
テキスト解析用のio.Reader関連機能
バイナリ解析の次はテキスト解析です。 バイナリ解析の場合は、読み込むバイト数が固定であったり、可変長データの場合も読み込むバイト数や個数などが事前に明示されていることがほとんどです。 一方、テキスト解析ではデータ長が決まらず、スキャンしながら区切りを探すしかありません。 そのため、探索しながら読み込んでいく必要があります。
改行/単語で区切る
テキスト解析の基本は改行区切りです。 全部読み込んでしまってから文字列処理で改行に分割する、という方法もありますが、 io.Reader による入力では bufio.Reader を使うという手があり、そちらのほうが比較的シンプルです。 ReadString()、ReadBytes() を使うと、任意の文字で分割することもできます。
package main
import (
"bufio"
"fmt"
"strings"
)
var source = `1行目
2行目
3行目`
func main() {
reader := bufio.NewReader(strings.NewReader(source))
for {
line, err := reader.ReadString('\n')
fmt.Printf("%#v\n", line)
break
}
}
}bufio.Reader は読み込んだ文字を戻すこともできるため、テキストの構文解析器を自前で作る際のベースにすることができます。
終端を気にせずにもっと短く書きたいのでれば、 bufio.Scanner を使う方法もあります。 これを使うと、上記のコードの main() 関数がこんなに短く書けます。
func main() {
scanner := bufio.NewScanner(strings.NewReader(source))
for scanner.Scan() {
fmt.Printf("%#v\n", scanner.Text())
}
}ただし、 bufio.Reader の結果の行の末尾には改行記号が残っていますが、こちらの結果では分割文字が削除されている点には注意が必要です。
bufio.Scanner のデフォルトは改行区切りですが、分割関数を指定することで任意の分割が行えます。 次の設定を行うと単語区切りになります。
// 分割処理を単語区切りに設定
scanner.Split(bufio.ScanWords)データ型を指定して解析
io.Reader から読み込んだデータは、今のところ単なるバイト列か文字列としてしか扱っていませんでした。 io.Reader のデータを整数や浮動少数点数に変換するには、 fmt.Fscan を使います。 1つめの引数に io.Reader を渡し、それ以降に変数のポインタを渡すと、その変数にデータが書き込まれます。
fmt.Fscan はデータがスペース区切りであることを前提としています。 fmt.Fscanln は改行区切り時に使います。
package main
import (
"fmt"
"strings"
)
var source = "123 1.234 1.0e4 test"
func main() {
reader := strings.NewReader(source)
var i int
var f, g float64
var s string
fmt.Fscan(reader, &i, &f, &g, &s)
fmt.Printf("i=%#v f=%#v g=%#v s=%#v\n", i, f, g, s)
}fmt.Fscanf を使うと任意のデータ区切りをフォーマット文字列として指定できます。 たとえば次のようにすれば「カンマ+スペース」で区切られているデータを読み込みます。
fmt.Fscanf(reader, "%v, %v, %v, %v", &i, &f, &g, &s)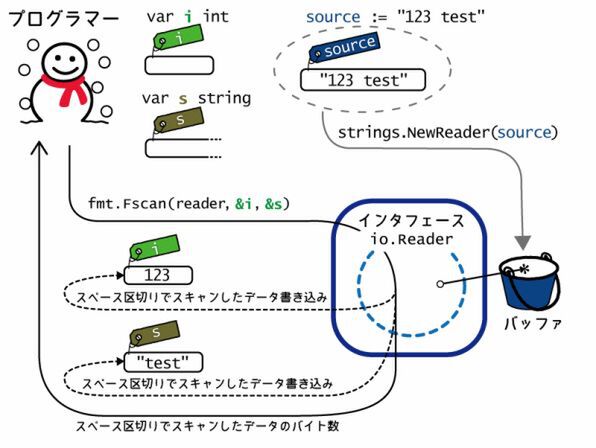
似た名前のC言語の関数をご存知の方もいると思いますが、Go言語は型情報をデータが持っているため、すべて「%v」と書いておけば変数の型を読み取って変換してくれます。
その他の形式の決まったフォーマットの文字列の解析
encoding パッケージの傘下にある機能を使えば、さまざまな形式のテキストを扱えます。
CSVファイルのパースは次のように行えます。サンプルデータは、みんな大好きKEN_ALL.csvから一部抜粋してきたものです 4。
package main
import (
"encoding/csv"
"fmt"
"io"
"strings"
)
var csvSource = `13101,"100 ","1000003","トウキョウト","チヨダク","ヒトツバシ(1チョウメ)","東京都","千代田区","一ツ橋(1丁目)",1,0,1,0,0,0
13101,"101 ","1010003","トウキョウト","チヨダク","ヒトツバシ(2チョウメ)","東京都","千代田区","一ツ橋(2丁目)",1,0,1,0,0,0
13101,"100 ","1000012","トウキョウト","チヨダク","ヒビヤコウエン","東京都","千代田区","日比谷公園",0,0,0,0,0,0
13101,"102 ","1020093","トウキョウト","チヨダク","ヒラカワチョウ","東京都","千代田区","平河町",0,0,1,0,0,0
13101,"102 ","1020071","トウキョウト","チヨダク","フジミ","東京都","千代田区","富士見",0,0,1,0,0,0
`
func main() {
reader := strings.NewReader(csvSource)
csvReader := csv.NewReader(reader)
for {
line, err := csvReader.Read()
if err == io.EOF {
break
}
fmt.Println(line[2], line[6:9])
}
}csv.Reader は io.Reader を受け取ります。 Read() メソッドを呼ぶと、行の情報(文字列の配列)を返します。 ReadAll() で、それがさらに配列になったものを一度に返すこともできます。
encoding/json はウェブのAPIのアクセスではよく使うでしょう。 これも io.Reader 、 io.Writer とのインタフェースになっています。 encoding/json はさまざまな使い方ができる複雑なライブラリですので、本連載の1セクションで書ききれる分量では紹介しきれません。 興味のある方は他のサイトを検索してみるなどしてください。
注釈
ストリームを自由に操るio.Reader/io.Writer
C++やJava、Node.jsでは、各言語で定義されたインタフェースを使ったデータ入出力の機構を「ストリーム」と呼んでいます。 Go言語ではストリームという言い方はしませんが、 io.Reader と io.Writer をデータが流れるパイプとして使うことができます。 データの流れを自由に制御するために使える構造体を5種類紹介します。
io.MultiReaderio.TeeReaderio.LimitReaderio.SectionReaderio.Pipe(io.PipeReaderとio.PipeWriter)
まずは io.MultiReader です。 引数で渡された io.Reader のすべての入力が繋がっているかのように動作します。
package main
import (
"bytes"
"io"
"os"
)
func main() {
header := bytes.NewBufferString("----- HEADER -----\n")
content := bytes.NewBufferString("Example of io.MultiReader\n")
footer := bytes.NewBufferString("----- FOOTER -----\n")
reader := io.MultiReader(header, content, footer)
// すべてのreaderをつなげた出力が表示
io.Copy(os.Stdout, reader)
}io.TeeReader は、読み込まれた内容を別の io.Writer に書き出します。 前回紹介した io.MultiWriter は書き込まれた内容を書き出していましたが、それと似ています。
package main
import (
"bytes"
"fmt"
"io"
"io/ioutil"
)
func main() {
var buffer bytes.Buffer
reader := bytes.NewBufferString("Example of io.TeeReader\n")
teeReader := io.TeeReader(reader, &buffer)
// データを読み捨てる
_, _ = ioutil.ReadAll(teeReader)
// けどバッファに残ってる
fmt.Println(buffer.String())
}このサンプルでは io.TeeReader から読み込んだ内容はすべて捨てていますが、 Reader が読み込んだ内容をバッファにも入れていたので、バッファから同じ内容を取り出すことができました。
最後に紹介するのが io.Pipe です。 io.Pipe を使うと、 io.PipeReader と io.PipeWriter のペアが得られます。 Writer に書き込んだものは、 Reader から出力されます。
ただし、Go言語のパイプにはバッファがないため、読み込み側の Read() が先に呼ばれると、誰かが Write() を呼ぶまでブロックします。 逆に、先に Write() が呼ばれると、誰かが Read() を呼ぶまでブロックします。
Go言語では、チャネルを使った並列処理でもこのような完全同期の通信が発生します。 シングルスレッド/プロセスでは必ず io.Pipe 操作がブロックしてプログラムがデッドロックします。 書き込み側、あるいは読み込み側のどちらかを並列化するには、次のように関数呼び出しの前に go を付与してゴルーチンによる並行処理にします。
go io.Copy(pipe, reader)ストリームを組み立てる道具として、これまで紹介してきた関数や構造体をモデル図にしてみました。 丸いコネクタが io.Reader の送受信、三角形のコネクタが io.Writer の送受信を表しています。 データはすべて左から右に流れます。
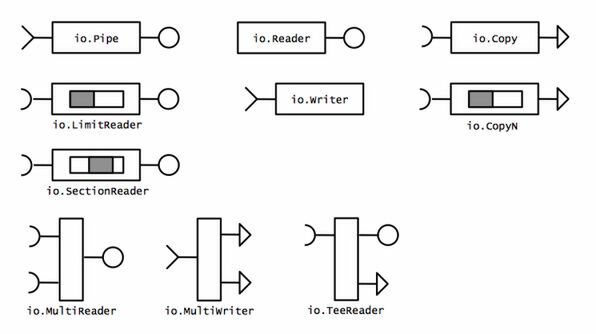
io.Copy は io.Reader から io.Writer への変換、 io.Pipe はその逆変換になっていることがわかります。 これらを駆使すれば、自由自在に組み合わせられるようになるでしょう。
クイズ
CopyN
io.Copy と今回紹介した構造体のどれかを使って、前回紹介した io.CopyN(dest io.Writer, src io.Reader, length int) を実装してみてください。
ストリーム総集編
これまで紹介してきた構造体や関数を組み合わせて、ちょっとしたパズルを組み立ててみましょう。
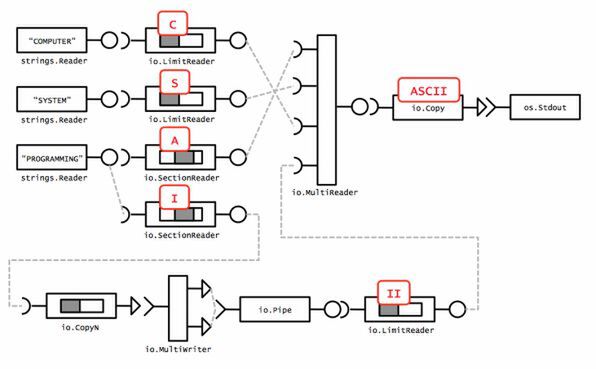
COMPUTERSYSTEMPROGRAMMING
これらの文字列を3つの入力ストリーム(io.Reader)とし、次に示す main() 関数のコメント部にコードを追加して、最後の io.Copy で「ASCII」という文字列が出力されるようにしてみてください。
package main
import (
"strings"
"io"
"os"
)
var (
computer = strings.NewReader("COMPUTER")
system = strings.NewReader("SYSTEM")
programming = strings.NewReader("PROGRAMMING")
)
func main() {
var stream io.Reader
// ここにioパッケージ何か書く
io.Copy(os.Stdout, stream)
}ただし次の制約を守ってください。
- 使っていいのはioパッケージの内容+基本文法のみです。
io.Pipeを使う場合はブロッキングを防ぐためにゴルーチンを使ってください。 - 文字列リテラルは使用してはいけません。
- コメント部以外を変更してはいけません。当然、
importするパッケージを増やしてはいけません。
回答は次回予告の後にあります。
今回のまとめと次回予告
前回と今回はio.Reader について2回に分けて紹介しました。 サイズやデータの種類を推定しながら読み込んだり、セクションごとに読み込み処理を切り替えたり、可変長データを少ないメモリでうまく読み込む必要があったり、知っておくべきメソッドの数は読み込みに関するもののほうが多いのです。 そのため、読み込みについては補助関数の機能や種類も豊富です。 これだけさまざまなパッケージを紹介するのは、 Reader まわりが最初で最後になるはずです。
第2回から第4回までの3回の記事を通じてGo言語の入出力まわりの低レベルインタフェースを広く説明してきましたが、 RubyやPythonのようなサービス精神旺盛なオブジェクト指向のスクリプト言語に慣れている人のなかには、 io.Writer、io.Readerという余計な情報を理解しないと入出力を使いこなせないGo言語にとっつきにくさを感じている人もいるかもしれません。 RubyやPythonではファイルを表すオブジェクトが豊富なメソッドを提供しているため、その気持ちは理解できます。
ただ裏を返せば、この部分がわかれば低レベルな層との付き合いが格段に楽になるということでもあります。 以降の記事では、ここで紹介した機能をいろいろ使って、ソケットなどの低レベルな入出力も扱っていきます。 でもその前に、次回は第1回の記事でチラ見したOSとアプリケーションの境界線であるシステムコールを再訪しましょう。
パズルの答え
io.SectionReader と io.LimitReader を使えば必要な文字を切り出せます。 これで5文字揃えても問題ありません。 次のコードでは「I」を MultiWriter を使って増やしています。パイプを作って、同じパイプに2回書くことで、2文字にしています。
package main
import (
"strings"
"io"
"os"
)
var (
computer = strings.NewReader("COMPUTER")
system = strings.NewReader("SYSTEM")
programming = strings.NewReader("PROGRAMMING")
)
func main() {
var stream io.Reader
a := io.NewSectionReader(programming, 5, 1)
s := io.LimitReader(system, 1)
c := io.LimitReader(computer, 1)
i := io.NewSectionReader(programming, 8, 1)
pr, pw := io.Pipe()
writer := io.MultiWriter(pw, pw)
go io.CopyN(writer, i, 1)
defer pw.Close()
stream = io.MultiReader(a, s, c, io.LimitReader(pr, 2))
io.Copy(os.Stdout, stream)
}先程紹介したモデル図を使うとこの答えは次のように表現できます。 io.Pipe のブロッキングを回避するために、入力側では io.CopyN で、出力側では io.LimitReader を使ってそれぞれ文字数を明示している点が難しいポイントだと思います。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第20回
プログラミング+
Go言語とコンテナ -
第19回
プログラミング+
Go言語のメモリ管理 -
第18回
プログラミング+
Go言語と並列処理(3) -
第17回
プログラミング+
Go言語と並列処理(2) -
第16回
プログラミング+
Go言語と並列処理 -
第15回
プログラミング+
Go言語で知るプロセス(3) -
第14回
プログラミング+
Go言語で知るプロセス(2) -
第13回
プログラミング+
Go言語で知るプロセス(1) -
第12回
プログラミング+
ファイルシステムと、その上のGo言語の関数たち(3) -
第11回
プログラミング+
ファイルシステムと、その上のGo言語の関数たち(2) -
第10回
プログラミング+
ファイルシステムと、その上のGo言語の関数たち(1) - この連載の一覧へ



の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")










