




Haswellと同等のIPCを持つCHA
ベースになるCHAは下の画像のような構成である。今回x86コアに関しての説明は、ほぼこのスライドで終了であるが、Haswellと同等のIPCを持ち、2.5GHz駆動の8コア+16MB L2が、ちょうどインテルのCore同様にDual Ring Busでつながっている構成である。

CHAの構成。リング右下に出ているのが、プロセッサー拡張用のI/Fと思われる。KX-6000シリーズの場合はL3なし(L2が8MB)で、SSE 4.2/AVXまでのサポートでAVX512の対応はなかった
異なるのは、PCI Expressが44レーンあることと、DDR4が4ch構成になっていること、それとマルチソケット対応(要するに2ソケット対応)が可能なことだ。
前モデルと思われるZhaoxinのKX-6000に比べると、同じ16nmプロセスを使いながら動作周波数が2.5GHzとやや控えめになっているが、これは続くNcoreを搭載する関係もあると思われる。NcoreはこのRing Busにぶら下がる形で実装される。
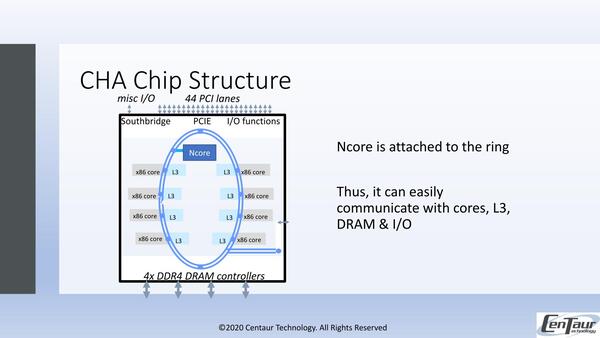
構図としては、Core iシリーズでGPUがぶら下がるのと同じような形である。これにより、メモリーコントローラや3次キャッシュが共用できる
下の画像がダイレイアウトである。CHAの元になったKX-6000では、そもそもL3がないし、DDR4も2ch、PCI Expressも16レーンのみということで、ダイサイズもかなり小さく抑えること(ラフに言えば半分強)が可能だった。
しかし、CHAではまずDDR4を倍増、PCI Expressも44レーンまで増やしたことで、これらのピンを出すために必要なダイサイズが大幅に増えることになった。

KX-6000はDirectX 11対応のGPUを統合しており、CHAではこれを省いているため、大サイズは半分よりは多いはずだ。こうしてみるとKX-6000→CHAは、Skylake→Skylake-SPのような変更に思える
おそらくはDDR4を4chにした時点で、下辺のサイズが倍増。これにあわせて上辺のPCI Expressも増やしたら44レーン分取れることになった、ということだろう。この結果としてL3を16MB分確保してもまだダイサイズにゆとりができたので、そこにNcoreを統合した格好だ。
NcoreはCPUから見ると、PCI Expressの先につながるアクセラレーターとして見える形をとる。
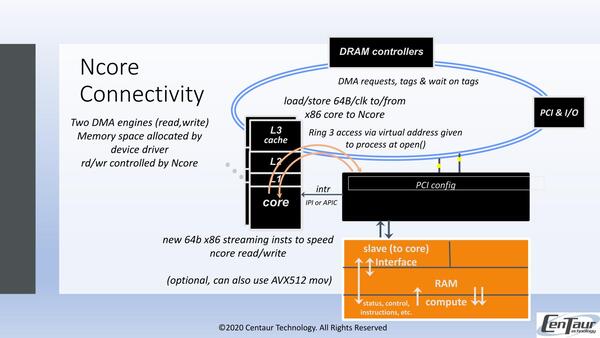
AMDのHSAのようにキャッシュコヒーレンシを取るつもりはまるでなく、DMAによるリード/ライトでメモリーの転送を行ない、CPUコアからはRing 3(非特権モード)でOpen()によりアクセスできるというあたり、完全にPCI/PCI Expressのブロックデバイスの扱いである
データ転送はNcoreに対しての読み書きを可能にする独自命令を追加するほか、AVX512のMov命令を利用することも可能、という格好である。
ここでいにしえのWeitekや、昨今のARMのDynamiQでサポートされるACPのようなレジスター経由アクセスを使わなかったのは、Inferenceの処理でもデータ量が多いので、レジスターへのPIOを多用するとむしろオーバーヘッドが大きくなることを懸念したものと思われる。
Ncoreそのものの構造は、主にDSPなどをベースにしたAI向けアクセラレーターでよく利用される、MACユニットを集約して高速でぶん回す方式はむしろ不効率と判断した。

Ncoreの構造。すでにDSPコアがあればそれを活用することも考えられるのだろうが、Centaurはそうしたものは特になく、むしろSSEやAVXの実装でSIMDの知見を蓄えているので、SIMD方式を選ぶことそのものは妥当だろう
そこでSIMDエンジンをベースとした構成になるわけだが、それがなんとAVX-32768相当、という化け物に仕上がっている。
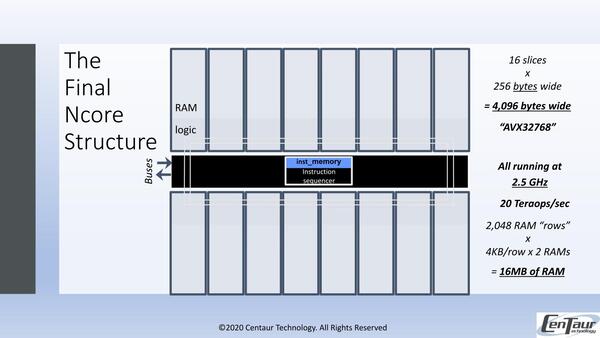
ベクトル演算はAVX32768に相当する(インテルの64倍)。RAMとLogicを混載させることで、演算時のレイテンシーを最小に抑えるのは妥当な方式だとは思うが……
全体が16個のスライスに分かれており、それぞれのスライスが256Bytes(2048bit)幅のSIMD演算が可能である。結果、1サイクルで4096Bytes分のSIMD処理が可能という、ARMのSVEもびっくりの実装となった。
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ














で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")









































