



ロードマップでわかる!当世プロセッサー事情 第625回
脳の神経細胞を模したSNNに活路を見出すInnatera Nanosystems AIプロセッサーの昨今
2021年07月26日 12時00分更新

脳のシナプスのつながり方を模した
Spikeモジュール
ところで先に、複数のSpikeが来てから発火すると説明したが、これを行なうのはセグメントの出口に置かれたSpikeモジュールである。こちらはなんとコンデンサーを使ってパルスを蓄積する仕組みである。
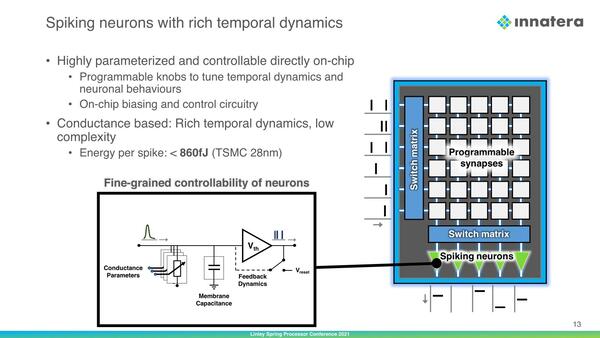
コンデンサーなので、時間を経るとだんだん蓄積した電荷量も減っていくわけで、内部の値が時間経過で少しづつ減っていく構造を簡単に実現できることがわかる
要するにコンデンサーに必要な量のSpike(でやってきた電荷)が溜まると満杯になり、その結果として「発火」が発生するわけだ。どのくらいのSpikeで満杯になるかの調整は、その手前の“Conductance Parameter”で行なえる。
昨今のデジタル回路でも抵抗とコンデンサーくらいであればそう難しくなく実装できるわけで、極めてアナログ的ながらエレガンスにこれを実装した形だ。
それぞれのシナプスをつなぐのは、先にも出てきた2種類のインターコネクトだ。それぞれ特徴は違うので、ショートレンジの方は数で帯域を稼げるからそもそも高速でなくても構わず、むしろレイテンシーを下げる方に振っており、ロングレンジは必然的に本数が減る分帯域を引き上げる構成になっている。どのセグメントをどうつなぐかはセグメントへの配同様にコンパイル時に決定される模様だ。
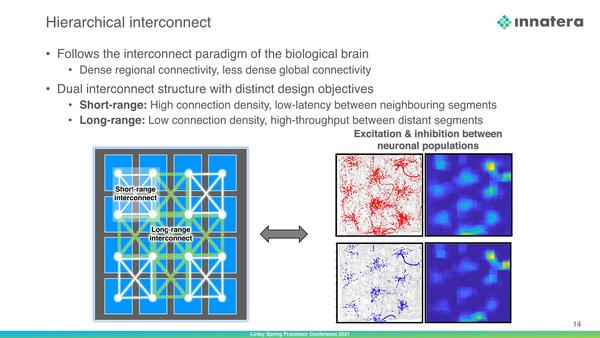
2種類のインターコネクトを用意したのは、実際に人間の脳でのシナプスのつながり方が、近傍のシナプスと接続されることが多いことに対応した(そこからヒントを得た)のではないかと思われる
ところでニューロン間のSpikeの伝達であるが、Spikeは単にデータでしかないので、このままでは「このSpikeをどのニューロンに伝達するか」の表現ができない。これをカバーするのがAERである。
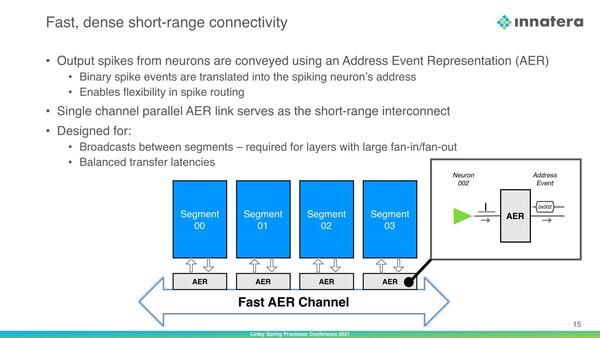
AERは6つ前の画像だとNeuro-Syaptic Segmentの外に置かれているが、これを見ると実際には個々のセグメントに配されているような気がする。ちなみにFast AER Channelは、Short-range Interconnectが利用されているとのこと。というよりShort-range InterconnectにはFast AER Channelの機能が当初から内包されているというべきか
AERはSpikeに対し、「そのSpikeをどこに伝達すべきか」という情報を付加する機能を持つ。これによって、Spikeを正しく伝達できるようになっている。このあたりは、例えばFPGAであればLUT間の配線を1本単位でどうつなぐか定義できるので、逆に言えば「どこに伝達するか」の問題が発生しないが、こちらのインターコネクトはもっと汎用的な作りになっており、アドレスを付加しないとどこに伝達するかが特定できないのだろう。ちなみにこれはLong-range Interconnectでも同じなようだ。
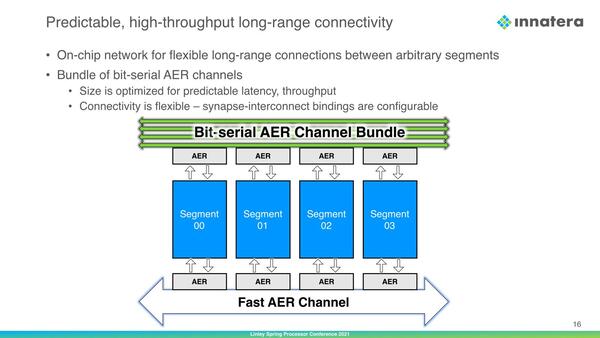
このあたりがシナプスを汎用プロセッサーで模する際の制約だろう。もっともこのあたりはトレードオフであって、FPGAであればAERは不要なのだろうが、アナログ的な処理はできなくなる
現状ではまだInnatera Nanosystemsは物理的なチップは製造できておらず、あくまでシミュレーションの形で処理をぶん回している結果であるが、例えば音声のパターン認識(喋った言葉の特定)を従来型のDSPやCNNベースのAIプロセッサーと比較した場合、レイテンシーは40分の1、消費電力は49分の1といった数字が出ている。
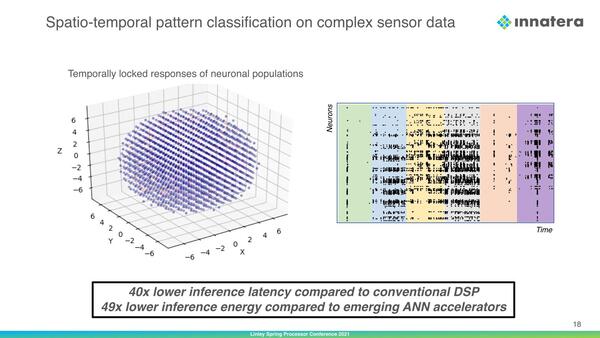
レイテンシーはDSPと比較して、消費電力は従来型AIアクセラレーターと比較しての数字。このあたりはわざとぼかしてある感じである
実は2020年11月に米EETimesが取材した際の数字では、従来型DSPと比べて100倍高速で、消費電力が500分の1だという、なかなか刺激的な数字が並んでいたことを考えると、やや後退というか正気に戻ったというか、多少妥当性があがった感はある。
冒頭にも書いたが現在のSNNのアドバンテージは性能そのものよりも省電力性の方が大きく、これを正しく実装したことになる。同社は現在特定顧客とユースケースの実現に向けて作業しており、これは今年年末までにデモをできるようにしたいとのこと。また最初のエンジニアサンプルシリコンは今年後半に出てくる予定で、これとSDKをあわせて特定顧客向けに出荷したいとしている。
難しいポイントがあるとすれば、Edgeの一番端っこで使われることで、実際の販売形態はチップを売るというよりもEdge向け製品(それこそMCUとかだ)にIPの形で提供するような形態になると思われる。
ビジネス的にはETA Computeと同じ市場を狙っている格好だが、そのETA Computeも方針が二転三転していることを考えると、同社にしても前途洋々というわけではないだろう。
広くIPプロバイダーとして広範な顧客にIPを販売できるか、それともどこかに買収されるのか。そのあたりも含めて今後が気になる存在である。
この連載の記事
-
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 - この連載の一覧へ

















の1台が今ならオトク!")



























")













