




ハッシュサイズを増やすと
安全性が増すが処理が重くなる
このあたりまでが仕組みの説明だが、もう少しだけ細かい話をしておきたい。ハッシュ関数にどんなものを使うかは自由だが、たとえばビットコインの場合は、結果が32bitの値になるものが使われている。
32bitということは、およそ43億通りということで一見無尽蔵に使えそうに見えるが、地球上の人口は74億人ほど(2016年)なので、仮にデータにそれぞれの名前を格納すると明らか43臆を超えるわけで、つまり異なるデータであっても同じハッシュの値になるケースが出てくる。
これはハッシュの衝突と呼ぶが、衝突が多くなるとハッシュ関数の信頼性が揺らぐことになる。ただ衝突を起きにくくするためには、だいたいにおいてハッシュのサイズを大きくすること(32bitではなく64/128bitにするなど)が必要になるが、こうした大きなサイズのハッシュの計算にはけっこうな処理能力が必要になり、処理が重くなるという欠点もある。
またデータとハッシュの両方をネットワーク経由で分散保持するので、ハッシュのサイズが大きくなるとネットワークの負荷も増えることになる。このあたりを勘案して、必要なハッシュのサイズを決めることになる。
同じタイミングで新規ブロックを
追加した場合は1つに統合する
また先の例ではレシートにたとえたので、新しいブロックはレジで新しい買い物が発生した際に生成されることになるが、これでは買い物が発生しないと、ずっとブロックに変更がないことになる。そこで、ビットコインでは一定時間ごとに新規ブロックを追加するようにしている。
先の例では0円の買い物レシートが追加されることになるが、幸いに買い物は0円でもレシートに記された日時は変化するため、ハッシュの値は当然変化する。こうして常にブロックを長くすることで、改竄をさらに困難にするわけだ。
またネットワーク越しにすべてのユーザーがブロックを変更できるということは、たまたま同じタイミングで異なるユーザーが新規ブロックを追加することがありえる。たとえば12時にイッペイ氏がCPUをA店で、12時1分にハッチ氏がGPUをB店で、同じく12時1分にショータ氏がC店でメモリーを買ったとする。この場合の流れをまとめたのが下図である。
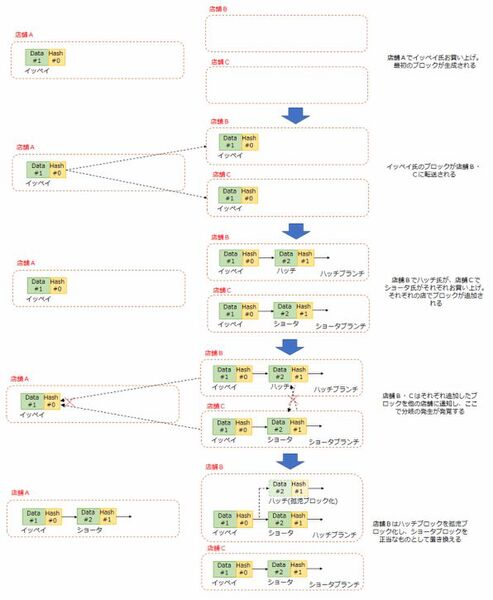
たまたま同じタイミングで2つの新規ブロックが追加された場合の処理
A店でまずイッペイブロックができたあと、B店とC店でそれぞれ同時に、イッペイブロックの後ろにハッチブロックとショータブロックを持つ2つの分岐(ブランチ)ができることになる。
B店とC店はそれぞれお金を受け取ってこのブランチを作ったあとで、P2Pでその結果を他のノード(ハッチブランチなら店舗AとC、ショータブランチなら店舗AとB)に送り出す。この時点で初めて、ノードの分岐が発生したことがわかるわけだ。
この分岐が発生したらどうするかというと、ハッシュ値に基づく多数決方式でどちらの分岐が「正当」なのかを決める。ここで「正当」というのは、正しい取引をしたかとか、お釣りをちょろまかしたから不正だという話ではなく、単にどちらの流れをすべてのノードで共有するかを決めるだけの話である。
仮に多数決でショータブロックが正当と決まった場合、ハッチブロックは孤児ブロックという扱いになる。店舗で言えば「あれ? カード決済がうまく通らなかったので、もう一度やりますね」といったあたりだ。
この場合、ハッチ氏の決済が一度やり直され、ショータブロックの後にハッチブロックがつながることになる。店舗Bでは引き続き孤児ブロックと化したもともとのハッチ氏のブロックを保持することはできるが、それはもはや他の店舗には通知されない。
説明が長くなったが、ブロックをつなげる(チェイニングする)ということで、ブロックチェーンという名前になっているわけだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ












の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















