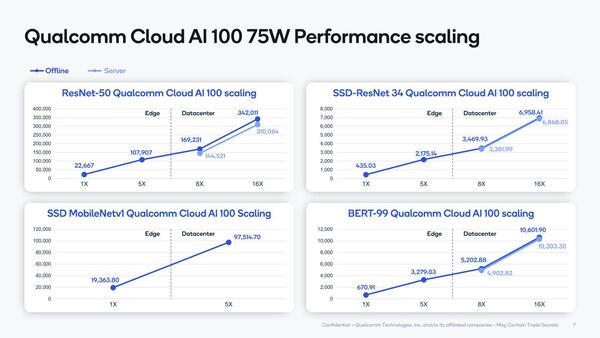
ResNet-50は1xと16xで15.1倍、SSD-ResNet 34で16.0倍、BERT-99で15.8倍である。またMobileNetv1では1xと5xで5.04倍になっており、少なくとも16枚まではほぼ性能が上がるといっていいだろう
また消費電力が比較的低いのも特徴である。下の画像は16枚および8枚のシステムの性能と消費電力の比較であるが、ここで水色に塗られている部分が他のシステムと比較して優れている結果を出したものである。

システムの性能と消費電力。16枚のサーバーで2KW未満、8枚では900W未満で稼働する。900Wというと、NVIDIA A100 SMXが2枚の構成ですでにオーバーしかねない
この結果は、BERT-99やBERT-99.9などの自然言語処理では性能が今一つ(少なくとも最高速ではない)という数値であるが、このクラスになるとコアあたり9MBではネットワークが乗り切らないあたりが敗因なのかもしれない。
Edge Server/Edge Deviceにおける結果をまとめたのが下の画像だ。Edge Serverは5枚のPCIeカード、Edge Deviceの方はDM.2eないしDM.2での結果だが、PCIeの方はともかくDM.2/DM.2eの方は他を圧倒する結果になっており、その意味では当初の開発キットがEdge Deviceをターゲットとしたことの正しさがよくわかる。
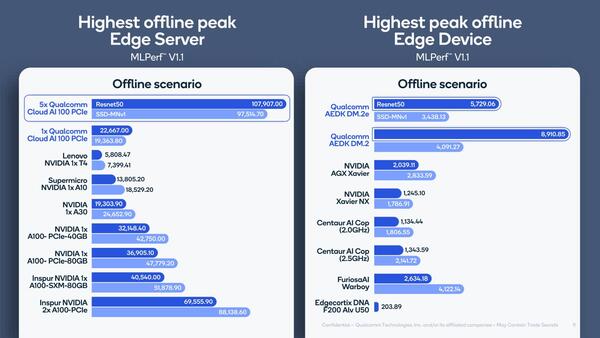
Edge Server/Edge Deviceにおける結果。Edge Deviceの方にCentaurのCHA+NCoreまで入っているのがややおもしろい
スライド自体はもう何枚かあるが、あまり重要ではないので割愛する。ここはQualcommが実シリコンでその性能を示したことが大きなポイントである。少なくともNVIDIAのエッジ向けであるAGX XavierやXavier AXと比較すると数倍の性能差があり、これは乗り換えには十分な動機になりえる。
その一方でサーバー側で言えば、確かに性能/消費電力比では確かにNVIDIAよりだいぶ良いように見えるが、その一方で絶対性能そのものはあまり大きな差とは言いにくいあたりは、既存のNVIDIAベースのソリューションを突き崩すにはやや弱い感じもある。
とりあえずQualcommはまずEdge Deviceに注力しつつ、あわよくばサーバー側も、といった感じなのだろう。ただ現状では17枚以上の構成はソフトウェアフレームワーク的に対応できないあたりが難点であり、このあたりをもう少しどうにかして、もっと大規模に性能を向上させる方策を見つけないと、サーバー向けには厳しそうだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第886回
PC
CFETの足を引っ張るPMOSを救え! imecが提案する新絶縁層と、あえて精度を緩める「Notch Alignment」の妙手 -
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 - この連載の一覧へ












ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")








ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












