



ロードマップでわかる!当世プロセッサー事情 第566回
マルチメディア向けからAI向けに大変貌を遂げたMovidiusのMyriad 2 AIプロセッサーの昨今
2020年06月08日 12時00分更新

Hot Chipsで初めて発表された
AIプロセッサー
この連載でも何度か取り上げているHot Chips。サブタイトルは“A Symposium on High Performance Chips”で、IEEE Technical Committee on Microprocessors and Microcomputersがメインスポンサーとなって毎年8月くらいに高性能プロセッサーに関するシンポジウムを開催している。
Hot Chipsの対になるのがCool Chipsで、こちらは“IEEE Symposium on Low-Power and High-Speed Chips and Systems”で、主に省電力プロセッサーに関するシンポジウムである。
どちらもIEEE(Institute of Electrical and Electronics Engineers:米国電気電子技術者協会)が主催するイベントであり、最新プロセッサーの発表の場の1つでもある(他にもISSCCでたまに取り上げることもあるほか、Linley Microprocessor Forumなどが最近は人気)。
さてそのHot ChipsでAIプロセッサーが初めて取り上げられたのは2015年のHot Chips 27である。ただこれは発表ではなく、モントリオール大のRoland Memisevic准教授による、“Deep Learning: Architectures, algorithms, applications”というタイトルの、午前中一杯を使ったチュートリアルのセッションである。
チュートリアルといっても参加するのは情報技術系の研究者とプロセッサー関係エンジニアということもあり、いきなりDeep Diveだったりするのだが、それはおいておく。なお、このセッションそのものはYouTubeで見られる。
その翌年、2016年のHot Chips 28では最初のAIプロセッサーの発表がいくつか行なわれた。今回紹介するのはその発表の1つであるMovidiusのMyriad 2である。
マルチメディアプロセッサーSHAVE爆誕
命令長が可変のキワモノ
Movidiusは2005年にサンマテオで創業した小さなベンチャーである。サンマテオは、当時はまだシリコンバレーとして理解されている範囲の北、と認知されていた場所で、サンフランシスコ国際空港のそばである。ちなみにほんの数マイル南下するとOracleの本社があり、これが当時はシリコンバレーの北限とされていた。昨今ではサンマテオもシリコンバレーに含まれている。
Movidiusの最初の数年間は、携帯機器向けの2D/3Dコントローラーや動画エンコーダー/デコーダーの類を出しているだけの、良くありがちなメーカーだった。

2011年2月の同社のProductsページ
ただそのMovidius、2011年のHot ChipsでSHAVE(Streaming Hybrid Architecture Vector Engine)と呼ばれる新しいマルチメディアプロセッサーを発表する。

マルチメディアプロセッサーのSHAVE。これだけで言えば単に「キワモノ」扱いなのだが……
どの辺がRISCとDSP、VLIWとGPUなのかという説明が下の画像だ。チップそのものは65nmプロセスで製造されている。先にVILW風という説明があったが、10種類の実行ユニットがあり、しかも命令長が可変という、デコーダーが死にそうな構成になっている。

RISC-styleとVILW-styleが矛盾しているが、実はこれは別のコアである。Streaming operationもGPU-styleというよりはDSP-styleな気がする
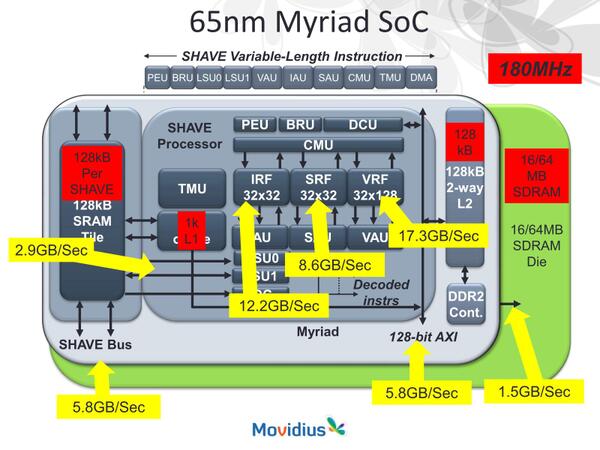
2011年と言えばもうDDR3 SDRAMがPCでは使われている時代だが、コストあるいは省電力性のために、あえてDDR2 SDRAMを採用していた模様(メモリーチップ自身の消費電力はDDR3の方が低くなるが、SoC内部の帯域を増やすとその分消費電力が増えるため)
この命令セットでInstruction Predication(次命令の予測)をどうやってやったのか、けっこう謎である。上の画像のSHAVEプロセッサーが1コア相当になり、システム全体では8コア構成として、それに周辺回路を組み合わせて1つのチップとなる形だ。
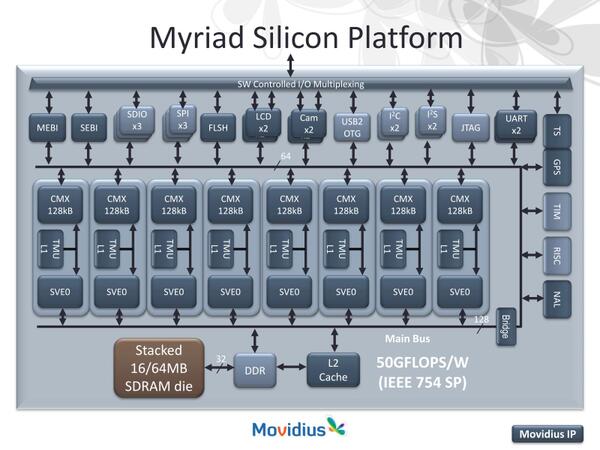
2次キャッシュは8コアのSHAVEコア共有で128KBなのだが、いくらなんでも少ない気がする
ダイサイズなどは発表されていないが、SoCは16MBのDDR2 SDRAMを積層する形で搭載され、FP32の場合で17.28GFlops/0.35Wとなり、効率は49.4GFlops/Wを達成したとしている。
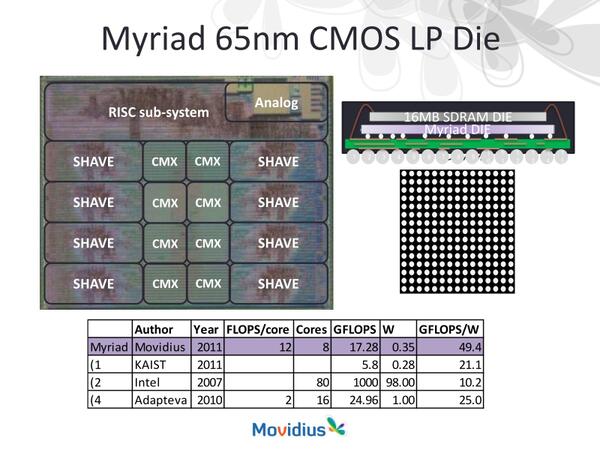
65nmプロセスではあるが、16MBのDDR2 SDRAMよりやや大きい程度だとすると、80平方mm程度だろうか?
アプリケーション的に言えば、RISCコアが各SHAVEコアに仕事を割り振ったり、周辺I/Oの制御などを行なったりして、アプリケーションそのものは各SHAVEコアがVILW/Vector的に処理を行なうというシナリオのようだ。
このSHAVEコアを利用することで、さまざまなアプリケーションが動作可能になるというのが同社の説明である。例えば1080iのH.264のデコードだけなら3コアで行けるし、動画キャプチャ→H.264のデコード→エフェクト追加まででも8コアで足りる、という具合だ。

コアごとに処理を分割することで、さまざまなアプリケーションを効率よく動かせる、という図式はメニーコアのSoCではありがちな図式ではある
ちなみにMovidiusは、これを28nmに移行させコア数を倍にし、効率を10倍に引き上げたFragrakプラットフォームの構想も2011年に発表している。プロセス微細化にともないCMX(128KBのSRAM Tile:おそらくTCM的な使い方を想定していると思われる)の容量も倍増、L2も512KBまで増やしている。
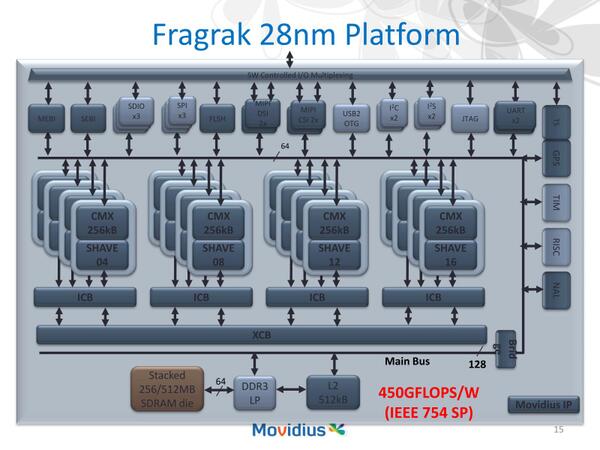
Fragrakプラットフォームの構想。28nmくらいまではまだプロセスを微細化すれば消費電力が減り、動作周波数がなんとか上がるぎりぎりの所ではあったから、動作周波数をむやみに上げなければ450GFlops/Wは現実的な数字だろう
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 - この連載の一覧へ














&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")


















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












