
Go言語の特徴として挙げられる機能の1つに、「並列処理を書くのが簡単」というものがあります。 そこで今回は、Goにおける並列処理の機能を紹介してから、そもそも現代のコンピューターでどのようにして並列処理が実現されているのかをとりあげます。
複数の仕事を同時に行うとは?
複数の仕事を行うことを表す言葉には並行と並列の2つがありますが、これらには次のような区別があります。
並行処理(Concurrent)
- 並行(Concurrent): CPU数・コア数の限界を超えて複数の仕事を同時に行うこと
ほんの少し前まで、コンピューターに搭載されているCPUはコア数が1つしかないものが普通でした。 そのような、今ではもう絶滅危惧種になりつつあるシングルコアのコンピューターであっても、インターネットを見ながらWordとExcelを立ち上げてレポートを書けます。 この場合に大事になるのが並行(Concurrent)です。
シングルコアで並行処理をする場合、トータルでのスループットは変わりません。 スループットが変わらないのに並行処理が必要なのは、とりかかっている1つの仕事でプログラム全体がブロックされてしまうのを防ぐためです。
並列処理(Parallel)
- 並列(Parallel): 複数のCPU、コアを効率よく扱って計算速度を上げること
並列は、CPUのコアが複数あるコンピューターで、効率よく計算処理を行うときに必要な概念です。 例えば8コアのCPUが8つ同時に100%稼働すると、トータルのスループットが8倍になります。
現在は、マルチコアのコンピューターとマルチコアが扱えるOSが当たり前となっていることもあって、いかに並列処理を実現するかという点が焦点になっています。 並列処理のプログラムは並行処理のプログラムに内包されるため、並列処理についてだけ考えれば並行処理はおおむね達成できるともいえます。
どちらが大切?
並列は並行に内包されていると紹介しましたが、実装時に並列だけを考えればいいというわけでもありません。 CPUコア数が8コアあっても、たとえばウェブサービスが同時8アクセスだけで止まってしまっては、8コアのハードウェアに見合った性能が出せているとは言えません。
タスクによっては、並列と並行を両方とも考慮することで、はじめて効率を最大化できます。 CPUにおける処理時間が大きい場合(ユーザー時間が支配的な場合)は並列、I/O待ちなどでCPUがひまをしているときは並行で処理するというのが基本です。
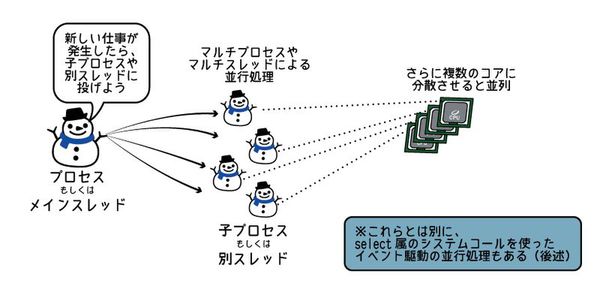
Go言語の並列処理のための道具
Go言語には並列処理を簡単に書くための道具が備わっています。 Go言語で並列処理を書くための道具には次のようなものがあります。
- goroutine
- チャネル
- select
今回のサンプルでは、待ち合わせにtime.Sleepを使っている箇所がいくつかあります。 これは説明のためであり、本来はチャネルやsync.WaitGroupなどの「作業が完了した」ことをきちんと取り扱える仕組みを使って待ち合わせ処理を書くほうが望ましいでしょう。 さもないと、忘れた頃にコード改変でなぜか動かなくなって悩むことになったり、必要以上に待ちが発生してユニットテストの所要時間が無駄に伸びたりしてしまいます。
goroutine
goroutine(ゴルーチン)は、Go言語のプログラムで並行に実行されるもののことです。 構文としては、次のように、goを付けて関数呼び出しを行うだけです。
package main
import (
"fmt"
"time"
)
// 新しく作られるgoroutineが呼ぶ関数
func sub() {
fmt.Println("sub() is running")
time.Sleep(time.Second)
fmt.Println("sub() is finished")
}
func main() {
fmt.Println("start sub()")
// goroutineを作って関数を実行
go sub()
time.Sleep(2 * time.Second)
}上記の例では、関数を定義してから、その関数をgoで呼び出しています。 しかし、Go言語では無名関数(クロージャ)が作れるので、次のように関数の作成とgoroutine化を同時に行うことができます。 この場合はgoの後ろには関数名ではなく「関数呼び出し文」がくるので、末尾に「()」が必要です。 メソッド呼び出しも使えます。
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("start sub()")
// インラインで無名関数を作ってその場でgoroutineで実行
go func() {
fmt.Println("sub() is running")
time.Sleep(time.Second)
fmt.Println("sub() is finished")
}()
time.Sleep(2 * time.Second)
}goroutineと情報共有
goroutineで協調動作をするには、goroutineを実行する親スレッドと子の間でデータのやりとりが必要です。 このデータのやりとりには、関数の引数として渡す方法と、クロージャのローカル変数にキャプチャして渡す方法の2通りのやり方があります1 。
package main
import (
"fmt"
"time"
)
func sub1(c int) {
fmt.Println("share by arguments:", c*c)
}
func main() {
// 引数渡し
go sub1(10)
// クロージャのキャプチャ渡し
c := 20
go func() {
fmt.Println("share by capture", c*c)
}()
time.Sleep(time.Second)
}クロージャのキャプチャ渡しの場合、内部的には、無名関数に暗黙の引数が追加され、その暗黙の引数にデータや参照(変数は参照扱い)が渡されてgoroutineとして扱われます。そのため、この例のケースでは、結果としては「引数で渡す」のと同じです2。 気になる方はアセンブリコードを出力して確認してみてください。
関数の引数として渡す方法と、クロージャのローカル変数にキャプチャして渡す方法とのあいだで、1つ違いがあるとすれば、次のようにforループ内でgoroutineを起動する場合です。
package main
import (
"fmt"
"time"
)
func main() {
tasks := []string{
"cmake ..",
"cmake . --build Release",
"cpack",
}
for _, task := range tasks {
go func() {
// goroutineが起動するときにはループが回りきって
// 全部のtaskが最後のタスクになってしまう
fmt.Println(task)
}()
}
time.Sleep(time.Second)
}goroutineの起動はOSのネイティブスレッドより高速ですが、それでもコストゼロではありません。 ループの変数は使いまわされてしまいますし、単純なループに比べてgoroutineの起動が遅いため、クロージャを使ってキャプチャするとループが回るたびにプログラマーが意図したのとは別のデータを参照してしまいます。 その場合は関数の引数経由にして明示的に値コピーが行われるようにします。
子どものgoroutineから親へは、引数やクロージャで渡したデータ構造(配列やマップ、後述のチャネルなど)に書き込む、あるいはクロージャでキャプチャした変数(キャプチャはポインタを引数に渡した扱いになる)に書き込むことになります。 マップの要素へのアクセスはアトミックではないため、注意が必要です。 同時に書き込むと、予期せぬ上書きが発生する可能性があるため、何らかの形で同時上書きを防ぐ必要があります。
一番単純な方法は、書き込み先を共有しないことです。 たとえば、10個のgoroutineを同時に実行するとき、最初から10個分の結果を保存する配列を用意しておいて、それぞれのgoroutineから別の領域に書き込むようにするという方法があります。 それ以外には、後述のチャネル、あるいは次回の連載で紹介予定のsyncパッケージでデータアクセス側を直列化するという方法があります。
チャネル
Go言語のチャネルは、他の言語では「キュー(queue)」と呼ばれる、最初に投入したデータが最初に出力される「First-in, First-out」(FIFO)型のデータ構造です。 この連載の第7回では、TCPサーバでレスポンスの順番を制御するのにチャネルを使う例を紹介しました。
チャネルは、整合性が壊れることがない、安全なデータ構造になっています。同時に複数のgoroutineでチャネルに読み書きを行っても、1つのgoroutineだけがデータを投入できます。データの取り出しも、同時に1つのgoroutineだけができます。
Go言語では、goroutineとの情報共有方法としてチャネルを使うことを推奨しています。 直接のメモリアクセスを行わないようにすることで、マルチスレッド上に疑似マルチプロセス環境ができあがります。
チャネルの使用例としては、入力データ、データ出力先、終了状態の伝達などがあります。 Goのバージョン1.7からは、終了とタイムアウトの管理にcontext.Contextを利用しますが、このコンテキストの終了判定(Done()メソッド)もチャネルを介して行います。
チャネルには、3つの状態があります。
| 状態 | バッファなしチャネル | バッファ付きチャネル | 閉じたチャネル |
|---|---|---|---|
| 作り方 | make(chan 型) |
make(chan 型, 個数) |
close(既存のチャネル) |
チャネル <- 値 で送信 |
受け取り側が受信操作をするまで停止 | バッファがあれば即座に終了。無ければ同左 | パニック |
変数 := <- チャネル で受信 |
送信側がデータを入れるまで停止 | 送信側がデータを入れるまで停止 | デフォルト値を返す |
変数, ok := <- チャネルで受信 |
同上+okにtrueが入る |
同上+okにtrueが入る |
同上+okにfalseが入る |
for 変数 := range チャネル 受信 |
チャネルに値が入るたびにループ回る | チャネルに値が入るたびにループ回る | ループから抜ける |
チャネルを作るには、下記の例のようにmake()を使います。 2つめの引数を省略するとバッファなしのチャネル、数値を指定するとバッファ付きのチャネルになります。 両者は、チャネルへの送信以外は同じ動作です。
// バッファなし
tasks := make(chan string)
// バッファ付き
tasks := make(chan string, 10)チャネルへデータを送信したり、チャネルからデータを受信するには、下記のように<-演算子を使います。
// データを送信
tasks <- "cmake .."
tasks <- "cmake . --build Debug"
// データを受け取り
task := <-tasks
// データ受け取り&クローズ判定
task, ok := <-tasks
// データを読み捨てる場合は代入文も不要
<-waitバッファなしのチャネルでは、受け取り側が受信をしないと送信側もブロックされます。 バッファ付きであれば、バッファがある限りすぐに完了して次の行が実行されます。
受け取り時は、1つ変数を書けば受信したデータが格納されます。 2つめにはbool型の変数を書くことができ、チャネルがまだオープンであればtrueが格納されます。 すでに本連載のサンプルで使っていますが、終了待ちのチャネルでデータそのものに意味がない場合は<-waitのように書くこともあります。
読み込みは基本的に送信側が送信するまでブロックします。 配列を使う場合のように、len()を使ってチャネルに入ったデータ数を確認し、データが入っているときだけ読み込むというコードにすれば、ブロックさせないことは可能です。 しかし、その方法だと読み込み側が並列になったときにスケールしません。そのため、次に紹介するselectを使うほうがよいでしょう。
チャネルはforループに対して使うこともできます。 データが投入される限りループが続く、無限配列のようなコードが作れます。
for task := range tasks {
// タスクチャネルにデータが投入される限りループが続く
}チャネルを閉じるにはclose(チャネル)を呼びます。 チャネルを閉じると、そのチャネルを使っているループが終了します。 また、読み込みではデフォルト値(数値なら0、文字列なら空文字列など)が返ってくるようになり、送信しようとするとパニックになります。
注意が必要なのは、クローズされているかどうかを受信側で知るための明確な方法がない点です。 過去にはクローズ状態かどうかを判定する関数が提供されていましたが、今はありません。 クローズされているとデフォルト値が返ってくるため、実際に数字の0を送信する必要がある場合には、数値だけ見ても正常値と異常値の判定ができません。 プログラムの意図を明確にするには、終了情報のやりとりのために別のチャネルを利用すべきです。
チャネルは、クローズしなくてもガベージコレクタに回収されます(参考)。
データを流すチャネルは、正常なデータにノイズが混ざる可能性があるため、クローズしないほうがよいでしょう。
逆に、終了情報のシグナルを目的としたチャネルは、複数のgoroutineが監視している場合でもすべてに終了を通知できるため、close()を行うほうがよいでしょう。
close()を呼んでしまうと、チャネルに値が入っていてもそれ以上データの取り出しができない」と説明していたのですが、これは筆者の勘違いでした。訂正します。上記の2段落は、クローズの用途を改めて考えたうえで内容を修正しています。はてなブックマークで指摘してくださったyukimemiさんありがとうございます。(2017年5月9日)
さきほどのタイマーを使った待ちをチャネルを使って書き換えてみたのが下記のコードです。 この例ではデータはどんなものでも構わないので、boolを使っています3。
package main
import (
"fmt"
)
func main() {
fmt.Println("start sub()")
// 終了を受け取るためのチャネル
done := make(chan bool)
go func() {
fmt.Println("sub() is finished")
// 終了を通知
done <- true
}()
// 終了を待つ
<-done
fmt.Println("all tasks are finished")
}下記のコードは、単なるチャネルではなく、Go言語のバージョン1.7から入ったcontextパッケージによるコンテキストを使った方法です。 コンテキストは、深いネストの中、あるいは派生ジョブとかがあって複雑なロジックの中でも、正しく終了やキャンセル、タイムアウトが実装できるようにする仕組みです。 このコードでは、終了を受け取るコンテキストctxと、そのコンテキストを終了させるcancel関数をcontext.WithCancel()を通じて取得して利用しています。
package main
import (
"context"
"fmt"
)
func main() {
fmt.Println("start sub()")
// 終了を受け取るための終了関数付きコンテキスト
ctx, cancel := context.WithCancel(context.Background())
go func() {
fmt.Println("sub() is finished")
// 終了を通知
cancel()
}()
// 終了を待つ
<-ctx.Done()
fmt.Println("all tasks are finished")
}context.WithCancel()以外には、終了時間を設定したりタイムアウトの期限を設定できるcontext.WithDeadline()やcontext.WithTimeout()もあります。
select文
チャネルを使えばデータの入出力が直列化します。 データを処理するgoroutineに対して複数のgoroutineから同時にデータを送り込んだり、そのgoroutineが返すデータを複数goroutineが並列で読み込んでも、チャネルを経由するだけでロックなどを実装する必要はなくなります。
多対1の書き込み、1対多の読み込みはこれで特に問題はありませんが、多対1の読み込み、1対多の書き込みでは少し事情が異なります。 終了フラグ、データ読み込みなどの両方のチャネルを扱う場合に、終了フラグを先に読み込むと、終了されるまでブロックしてしまいます。 それでは他の仕事ができなくなります。
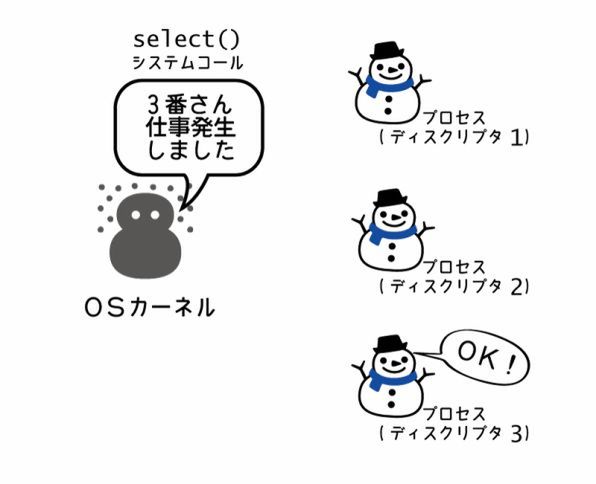
ブロックしうる複数のチャネルを同時に並列で読み込み、最初に読み込めたものを処理するにはselect文を使います。
連載の第12回の「ファイルシステムと、その上のGo言語の関数たち(3)」ではselect属のシステムコールを紹介しました。 OSの場合には、ブロックしうる複数のI/Oシステムコールをまとめて登録し、準備ができたものを教えてもらうのがselect()でした。 Go言語のselect文は、名前が同じことからも分かるように、この点についてはOSが提供するselect()システムコールとまさに同じです4。
Go言語のselect文の基本的な使い方は、下記のコードのようになります。 selectは、一度トリガーすると終わってしまうため、forループでくくって使われることがほとんどです。 case文には必要な数だけチャネルの読み込みコードを列挙します。 変数を書くと読み込んだ値も取得できます。 こちらの構文を使うと、どれかのチャネルが応答するまではブロックし続けます。
for {
select {
case data := <-reader:
// 読み込んだデータを利用
case <-exit:
// ループを抜ける
break
}
}下記のようにdefault節を書くと、何も読み込めなかったときにその節が実行されます。 こちらの構文の場合はブロックせずに、すぐに終了します。 チャネルにデータが入るまでポーリングでループを回したい場合に使えます。
select {
case data := <-reader:
// 読み込んだデータを利用
default:
// まだデータが来ていない
break
}事例を見かけたことはありませんが、selectを使って複数のチャネルへの書き込みのブロッキングを扱うこともできます。
case tasks <- "make clean":並列・並行処理の手法のパターン
ここまでは、goroutineとチャネル、select文の組み合わせによって、Go言語で並列・並行処理が簡単に実現できることを見てきました。 今回の記事のまとめとして、複数のコアを使って重い処理・ブロックする処理を効率よくさばく方法について、Go言語に限らない一般的な基礎知識を解説しておきます。
並列・並行処理の実現手法には、おおまかに区分すると、マルチプロセス、イベント駆動、マルチスレッドの3つのパターンがあります。 各パターンの比較表を下記に示します。 なお、特徴で×がついているものも、回避のためのテクニックがあることがほとんです(これから説明していきます)。
| 手法 | マルチプロセス | イベント駆動 | マルチスレッド |
|---|---|---|---|
| 特徴 | スクリプト言語でも使える | I/O待ちが重い時に最適 | 性能が高い |
| 複数のタスクを同時に行う(並行) | ◯ | ◯ | ◯ |
| 複数コアを使う(並列) | ◯ | × | ◯ |
| 起動コスト | × | ◯ | △ |
| 情報共有コスト | × | ◯ | ◯ |
| メモリ安全性 | ◯ | △ | × |
これらを選択することは、プログラムの構造を根本から書き換える必要があるようなデザインの決定になります。 そのため、通常は、必要な処理がCPUバウンド(CPUの処理時間が支配的)なのかI/Oバウンド(I/O待ち時間が支配的)なのかを判断し、改善したい箇所についてあたりをつけたうえで、プログラムを実装する前にいずれかを選択する必要があります。 しかし、Go言語の場合には、前半で解説した3つの道具を使うことで、アプリケーションの構造まで手を入れずとも気軽にこれらの手法を使い分けることができます。 低いストレスで並列・並行プログラミングを学ぶ題材としてGo言語は最適です。
マルチプロセス
連載の第14回「Go言語で知るプロセス(2)」では、「Go言語では触れることのない世界」として、マルチプロセスを使った並列・並行処理について紹介しました。 複数のCPUコアを持つコンピュータであれば、それぞれのプロセスは並行に動きますし、シングルコアでも時分割でCPU時間を分け合って並列で動作します。 処理系のコアが並行アクセスを許容していない、もしくはボトルネックがあるスクリプト言語などでも、マルチプロセスを使った並列・並行処理がよく使われます。
プロセス同士はメモリ空間がしっかりと分割されるため、マルチプロセスによる並列・並行処理は安全性が高い方法だといえます。 同じロジックを同時に実行する場合であれば、(Goはサポートしていませんが)フォークすることでメモリ使用量を下げることもできます (ただし共通のファイルへのアクセスでは問題も発生します)。
フォークによるマルチプロセスのデメリットは、起動のために時間がかかる点です。 OSでは「Go言語で知るプロセス(2)」で紹介したようなフォークのオプションもいくつか用意されていますが、ファイルディスクリプタテーブルなどのコピーが走りますし、コピーオンライトでも最終的にはいくつかのメモリ領域のコピーが発生します。 そのため、事前にフォークしておくなどしてプロセスをCPUコア数分作っておき、プロセスプールに貯めておいて必要になったらすぐに使えるようにする、といった工夫が行われます。
マルチプロセスには、メモリ空間が分かれることによるデメリットもあります。 プロセス間でデータを共有するには、共有メモリ5やプロセス間通信、メッセージ・キュー6などの仕組みが必要です。 仕事をするプロセス間でCPU時間が回ってくると、コンテキストスイッチという処理が行われ、CPU内部で持つ演算用、あるいは実行処理のフラグや状態用のメモリであるレジスタを退避したり復元されます。 これには実行コストがかかります。
イベント駆動
イベント駆動が主に使われるのは、並列化ではなく並行処理のためです。 ファイルI/Oやネットワークアクセスなど、I/O待ちが多いプログラム(I/Oバウンドなプログラム)で使います。 イベント駆動という言葉は、GUIプログラミングの文脈でもよく使われますが、システムプログラミングの文脈では第12回の「ファイルシステムと、その上のGo言語の関数たち(3)」で紹介したselect属によるI/Oマルチプレクサー(多重化)のことを指します。 Node.jsのコアになっているlibuv、あるいはPythonのasyncioパッケージなどが該当します。
イベント駆動は、OSに依頼をしたデータ受信の仕事が終わるたびにコールバックが返ってくる仕組みで、次のスレッドと組み合わせていなければ常に1つのスレッドがその受信したデータを処理します。 そのため、複数のコア間でデータ競合が発生することはありません。また、デバッガーなどで処理をおいかけても逐次処理でしかないため、タイミングで結果が変わったりずれたりすることはあまりないでしょう。 コンテキストスイッチも少ないため、処理によってはマルチプロセスよりCPU効率も高くなります。 並列で実行しているジョブ同士は同じプロセス内なので、情報の共有もマルチプロセスより簡単です。
イベント駆動の欠点は、単体ではCPUを使いこなしにくい点です。 CPUのコア数分プロセスを起動し、その中でイベント駆動をする、あるいは、イベント駆動でOSからデータが返ってきたところで処理部分をスレッドやプロセスで並行実行する(ファンアウト)必要があり、コードが複雑になりがちです。
PythonのMeinheld7は、このイベント駆動のライブラリであるpicoev8を核にしてI/O待ちを多重化して効率化し、軽量スレッドによる並行処理を実装しているgreenlet9を組み合わせてシングルスレッドあたりのCPU稼働率を上げ、さらにサービスをフォークしてマルチプロセスで動作させるgunicorn10をプラスしてマルチコアの性能を引き出すことで、TechEmpowerのベンチマーク11ではスクリプト言語では上位の成績を残しています。
マルチスレッド
マルチスレッドは、同じメモリ空間内で多くのCPUが同時に実行するための仕組みです。 実際、第14回の「Go言語で知るプロセス(2)」で紹介したように、Linuxではプロセスもシグナルもカーネル上は同じ構造体で表現されています。 親のプロセスとメモリ空間を共有していなければプロセス、共有していたらスレッドです。
通常はOSのスレッドを使って並列性を向上させますが、並行性の向上に限定したグリーンスレッド、あるいは軽量スレッド(ファイバ)と呼ばれるものを使うこともあります。 Go言語のgoroutineも軽量スレッドです。ただし、複数のOSスレッド上にマッピングして同時に実行されるため、並列で動作します。
マルチスレッドの利点はCPUのパフォーマンスです。 複数のコアの性能を引き出すことができます。 また、メモリ空間を共有しているため、コンテキストスイッチのコストはプロセスよりも小さく、またスレッド間ではコピー不要でデータの共有が高速に行えます。
欠点としては、プロセスほどではありませんが、OSのスレッドの場合は比較的大きなスタックメモリ(1〜2メガバイト)を必要としますし、起動時間がややかかります。 そのため、プロセス同様に、事前にCPUコア数分のスレッドを作っておいてスレッドプールに貯めておき、必要になったらすぐ使えるようにする、といったことが行われます。 また、コンテキストスイッチのコストもプロセスと同じだけかかります。 Go言語やErlangのようなユーザー空間で作られた軽量スレッドの場合は、どちらのコストもやや低くなります。
まとめと次回予告
今回は並行・並列処理の基本と、Go言語が提供する3つの基本ツールを紹介しました。 Goの作者のRob Pikeのスライド12でもGoが提供する平行・並列処理の三要素として紹介されています。
- goroutine: 実行
- チャネル: コミュニケーション
- select: 調停(coordination)
Goでは平行・並列処理を記述するための基本ツールとしてこれらの文法を使うのが当たり前となっています。
次回はsyncパッケージについて紹介します。
脚注
- もちろん、グローバル変数を使うことも可能ではあります。↩
- Linda_ppさんのスライドではGo製のオリジナル言語でのクロージャの実装方法が書かれていますが、Go自身も考え方は同じです: https://speakerdeck.com/rhysd/go-detukurufan-yong-yan-yu-chu-li-xi-shi-zhuang-zhan-lue?slide=40↩
- Goのイディオムとしては、0バイトの空構造体
struct{}をチャネル宣言時の型に使い、チャネルに投入する値としてそのインスタンスのstruct{}{}使う方法もあります。↩ - GoCon2017で
selectについて発表した小泉守義氏によると、Goの内部実装もLinuxカーネルと似ているとのことです(@moriyoshit「Goをカンストさせる話」: https://www.slideshare.net/moriyoshi/go-73631497 )。↩ - POSIXには共有メモリというシステムコールがありますが、Go言語では非対応です。 それ以外に、第12回の「ファイルシステムと、その上のGo言語の関数たち(3)」 で紹介した、mmapシステムコールを利用したメモリマップドファイルがあり、こちらは使えます。↩
- POSIXにはPOSIX MQというシステムコールもありますが、こちらもGo言語では非対応です↩
- http://meinheld.org/↩
- http://developer.cybozu.co.jp/archives/kazuho/2009/08/picoev-a-tiny-e.html↩
- http://greenlet.readthedocs.io/en/latest/↩
- http://gunicorn.org/↩
- https://www.techempower.com/benchmarks/↩
- https://talks.golang.org/2015/simplicity-is-complicated.slide↩
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第20回
プログラミング+
Go言語とコンテナ -
第19回
プログラミング+
Go言語のメモリ管理 -
第18回
プログラミング+
Go言語と並列処理(3) -
第17回
プログラミング+
Go言語と並列処理(2) -
第15回
プログラミング+
Go言語で知るプロセス(3) -
第14回
プログラミング+
Go言語で知るプロセス(2) -
第13回
プログラミング+
Go言語で知るプロセス(1) -
第12回
プログラミング+
ファイルシステムと、その上のGo言語の関数たち(3) -
第11回
プログラミング+
ファイルシステムと、その上のGo言語の関数たち(2) -
第10回
プログラミング+
ファイルシステムと、その上のGo言語の関数たち(1) - この連載の一覧へ





&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")


















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")
