
先週に引き続き、AMDのNext Horizon Gamingイベントで公開された話を解説しよう。今回はCPU編である。
Zen 2ではIPCが15%改善
まずZen 2のコアアーキテクチャー全体で言えば、IPCが15%改善されているほか、3次キャッシュのサイズが2倍となり、またFPU性能も2倍になるとされる。

このFPU周りについては、連載484回でも触れている通り、FPUユニットがすべて256bit化された
この15%のIPC改善はどうやって実現されたかという話であるが、まず基本的な構造が下の画像だ。

Zen2の基本構造。Renaming Registerも168→180に増やされた。これはAGUが1つ増えたことに対応したものと思われる
Zen/Zen+の構造と比較すると、以下の違いが挙げられる。
- AGUが1つ追加された3つになった
- Micro-op Cacheの容量が4Kopに倍増した
- 分岐予測に、新たにTAGE(TAgged GEometric)を利用した方式が追加された
そしてバッファ周りでは、以下の違いが挙げられる。
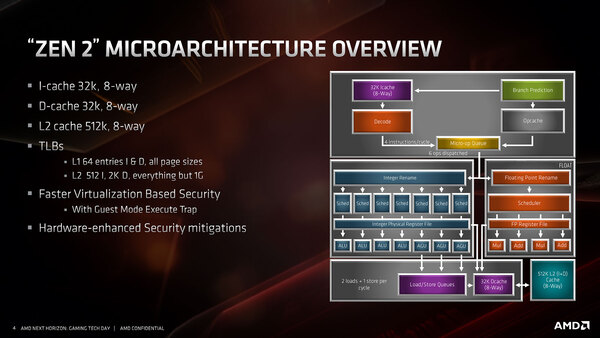
Zen2のバッファ周り。L1 I-Cacheに関してはサイズが半減したわけだが、Set Assosiativeが増えてヒット率を高めたうえ、Micro-Op Cacheが倍増しているので、実質的にはデメリットはほとんどないと思われる
- L1 I-Cacheが64KB/4wayから32KB/8wayに変更
- TLBの大容量化(後述)
- 仮想化マシンのセキュリティー周りの高速化
- 脆弱性対策のハードウェアベースでの強化
もう少し細かく見てみよう。まずはフェッチだが、BTBが大幅に強化されているのがわかる。もっともこれは上でも書いたが、従来のPerceptronベースの分岐予測に加えてTAGEベースの分岐予測も加わったことで、BTBのエントリーを増強しないと予測が収まりきらなかったものと思われる。他にITAのサイズを増やしたことも挙げられている。
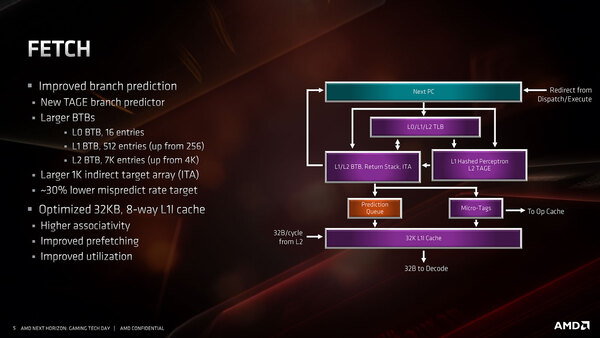
分岐ミスが減った理由はTAGEの追加と思われるが、PerceptronとTAGEの両方の分岐予測の結果をどう使い分けているのか興味あるところ
インストラクションキャッシュ(L1 I-Cache)については、そもそもデータキャッシュ(L1 D-Cache)がやはり32K 8-Wayだったわけで、64Kの4-Wayがどこまで有効なのか不思議ではあったのだが、やはり思ったほど有効ではなかったということだろう。
2次キャシュとは32Bytes/サイクルで接続されており、これはデコード段の読み込み速度にあわせたものと思われる。
デコード段については大きくは変わっていないが、先に書いた通りMicro-op Cacheが4Kopに増量されたほか、Op-Cacheから最大8 Fused-opが出力されるようになった。またInstruction Fusionがさらに改良されたとしている。これらの結果として、実効スループットの改善がなされたと思われる。
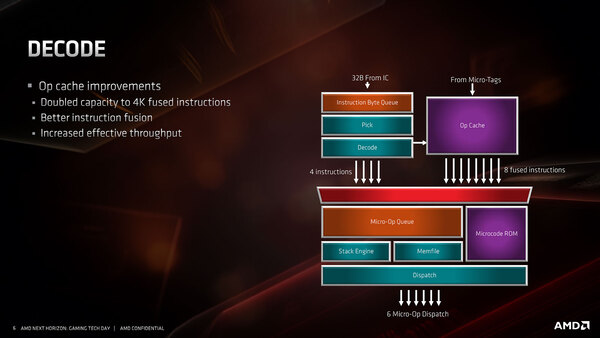
デコード段の構造。Fused instructionsというのは、インテルで言うところのMacro Opで、要は複数のx86命令(Load+addなど)を1つのMicro-Opにまとめる仕組みである
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ












