



ロードマップでわかる!当世プロセッサー事情 第632回
Intel 7とTSMC N5で構成されるHPC向けGPUのPonte Vecchio インテル GPUロードマップ
2021年09月13日 12時00分更新

Ponte Vecchioは
合計47 Tileで構成される
前ページにある情報をベースにPVC 2TことPonte Vecchioの構成をまとめたのが下図である。パッケージにはBase Tileが2つ載り、各々のBase Tileの上にはCompute Tile×8とRambo Cache×4がFoverosで接続されている。
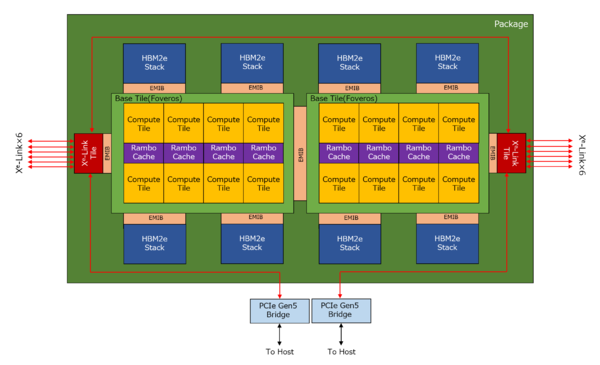
Ponte Vecchioの構成図
また、それぞれのBase TileからEMIB経由でHBM Stack×4とXe-Link Tile×1が接続されている。そしてBase Tile同士もEMIBで接続されるというわけだ。これで合計47 Tile(EMIBもTileとして数える)という構成である。
連載569回で説明した構成では、1つのRambo CacheにCompute Tileが4つ付く構造になっていたが、そもそもこちらは概念図のようなものなので、実際には2つのCompute TileにRambo Cacheが1つ付き、そのRambo CacheからHBM2eがぶら下がる格好になると思われる。
HBM2eのコントローラーそのものは、Base Tileに載っているのではないかと思う。そしてXe-Linkであるが、各Xe-Linkから8本のLinkが出るが、ウチ1本はパッケージ内で2つのBase Tileの接続に、さらにもう1本はパッケージの外にあるXe-Link/PCIe Gen5 Brigeに接続されるものと考えられる。
確証があるわけではないのだが、Ponte VecchioのOAMに載っている謎の2つのチップが、このXe-Link/PCIe Gen5 Bridgeではないかという気がする。

PMICには大きすぎる気がするし、他のモジュールへのReTimerという可能性もあるが、Xe-Linkのままではホストと接続する方法がないので、どこかにブリッジが必要なのは事実で、このチップがブリッジではないかと筆者は考えている
外部出力がなぜ6本かというと、そもそもシステムでは4つのPonte Vecchioを1つのサブシステムとして扱っている。したがって、これをすべて1:1接続にするためには、各Ponte VecchioのXe-Linkは自分以外の7つのXe-Linkに接続しなければならない。ただ上の図で描いたようにうち1本はパッケージ内を通って接続されるので、外部接続は6本あれば済む計算だ。
パッケージサイズは77.5×62.5mmと判明
資料には4スタックらしき画像があるが……これはいったい?
HotChips 33のカンファレンスセッションでの情報はこの程度だが、こちらもチュートリアルセッションでいろいろ話が出てきた。まずPonte Vecchioのパッケージサイズだが、77.5×62.5mmとなかなかのサイズ。もっともHBMを8つも搭載していることを考えれば、そう大きくもないかもしれない。
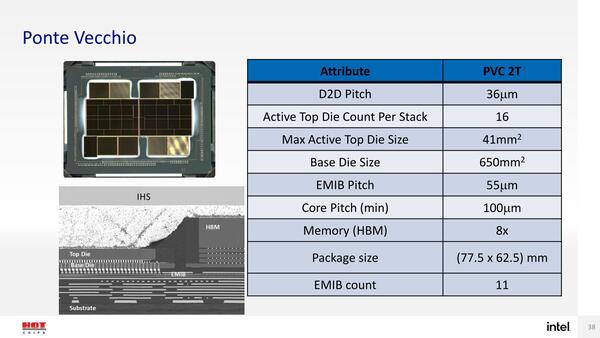
Ponte Vecchioのパッケージサイズは77.5×62.5mm
それよりも興味深いのは“PVC 2T”という表記だ。“2T”ということは、“1T”や“4T”があっても不思議ではない。実際、Ponte Vecchioは物理的には綺麗に2つに分離しており、間をEMIBでつないでいるだけなので、PVC 1Tを作るのはかなり容易だ。
一方4Tの方は、説明の途中でこんな図(下の画像右下)が出てきて、「これは何だ?」という話になった。

上は完全にPonte Vecchioの断面図である。一番右の“Companion Die”はXe-Link Tileであろう。それより右下の図は4層あるように見えるが、これはいったい……
この図の説明を求めて速攻でRaja Koduri氏に突撃した人がおり、その答えがこちら。
???♂?seems like the digital legos are easier to build than the real one..inspired by you we keep ‘nom nomming “ those extra “stacks” there’s no 4-stack ponte vecchio ??
— Raja Koduri (@Rajaontheedge) August 23, 2021
「実際のチップと違って、『デジタルレゴ』ではこういうものが簡単に作れるからね。(この図は)余分な“Stack”が載ってるが、4 StackのPonte Vecchioは存在しない」という返事である。
ただ、Auroraに向けては2 Stack構成でいいかもしれないが、今後幅広くPonte Vecchioを売っていくつもりなら、派生型として1 Stack製品があっても不思議ではない。4 Stackは正直実現可能性は低そうに思えるのだが。
Xe-Linkの帯域を使いきるには
EMIBの信号速度がネックになる
あともう1つ、EMIBについて。下の画像は従来型パッケージとEMIBの特性を比較したものだが、配線密度はEMIBの方が上がるのは事実で、Bump Pitch(パッケージの底面にある半田ボールの間隔)は従来型の半分であり、配線密度はラフに言って4倍にできることになる。

従来型パッケージとEMIBの特性を比較したもの
それはいいのだが、Pin Speedそのものは、従来パッケージが最大16Gbpsまでいけるのに対し、EMIBでは5.4Gbps程度となっている。これはHBM2eの実装には困らないが、UPI 2.0や今回のXe-Linkの実装にはやや厳しい数字である。
前回は触れなかったが、Sapphire Rapidsの場合、UPIが24bit幅でしかも16Gbpsとなっている。24bitという幅もよくわからない(16bit Data+4bit Address+4bit ECCあたりだろうか?)のだが、それよりも16GbpsともなるとそのままではEMIBで利用できないことになる。
これは一応策があり、送信側は16Gbpsのレーンを4Gbps×4に変換し、受信側で4Gbps×4を16Gbps×1に変換してやれば良いことになる。MUX/DEMUXなどと呼ばれる(イーサネットの世界ではこれをギアボックスと呼ぶ)が、多少オーバーヘッドはあるものの信号速度が落ちる分安定度はあがるし、EMIBを使えば信号本数が増えても十分対応できる。
Ponte VecchioではXe-Linkの帯域は90Gbpsを超えるとしている。おそらく1レーンあたり10Gbps超ということだろうが、ということはBase TileとXe-Link Tileの間は、これも5.4Gbpsを超えないように、1レーン分あたり2本以上の配線を使って接続していることになる。なんというか、いろいろ大変だなぁと思わざるをえない。というか、予想外にEMIBに厳しい制限がついていることに驚いた。
Foverosの方は、こうした信号速度に関する制限の話は今のところ開示されていないが、こちらはどの程度までいけるのか気になるところである。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























