



ロードマップでわかる!当世プロセッサー事情 第566回
マルチメディア向けからAI向けに大変貌を遂げたMovidiusのMyriad 2 AIプロセッサーの昨今
2020年06月08日 12時00分更新

Myriad 2がDNN向けプロセッサーに大変身
そのMyriad 2だが、2年後の2016年に開催されたHot Chips 28では“Embedded Deep Neural Networks”向けチップとしてさらっと再登場した。最初に示されたのがこのスライドである。
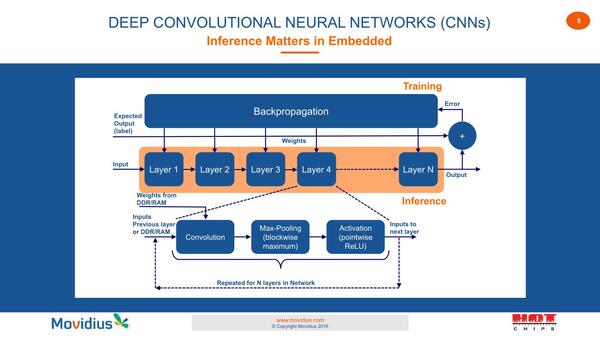
言ってることは連載562回で説明した畳み込みニューラルネットワークとほぼ同じ
もうこの時点で同社は学習(Training)ではなく推論(Inference)に明確にフォーカスしているのがわかる。
要するにBackpropergation(学習で利用されるパラメータ調整のための逆伝搬)は無視すると、推論は(乱暴に言えば)レイヤー単位で畳み込み→圧縮→有効化を行なうという話で、これはSHAVE的な実装に非常に適したものとなる。
もちろんいろいろ阻害要因はあり、この時点ではまだ一般論としてネットワークの層数が多ければ多いほど精度があがるが、結果としてネットワークそのものの規模が極端に大きくなっている。
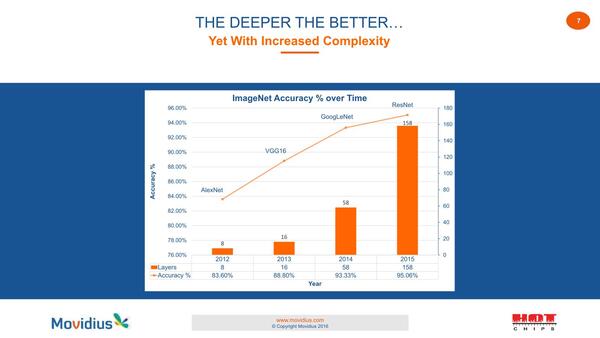
ネットワークの層数が多ければ多いほど精度があがる。このあたりは大分今では研究が進んでおり、Training→Inferenceに移行の際にネットワークの層数を減らす方法などもいろいろ出てきているが、2016年時点での発表なので仕方がない

2014年のGoogle Netですらパラメーターの数が500万個におよぶわけで、これをどうやって格納して処理させるかという問題もある
それでも、クラウド側で推論を実現するよりはエッジ側で推論を実現する方が効率が良く、レイテンシーも少ないとして、同社はエッジでの推論に最適化したソリューションを用意したとしている。
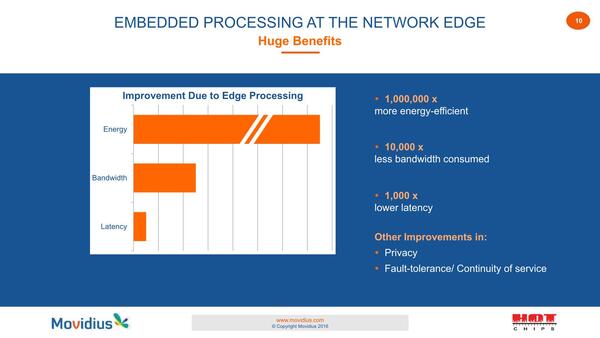
今ではこの辺の議論はすでに結論が出ている話であるが、当時はまだEdge AIという議論が始まったばかりであった
ということでMyrad 2が再び登場した。先ほどのMyriad 2の構成画像と見比べてみると、RTOSコアのL2/ROM容量が倍増した以外の違いがまったく見当たらない。実際画像処理ハードウェアまでそのまま搭載されており、要するにハードウェアを「ほぼ」そのまま持ってきた感じである。

再び登場したMyrad 2。圧縮(Max-Pooling)や有効化(Activation)向けの特別な処理ユニットは特に見当たらないが、時期を考えれば当然か。Power Islandが20以上になっているのにも注目。なので、まったく同じというわけでもないようだ
このSHAVEは、畳み込みなどにもちょうど都合の良い構造になっているというのがMovidiusの説明である。
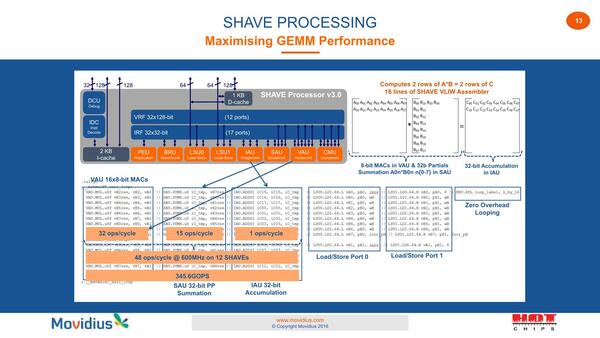
まずVAUで乗算を行ない、中間の加算をSAUで実施。最後の合計はIAUで行なうという仕組みだ。SHAVEはこの一連の処理を16命令で完了させる形(なので処理を開始してから最初の結果が出るまでのレイテンシーは16サイクル)であるが、処理のスループットは48Ops×12core×600MHz=345.6GOP/秒になる
畳み込みなども含めた行列演算一般をGEMM(General Matrix Multiply: 汎用行列乗算)と呼び、例えばインテルもGEMMをSSE/AVXを使って高速に処理するためのライブラリーとしてIntel MKL(Math Kernel Library)を提供しているが、MovidiusはもともとSHAVEがGEMMに向けた構成になってるとしており、1サイクルで48演算が可能で、600MHz駆動で345.6GOP/秒が実現できるとしている。
昨今では1TOP/秒以上を誇るプロセッサーも少なくなかったが、当時としてはかなり画期的な性能であった。もちろんこれはNVIDIAの、例えばKeplerベースのTesla K40(GK110搭載)の4300~5000GFlops(=4300~5000GOP/秒)に比べると1桁小さい性能ではあるが、Tesla K40がTDP 235Wなのに対してMyrad 2の消費電力は1.2Wに過ぎない。
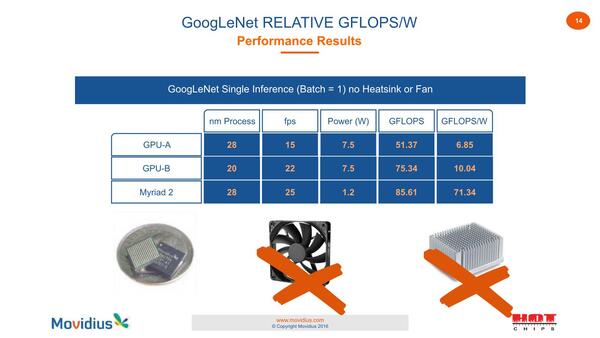
Myrad 2の消費電力は1.2Wにすぎない。しれっと「GFlops」表記になっているが、これはVAUを8bit Integerでなく16bit Floatで利用した場合の性能と思われる
性能そのものはGoogLeNet Batch=1の場合で25fpsと、GPUと比較しても遜色ない結果であり、おまけに1.2Wだからファンはおろかヒートシンクもなしで利用できることになる。
ただしソフトウェア的には、既存のフレームワークをそのままMyriad 2の上で動かすのは無理だったようで、Fathomと呼ばれる独自コンパイラを利用して、既存のフレームワークとネットワークを、Myriad 2に適した形に変換して実行する形になる。
インテルに買収されたMovidius
Edge AI向けNPUとして大成功を収める
さて2年かけてVision ProcessorをDNN向けプロセッサーに組み替えた(Vision Processorの上でDNNを走らせるためのソフトウェア環境を整えた)結果どうなったかというと、Hot Chips 28の翌月である2016年9月5日、インテルに買収された。
2017年にはこれをUSB Stickタイプの形にしたMovidius Neural Compute Stickが発売され、2018年にはチップを8倍高速なMyriad Xに置き換えたIntel Neural Compute Stick 2も発売される。
どうやって8倍を実現したのか詳細は明らかにされていないが、プロセスの微細化(TSMC 28HPM→TSMC 16FFC)とSHAVEコアの増量(12→16)に加え、内部の再設計(VAUやSAUのスループット向上?)や、必要のない映像処理ハードウェアの削除、メモリー搭載量強化などが実行されたものと思われる。
インテルによる買収ではしばしば悲惨なことになるケースを目にするが、Myriadに関して言えば現在もEdge AI向けNPUのメイン製品であり広く利用されている。
Computer Vision向けからAI向けへの看板の架け替えが成功した稀有な例という意味も含めて、見事に成功した例として良いだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















