



ロードマップでわかる!当世プロセッサー事情 第625回
脳の神経細胞を模したSNNに活路を見出すInnatera Nanosystems AIプロセッサーの昨今
2021年07月26日 12時00分更新

SNNチップを開発する
オランダのInnatera Nanosystems
毎度のことながら長い前置きで恐縮だが、今回取り上げるのはこのSNNに向けたチップを開発しているオランダのInnatera Nanosystemsである。
創業者はSumeet Kumar博士。博士はオランダのデルフト工科大学で2015年に博士号を取得後、1年だけインテルに務めるが、そのあと再びデルフト工科大学に戻り、プロジェクトマネージャー兼研究フェローとして自動車の自動運転やセキュア・プロセッサ―/SoCなどの研究プロジェクトの指揮を2020年まで取っている。その研究プロジェクトの中にはSNNに関するものもあったのかもしれない。
2018年1月、博士は突如としてInnatera Nanosystemsを立ち上げる。といってもデルフト工科大でのプロジェクトの指揮はそのまま取り続けており、要するに2018年からは二足の草鞋を履いた状態で働いていた格好だ。2020年一杯でデルフト工科大のプロジェクトの指揮からは降りたようで、2021年からはInnatera NanosystemsのCEO職に専念している。
ちなみに共同創業者はCOOのUmaMahesh Saraswatula氏とCSO(Chief Scientist Officer)のAmir Zjajo博士で、Zjajo博士はやはりデルフト工科大で2020年までプロジェクトリーダー兼研究フェローの職についておられた。

左奥からCSOのAmir Zjajo博士、Rene van Leuken教授、CEOのSumeet Kumar博士。手前画面がCOOのUma Mahesh氏
またチーフアドバイザーとしてデルフト工科大のRene van leuken准教授がやはり創業者に名を連ねているあたりは、二足の草鞋というよりはInnatera Nanosystems自身がデルフト工科大のスピンオフ的な位置づけにあるのかもしれない。
同社の会長には、今年7月14日にUCバークレイのAlberto L. Sangiovanni-Vincentelli教授が就任した。このVincentelli教授、CadenceとSynopsysという2大EDAベンダーの創業者でもあり、半導体業界では超有名人だ。もっとも会社の規模ではまだ非常に小さいようだ。そもそも同社が有名になったのは、2000年11月に500万ユーロのシードマネーをファンドから調達したからで、人員の確保もこのあたりからスタートしたのではないかと思う。
さてそのInnatera Nanosystemsが狙うのは、推論の市場の中でも、一番センサーに近い末端である。消費電力枠はmWオーダーであって、これまで説明してきたさまざまな推論向けのAIプロセッサーよりもさらに一桁以上小さい市場である。ここに同社はSNNを持ち込もうというわけだ。
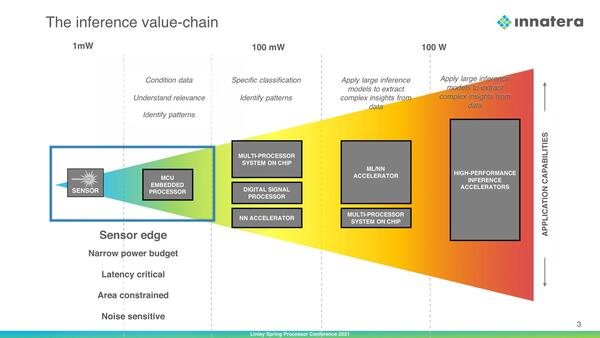
それこそセンサー(それは温度だったり振動だったり気体だったりさまざまだろうが)に直結するとか、下手をするとセンサーのパッケージに収められるような推論向けプロセッサーが同社のターゲットである
そのSNNの基本的な原理は下の画像のとおり。先ほど説明した内容を、改めて図で示した格好だ。
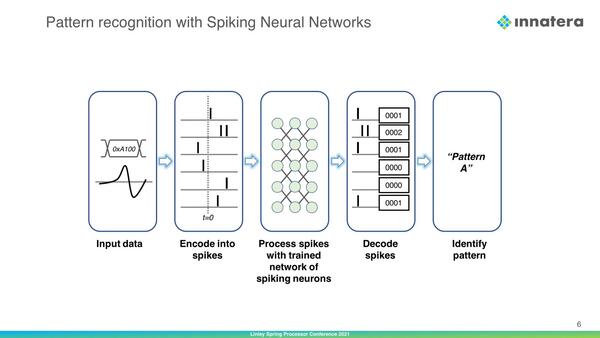
入力をどうSpikeにエンコードするか、というところが実装のポイントの1つではある
下の画像は、複数のSpike(いわゆるニューロン間で伝達されるパルスを同社はSpikeと表現している)からどう「発火」するかを示したものだ。複数回のSpikeを受けることで内部の値がだんだん閾値に近づいていき、これを超えた瞬間に「発火」が起きる格好である。
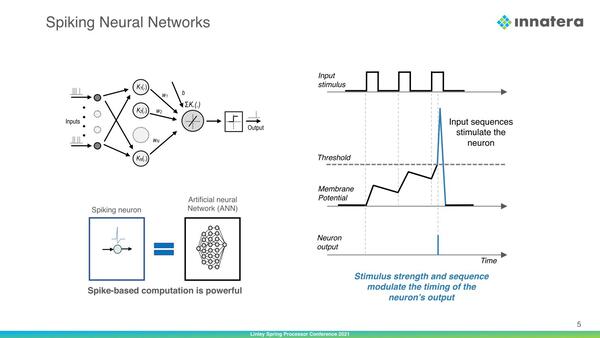
一度「発火」が起きると、内部の値は一度0クリアされ、一定期間パルスを受け付けない状態になる。また、内部の値は時間経過で少しづつ減っていくことにも注意。なので「発火」にはある程度の頻度でパルスが到来する必要がある
このSNNの処理を、Innatera Nanosystemsはアナログ/デジタルの混成で実装しようとしている。下の画像が同社のSNP(Spiking Neural Processor)の概略であるが、まずデジタルで受けた値をSpikeエンコーダーを通してSpike信号に変換。これをNeuro-Syaptic Segment部で処理し、最後にSpikeデコーダー経由でデジタルに戻し(この際にPattern Lookup tableを参照して、どんなパターンをどう出力するかを決める)、出力するという構成である。
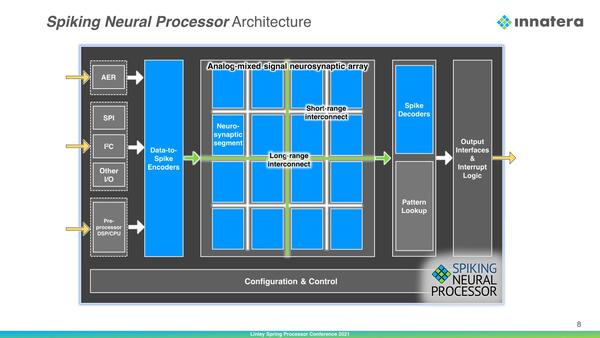
グレーがデジタル、ブルーがアナログ/デジタル混載の部分である。AER(Address Event Representation)は後述する
そのNeuro-Syaptic Segment部の概略が下の画像だ。全体が16というのは単に図版の関係であってもっと縦横に分割数は多いと思うのだが、隣接セグメント同士をつなぐShort-range Interconnectと、隣接しないセグメント同士をつなぐLong-range Interconnectの2種類のインターコネクトが配されているのがまず目を引く。
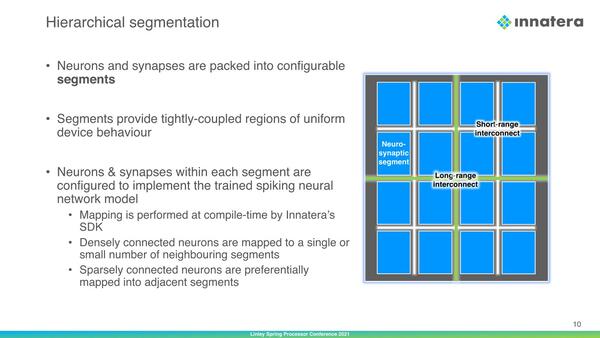
個々のセグメントになにをどう配置するかはコンパイル時に決まり、動的には変更できないとのこと

“conductance-based neurons”というあたりは、基本的な演算が抵抗を利用した電圧ベースだとは思うが、まさか抵抗でラダー回路を組むわけでもないだろうし、どんな技術をここに隠しているのか気になる
個々のセグメントの中には、複数のProgrammable Synapsesと呼ばれる計算エレメントが格子状に配されており、それぞれがスイッチでつながっている構成である。その個々のシナプスの中身が下の画像だ。
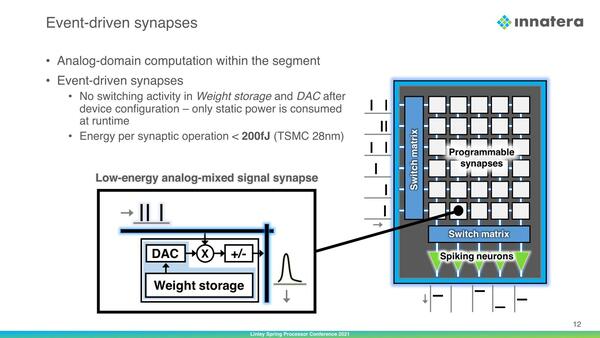
左の図で、ブルーの部分がデジタル、乗算器(とそのあとの符号変換)はアナログで実装とある
肝心の掛け算をどうやって実現しているのかはわからないが仕組みは以下の通りとなる。
- 入力のSpikeはアナログ値としてSynapseに到達する
- 重み(Weight)そのものはデジタル(SRAM?)で保持されるが、演算前にこれをDAC(Digital-Analog Converter)を使ってアナログ値に変換している。したがって演算処理そのものはアナログ的に行なわれることになる
具体的にどうやって、という話は現時点でまったく公開されていない。ただ少なくともトランジスタは一切使っていない(だからこそ稼働時には静的電力のみで、消費電力は演算あたり200fJ未満とされる)ようだ。ちなみにTSMCの28nmでの数字ではあるが、これは実測値ではなくTSMCの28nmプロセスの特性値からの推定と思われる。
同種のものとしてMythicのMatrix Multiplying Memoryが連想されるが、あちらはフラッシュメモリーを抵抗として使っているのに対し、こちらは少なくともフラッシュメモリーではないようだ。Standard CMOSプロセスで製造可能、と同社は説明しており、なにか別の原理で乗算をしているものと思われる。
この連載の記事
-
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 - この連載の一覧へ

















の1台が今ならオトク!")




























")













