ロードマップでわかる!当世プロセッサー事情 第588回
Ryzen 5000シリーズはなぜ高速なのか? 秘密はZen 3の内部構造にあり AMD CPUロードマップ
2020年11月09日 12時00分更新

このところAMDを取り上げる機会が異様に多いが、新製品投入ということもあるのでご容赦いただきたい。ということで今回はRyzen 5000シリーズの話だ。海外では11月5日の朝6時(太平洋時間)に解禁となったので、さっそくKTU氏による速攻レビューが掲載されているのでもうお読みの方も多いと思う。
そのRyzen 5000シリーズがなぜこんなに高速になったのか、というところでZen 3アーキテクチャーの内部構造の詳細が、この情報解禁に合わせてもう少し明らかになったので、これを解説する。言ってみれば連載584回の答え合わせである。
Zen 2とほぼ変わらない構成とプロセスのまま
IPCを20%近く向上させたZen 3
Zen 3の概要が下の画像だ。筆者の推定(ALU×5+AGU×3)はややハズレで、整数部はALU×4+AGU×3+BR(Branch Unit)という構成になった。
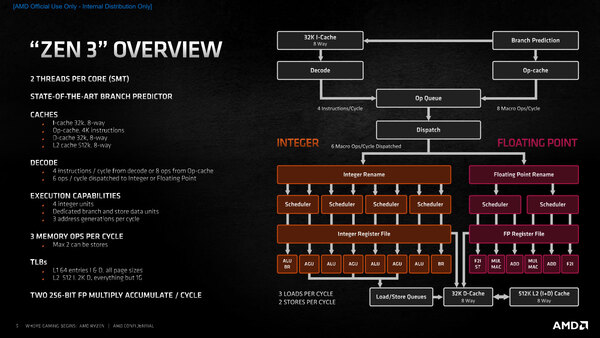
Zen 3の概要。ある意味先祖返り(K7→K8の変化)に近いものを感じる
ALUの1つはBRと共用なので、要するにBRが2つに強化された形になる。またFPUは6wayの非対称構成であった。Micro-Op Cacheの帯域が8、という点は同じながらデコードは引き続き4命令/サイクルであり、意外なほどにフロントエンドの拡張が「一見」行なわれていないように見える。
むしろ大きな違いは、バックエンドである。スケジューラーがALU+AGUを一つの塊として扱うように変更され、FPU側も2つに分離されている。下の画像の方がこのあたりの変化がわかりやすいかもしれない。大きなレベルで言えばZen 2とほとんど変わらない構成とプロセスのまま、20%近いIPC向上を獲得できたことになる。

Zen 2からの変更点。5命令/サイクルのデコードやALU×5以上のバックエンドを投入することで、まだ性能を引き上げられる余地が残っているという見方もできる
分岐予測の精度向上と高速化を果たした
フロントエンド
まずフロントエンド。基本的な構成は変わらないものの、分岐予測の高速化や命令キャッシュとOp-Cacheの切り替えの高速化、分岐ミスからのリカバリーの高速化、および分岐予測の精度向上が挙げられている。

フロントエンドの基本的な構成は変わらない。細かい所で言えば、Zen 2ではMicro-Op Queueから直接Integer RenamingにDispatchしているのが、Zen 3ではここにDispatcherが入ったのも違いとなる
このうちフェッチ/デコード段が下の画像だ。大きな違いはBTB(Branch Target Buffer:分岐先バッファ)の拡充である。

フェッチ/デコード段の概要。TAGEはZen 2からの採用となる
Zen 2世代の構造は連載516回の画像にあるが、L0 BTBを廃止してL1とL2のみにした。そしてL1 BTBを512エントリーから1Kエントリーに増やし、その代わりL2 BTBを7K→6.5Kに減らしている。
BTB全体としては(L0の16エントリーを除くと)トータル8Kエントリーで変わらないが、L1の比重を高めた格好だ。これが“Redistributed(再配置)”の意味合いかと思われる。
なぜこんな変更が行なわれたかと言えば、分岐予測のレイテンシーそのものを減らしたかったためだろう。L0を廃止することで直接L1にアクセスできるため、これだけで1~2サイクルの短縮になる。
またそもそもZen 3の設計目標が「特に規模の大きなプログラム、あるいは分岐の多いプログラムにおけるフェッチの高速化」というあたりで、L0は規模が小さい、あるいは分岐の少ないプログラムでは高速に分岐できるものの、規模が大きくなったりするとすぐ溢れてしまう(なにしろ16エントリーしかない)ため、結局L1 BTBを参照することになる。であればL0 BTBを廃し、その代わりL1 BTBを多少大きくした方が効率が上がると判断された模様だ。
また連載584回で触れたZero Bubble Branch Predictionであるが、Mike Clark氏の説明を聞く限りはBranch Predictionのレイテンシーを削減したことで、特にL1 BTBにHitする限りはLatency 0(=No bubble)で分岐処理が行なえる、という程度の意味のようだ。
さらに、デコード段からのMicro-Op供給とOp-cacheからの命令供給の切り替えも高速化されたとしている。これが“Faster sequencing of Op-cache fetches”に該当するのではないかと思われる。Op-cacheの容量そのものは4Kのままの据え置きになっている模様だ。
実はこれに関しては、今年10月に開催されたIEEE MICRO 2020で、AMDのJagadish B. Kotra氏(Researcher, Member of Technical Staff, AMD Research)が“Improving the Utilization of Micro-operation Caches in x86 Processors”という論文を発表している。
氏の論文はMicro-op Cacheの構造や容量をいろいろ変えながら、それが性能にどの程度のインパクトがあるかを論じたものだ。2Kをベースラインとして最大64Kまで容量を変化させながら性能を測定した結果、2K→4Kでは大幅な改善が見られるが、その後は容量を増やしていってもそれほど改善しないというもので、4Kにすると2Kの場合に比べて平均3.08%、最大11.27%の性能改善が見られたとしている。
構造についてはCLASP(Cache Line boundary AgnoStic uoP cache design:キャッシュラインサイズ非依存の構造)+Compaction(Micro-opの圧縮)を組み合わせた技法が有効だとしている。
ちなみにCompactionに関してはRAC(Replacement policy Aware Compaction)、PWAC(Prediction Window Aware Compaction)、F-PWAC(Forced Prediction Window Aware Compaction)の3つの技法を評価、それぞれ一長一短があるとしている。
このCLASP+Compactionによって、Op-Cacheのフェッチ効率やDispatch帯域、分岐ミスのペナルティー軽減やトータル性能向上、さらに消費電力低減にも効果があったとまとめている。これはあくまでMicro-Op Cacheの技法についての論文であり、実際の製品の紹介ではないのだが、Micro-Op Cacheの容量がZen 2から4Kのまま据え置きというのは、このあたりも関係しているものと思われる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 - この連載の一覧へ












