




16個のスライスに分割した
巨大な32768bit幅のSIMD
各々のスライス構造を示したのが下の画像である。
物理的には16個のスライスに分かれているものの、処理そのものは16個のスライスが同期して動く形になるので、本当に巨大な32768bit幅のSIMDなわけだ
Ncoreのワークフロー
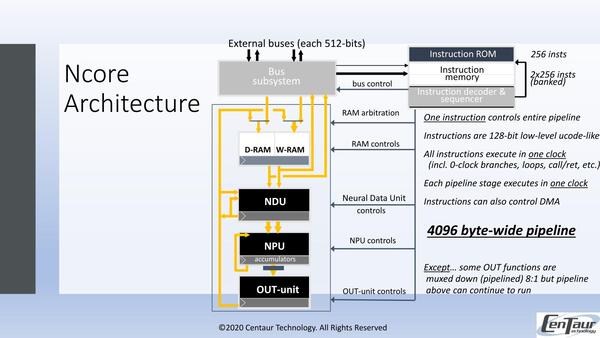
(0) Bus Subsystem経由でD-RAM(Data RAM)とW-RAM(Weight RAM:ネットワークの重みを格納する領域)にデータが格納される(これは処理パイプラインの外)
(1) NDU(Neural Data Unit)が4096Bytes分のデータとWeightを読み込み、これの並べ替えや回転、Edge Swap、あるいは前サイクルで処理の終わった出力画像の取り込みといった処理を1サイクルで実行する。
(2) NPU(Neural Processing Unit)で処理する。処理はMAC(乗加算)と加減算、最大/最小、論理命令その他をサポート。9bit/16bit整数とBFloat16が取り扱える。9bit整数ならMACが1サイクル、BFloat16でも3サイクルで処理できる。ちなみにデータ型そのものは8/16bit整数とBFloat16で、8bit整数は内部で9bit化して処理される。ここでWeightのデータを基に、データをネットワーク構造にあわせて処理する。
(3) OUT-unitでは、NPUの結果の量子化やReLU(ランプ関数)/Tanh/シグモイド関数を利用した活性化、出力の正規化などが行なわれ、結果がD-RAMないしNDUに引き渡される。ほとんどの処理は1~3サイクルで完了するが、例えば8:1の重ね合わせなどは最悪値で10サイクルほど要する
ここで1回分のデータ(例えば映像処理なら1フレーム分の画像データ)が完了するまで(1)~(3)をパイプライン式に繰り返し、終わったら(0)に戻る、という形である。
一方制御命令であるが、128bit幅のもので、これを見ると限りなくVLIWに似ている。ただし詳細は未公開である。

制御命令は128bit幅だが詳細は不明。きっと以前と同様、秘密保持契約を結ぶと開示されるのであろう
このあたりは昔のVIA C3などで提供されてきた独自拡張命令に近い感じに見える。ただ必要なツールやスタックはCentaurから提供されるので、直接アプリケーションプログラマーがこれを触る必要はない、としている。
さてNcore、構造そのものはシンプルながら、なにしろ32Kbit幅のデータパスであるから、それなりに実装は困難だったらしい。

これを2.5GHzで動かすのも確かに大変。そこらのAIアクセラレーターよりはるかに難易度の高い構成になってるのは気のせいだろうか?
下の画像がNcoreのうちでロジック部のアップである。この部分だけで11mm2というのは、性能を考えるとかなり小さい方である。

ロジック部のアップ。実際には、NCORE COMPUTEの倍近い面積を必要とするNCORE RAMも必要になるので、実質的なエリアサイズは30平方mm超と思われる
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第886回
PC
CFETの足を引っ張るPMOSを救え! imecが提案する新絶縁層と、あえて精度を緩める「Notch Alignment」の妙手 -
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 - この連載の一覧へ












ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")








ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












