
前々回は並行・並列の基本とGo言語の文法、前回はOSスレッドとの違いと、並列処理をサポートする標準ライブラリの紹介をしてきました。 今回は、並行・並列で処理を記述するためのパターンをいくつか紹介します。 さらに、Goによるプログラミングには直接関係しませんが、これまでの説明では登場しない並列処理のモデルとして、GPUのスレッディンングモデルを紹介します。
今回の記事の執筆にあたっては、GPUまわりの部分でエヌビディアジャパンの森野慎也さんにご協力いただきました。 感謝申し上げます。
Goにおける並行・並列処理のパターン集
Goにかぎらず、並列化を導入するとどれだけ効率が改善するかをあらわす数式として有名な、アムダールの法則というものがあります。
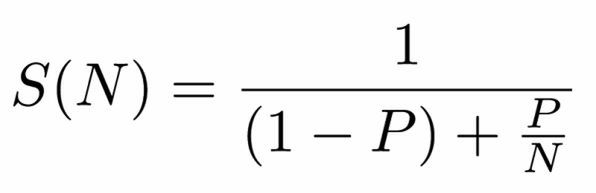
Pは並列化できる仕事の割合、Nは並列数です。 ある仕事のうち50%の部分が並列化可能だとすると、Nを無限大にしても(分母の右側の項がゼロになる)、パフォーマンスは2倍にしかなりません。 90%が並列化可能だとすると、最大で10倍になります。 並列化の恩恵がどれだけあるかは、並列化できる仕事の割合によって変わるのです。
アムダールの法則によると、並列化して効率がどれだけ改善できるかどうかは、Pにかかっているといえます。 Pを改善するには、逐次処理をなるべく分解して、同じ粒度のシンプルなたくさんのジョブに分ける必要があります。 今回の話題は、Goプログラムをそのように構造化するときに有効な並行・並列化のためのパターンを一気に紹介していきます。
- 同期処理を非同期にする
- 非同期にしたものを同期化する
- タスク生成と処理を分ける(Producer-Consumerパターン)
- 開始した順で処理する(チャネルのチャネル)
- タスク処理が詰まったら待機(バックプレッシャー)
- 並列なForループ
- 決まった数のgoroutineでタスクを消化する(ワーカープール)
- 依存関係のあるタスクを表現する(Future/Promise)
- イベントの流れを定義する(ReactiveX)
- 自立した複数のシステムで協調動作(アクターモデル)
ジョブそのものをスレッドで高速化する方法もいくつもあります。 オライリー・ジャパンの「並行コンピューティング技法」には、MapReduceやソート、検索をマルチスレッドで高速化する方法が紹介されています。 今回はそれらのロジックよりも粒度の大きな話のみを取り扱います。
同期→非同期化
並行・並列化の第一歩は、「重い処理」をタスクに分けることです。 Goでは、重い処理をgoroutineの中で実行して非同期化するというのが、これにあたります。 Goのシンプルな文法で実現できることですが、これもパターンとして道具箱に入れておきましょう。
次のコードでは、ファイルの読み込みをgoroutineとして切り出しています。
inputs := make(chan []byte)
go func() {
a, _ := ioutil.ReadFile("a.txt")
inputs<-a
}()
go func() {
b, _ := ioutil.ReadFile("b.txt")
inputs<-b
}()
上記のコードでは単発のジョブを切り出していますが、「I/O処理専門のgoroutineをサービス化する」といった具合に、責任分担に応じてタスクを切り出すこともよくあります。 goroutineのような気軽な軽量スレッドを作れない言語だと、そうした少し大きめの粒度の責務単位でスレッドを作ることが多いでしょう。
非同期→同期化
非同期化したら、どこかで同期する必要があります。 そうでないと、Goの場合、main()関数の処理が終わったタイミングでタスクが残っていてもコードが終了してしまいます。
非同期化させた処理を同期化させる、いちばん簡単な方法が、チャネルです。 チャネルは、終了待ちや処理の同期にも使えるし、データの受け渡しも安全に行えます。
ただし、selectを使わずにチャネルの読み込みを行うとブロックしてしまうため、1つのgoroutineが同時に読み込めるチャネルは1つだけになってしまいます。 複数のチャネルから読み込むときはselectが必要となります。 selectはdefault節なしでイベント駆動、ありで非同期I/Oとして扱えます (詳しくは前々回の記事を参照してください)。
それ以外では、sync.WaitGroupで複数のタスクの完了待ち、sync.Condでスタート待ち、sync.Mutexでクリティカルセクションの処理が交錯するのを避けることができました。 これらは前回の記事で紹介しています。
タスク生成と処理を分ける: Producer-Consumer
タスクを生成する側と処理をする側を、それぞれProducer(生産者)、Consumer(消費者)と呼びます。
このパターンは、Go言語であれば、チャネルでProducerとConsumerを接続することで簡単に実現できます。 チャネルは、複数のgoroutineで同時に読み込みを行っても、かならず1つのgoroutineだけが1つの結果を受け取れます(消失したり、複製ができてしまうことはない)。 したがって、Consumer側の数を増やすことで、安全に処理速度をスケールできます。
プロセスをまたいでProducer-Consumerパターンを実現するには、一般にメッセージキューと呼ばれるミドルウェアで仲介します。 シンプルなものではbeanstalkd1という、メッセージキューのミドルウェアがあり、beanstalkd公式のGo用のクライアントライブラリ2が提供されています。
Amazon SQSのような、メッセージキューのクラウドサービスもあります。 負荷に応じてConsumerプロセスの起動まで面倒見てくれるものはサーバーレスアーキテクチャと呼ばれ、AWS/GCP/Azureで提供されています。
開始した順で処理する: チャネルのチャネル
第7回の「GoでたたくTCPソケット(後編)」では、パイプライニングの実装例でチャネルのチャネルを使用しました。
チャネルはFIFOのキューとして使えます。 早く終わったものから順番に処理すればいいのならチャネルで十分です。 一方、早く開始したものから順番に処理するときは、チャネルの中に開始順にチャネルを入れて、それぞれの子チャネルで終了を待ちます。
// 終了した順に書き出し
// チャネルに結果が投入された順に処理される
func writeToConn(responses chan *http.Response, conn net.Conn) {
defer conn.Close()
// 順番に取り出す
for response := range responses {
response.Write(conn)
}
}
// 開始した順に書き出し
// チャネルにチャネルを入れた(開始した)順に処理される
func writeToConn(sessionResponses chan chan *http.Response, conn net.Conn) {
defer conn.Close()
// 順番に取り出す
for sessionResponse := range sessionResponses {
// 選択された仕事が終わるまで待つ
response := <-sessionResponse
response.Write(conn)
}
}
タスク処理が詰まったら待機: バックプレッシャー
バックプレッシャーというのはネットワーク用語です。 本来は、LANのスイッチにおいて、パケットが溢れそうになったら送信側に衝突が発生したという信号を意図的に送り、送信量を落とさせる仕組みのことを言います。 この仕組みの特徴は、データが流れる方向とは逆向きに制御が働くことです。 最近では、メールボックスが溢れそうなときの制御など、非同期処理全般で広く使われる用語になってきています。
Goの場合は、goroutineの入力にバッファ付きのチャネルを使うだけでバックプレッシャーを実現できます。 チャネルではバッファサイズを指定できますが、無限大のバッファは実現できません。 バッファのサイズは平常時に送信側が詰まらない程度のサイズにします。
tasks := make(chan string, 10)
並列Forループ
Forループ内をすべてgoroutineで実行すれば、並列化します。 注意点としては、ループ変数の実体は1つしかないため、goroutineの引数として渡し、goroutineごとにコピーが作られるようにします(前々回の記事も参照してください)。
package main
import (
"fmt"
"sync"
)
func main() {
tasks := []string{
"cmake ..",
"cmake . --build Release",
"cpack",
}
var wg sync.WaitGroup
wg.Add(len(tasks))
for _, task := range tasks {
go func(task string) {
// ジョブを実行
// このサンプルでは出力だけしています
fmt.Println(task)
wg.Done()
}(task)
}
wg.Wait()
}
ループの内部の処理が小さすぎると、オーバーヘッドのほうが大きくなり、効率が上がらないこともあります。 I/O待ちが主体であればそれでも問題ありませんが、計算速度はループをいくら増やしてもCPUのコア数以上にはスケールしないため、CPUの負荷が重い場合は次に紹介するgoroutineループを利用するほうがいいでしょう。
決まった数のgoroutineでタスクを消化: ワーカープール
OSスレッドやフォークしたプロセスで多数の処理をこなすときは、生成コストの問題があるため、事前にワーカーをいくつか作ってストックしておき、そのワーカーが並列でタスクを消化していく方法がよく取られます。 事前に作られたワーカー群のことを、スレッドプールとかプロセスプール、あるいはワーカープールなどと呼びます。
Goでも、goroutineの生成コストは(OSスレッドよりも小さいとはいえ)ゼロではありませんし、そもそもCPUのコア数以上にgoroutineを作ってもスループットは増えません。 そのため、CPUコア数分のワーカーをgoroutineを作って処理するのが効果的な場合があります。
次のコードは、1年〜35年の住宅ローンを計算するサンプルです。各計算をワーカープールのワーカーで分散して行います。 タスクはすべてチャネルに入れて、すべてのgoroutineはそこからタスクを取り出します。 各計算は軽いですが、タスクは前回紹介したruntime.NumCPU()の個数分起動しているので、CPUを目一杯回すことができます。
package main
import (
"fmt"
"runtime"
"sync"
)
// 計算: 元金均等
func calc(id, price int, interestRate float64, year int) {
months := year * 12
interest := 0
for i := 0; i < months; i++ {
balance := price * (months - i) / months
interest += int(float64(balance) * interestRate / 12)
}
fmt.Printf("year=%d total=%d interest=%d id=%d\n", year, price + interest, interest, id)
}
// ワーカー
func worker(id, price int, interestRate float64, years chan int, wg *sync.WaitGroup) {
// タスクがなくなってタスクのチャネルがcloseされるまで無限ループ
for year := range years {
calc(id, price, interestRate, year)
wg.Done()
}
}
func main() {
// 借入額
price := 40000000
// 利子 1.1%固定
interestRate := 0.011
// タスクはchanに格納
years := make(chan int, 35)
for i := 1; i < 36; i++ {
years <- i
}
var wg sync.WaitGroup
wg.Add(35)
// CPUコア数分のgoroutine起動
for i := 0; i < runtime.NumCPU(); i++ {
go worker(i, price, interestRate, years, &wg)
}
// すべてのワーカーが終了する
close(years)
wg.Wait()
}
依存関係のあるタスクを表現する: Future/Promise
Future/Promiseは、1977年に論文で紹介され、Javaに実装されたことで広く知られるようになったタスク分割の手法です。 依存関係のあるタスクをパイプラインとしてスマートに表現し、実行可能なタスクから効率よく消化していくことで遅延を短縮します。
Future/Promiseを使う場合は、タスクの処理を書くときに、「今はまだ得られてないけど将来得られるはずの入力」(Future)を使ってロジックを作成していきます。 それに対応する「将来、値を提供するという約束」(Promise)が果たされると、必要なデータがそろったタスクが逐次実行されます。
Goの場合は、すべてのタスクをgoroutineとして表現し、Futureはバッファなしチャネルの受信、Promiseは同じチャネルへの送信で実現できます。
package main
import (
"fmt"
"io/ioutil"
"strings"
)
func readFile(path string) chan string {
// ファイルを読み込み、その結果を返すFutureを返す
promise := make(chan string)
go func() {
content, err := ioutil.ReadFile(path)
if err != nil {
fmt.Printf("read error %s\n", err.Error())
close(promise)
} else {
// 約束を果たした
promise <- string(content)
}
}()
return promise
}
func printFunc(futureSource chan string) chan []string {
// 文字列中の関数一覧を返すFutureを返す
promise := make(chan []string)
go func() {
var result []string
// futureが解決するまで待って実行
for _, line := range strings.Split(<-futureSource, "\n") {
if strings.HasPrefix(line, "func ") {
result = append(result, line)
}
}
// 約束を果たした
promise <- result
}()
return promise
}
func main() {
futureSource := readFile("future_promise.go")
futureFuncs := printFunc(futureSource)
fmt.Println(strings.Join(<-futureFuncs, "\n"))
}
上記のコードでは、非同期で実行している処理が2つあります。 1つめのタスクでは、ファイルの読み込みが終わった時点で、それが格納されるFutureを返しています。 2つめのタスクでは、そのソースを受け取り、分析が終わったらソース中に含まれる関数宣言のリストが格納されるFutureを返しています。
Futureでは、結果を1回でまとめて送ります(この点は後述のReactiveXとは異なります)。 サーバー越しに取得してきたファイルを小分けにして10回送る、といった処理のことは考えられていません。 上記の実装はシンプルなものなので、実用的なものにするためには、途中で中断されたことを把握できるように全てのジョブにContextを渡すといったことが必要になるでしょう(Contextについては第16回の記事を参照してください)。
イベントの流れを定義する: ReactiveX
ReactiveXは、オブジェクト指向のデザインパターンでおなじみのオブザーバーパターンが少し賢くなったものです。 Microsoftが.net向けに開発したReactive Extensionがオープンソース化され、ReactiveXというGitHubのグループ下で各言語のライブラリが提供されています。 Go言語用にもライブラリが提供されています。
オブザーバーパターンでは、監視している値(Observable)が変更されると、監視している側(Observer)に確実に(漏れなくダブりなく)通知を行うのが責務でした。 ReactiveXでは、イベントやデータのストリーム(流れ)を定義し、何度もひんぱんに発生するイベントも取り扱えるように拡張されています。
ReactiveXは、ここ数年、ユーザーインタフェースまわりのロジックの記述方法として一般化しています。 JavaScriptのフロントエンド開発でも、スクロールイベントでは極短期間に大量のイベント発火が起きるため、イベントハンドラ内で逐一ロジックを書いて実行するとパフォーマンス上のトラブルとなることがよく知られています。 ReactiveXのObservableには、イベント出力そのものを制御するメソッドが多数定義されており、Skip()やFilter()などでイベントを間引いたり、Map()で出力されたイベントを加工したりできます。 詳しくは次のgodocにある、Observableのメソッドを参照してください。
GoにおけるReactiveXの使い方の例を下記に示します。 Go言語らしいコードではなく、ReactiveXの流儀が強いため、Go言語に慣れた人には違和感があるかもしれません。
package main
import (
"fmt"
"github.com/reactivex/rxgo/observable"
"github.com/reactivex/rxgo/observer"
"io/ioutil"
"strings"
)
func main() {
// observableを作成
emitter := make(chan interface{})
source := observable.Observable(emitter)
// イベントを受け取るobserverを作成
watcher := observer.Observer{
NextHandler: func(item interface{}) {
line := item.(string)
if strings.HasPrefix(line, "func ") {
fmt.Println(line)
}
},
ErrHandler: func(err error) {
fmt.Printf("Encountered error: %v\n", err)
},
DoneHandler: func() {
fmt.Println("Done!")
},
}
// observableとobserverを接続(購読)
sub := source.Subscribe(watcher)
// observableに値を投入
go func() {
content, err := ioutil.ReadFile("reactive.go")
if err != nil {
emitter <- err
} else {
for _, line := range strings.Split(string(content), "\n") {
emitter <- line
}
}
close(emitter)
}()
// 終了待ち
<-sub
}
RxGoのObservableは、受信専用のchan interface{}です。 Observerは、ハンドラ関数を持つ構造体です。 上記の例では、この2つを作り、それらをSubscribe()メソッドで繋いでいます。
Future/Promiseと違って何回もイベントが発行できるため、この例では一行単位でイベントを発生させています。 Observableのチャネルに送信することでイベントが発火します。
このサンプルは、一番オーソドックスで汎用の利用方法を示したものです。 すでに項目数がわかっているデータ列をObservableにするなど、いくつかのケースでObservableを短く表現できるショートカットが提供されています。
自立した複数のシステムで協調動作: アクターモデル
アクターモデルは、Future/Promiseよりも古い、1973年に発表された並列演算モデルです。 自律した多数の小さなコンピュータ(アクターと呼ばれます)が協調して動作するというモデルになっています。 各アクターは、別のアクターから送られてくるメッセージを受け取るメールボックスを持ち、そのメッセージをもとに協調動作します。 各アクターは自律しており、並行動作するものとして考えます。
アクターモデルは、構成要素だけ見ると、すでに説明したProducer-Consumerパターンと似ています。 Producer-Consumerパターンはサーバー・クライアントモデルのような上下関係に近い組み合わせですが、アクターモデルはシミュレーション用途で考案されたこともあって、もっと多種類のアクターがそれぞれ自律して動作することを想定しているという違いがあります。 共通のジョブリストではなく、各アクターごとにメールボックスを持っている点もアクターモデルの特徴です。
アクターモデルを採用していて長い歴史を持っているプログラミング言語として有名なのはErlang/OTPです。 Erlang/OTPでは、アクターの生存を親のアクターが監視し、必要に応じて再起動させるといった機構(Supervision Tree: 監視ツリー)を持つことで耐障害性を実現しています。 現在アクターモデルと呼ばれるものは、このSupervision TreeがセットになったErlang/OTPのそれを指しているといえるかもしれません。
Goにも、Erlang/OTPにインスパイアされたライブラリがあります3。
このライブラリは、裏で使っているProtocol Buffersの準備が必要なため、単純にgo getではインストールできません。 関連ライブラリをgo getしたあとに、ソースコードのフォルダ上でmakeする必要があります。 次のコードはprotoactor-goのサンプルコードに筆者がコメントを付けたものです。
package main
import (
"fmt"
"github.com/AsynkronIT/goconsole"
"github.com/AsynkronIT/protoactor-go/actor"
)
// メッセージの構造体
type hello struct{ Who string }
// アクターの構造体
type helloActor struct{}
// アクターのメールボックス受信時に呼ばれるメソッド
func (state *helloActor) Receive(context actor.Context) {
switch msg := context.Message().(type) {
case *hello:
fmt.Printf("Hello %v\n", msg.Who)
}
}
func main() {
props := actor.FromInstance(&helloActor{})
pid := actor.Spawn(props)
pid.Tell(&hello{Who: "Roger"})
console.ReadLine()
}
アクターは、Receiveメソッドを持つ構造体です。 Propsという生成方法を管理するオブジェクトを作成しておきます。 Spawn関数に渡すとアクターが作成され、そのアクターの識別子であるプロセスID(OSのプロセスIDとは別)が作られます。 プロセスIDに対してTellメソッドを使ってメッセージを送信できます。
もう一つの並行・並列実行モデル
前回の記事では、並行・並列のモデルとして次の3種類を紹介しました。
- マルチコア
- イベント駆動
- マルチスレッド
読者のみなさんのコンピュータの中には、これらのモデルを利用している多くの処理よりも、さらに大量のタスクを黙々とこなしている第4の並列処理機構があります。 それは、ヘテロジーニアス(異種のアーキテクチャとの組み合わせ)前提の並列モデルであるGPUのスレッディングモデルです。
OpenGLやDirectXの進化とともにGPU用のプログラム(シェーダー言語)による計算対象も頂点変換、ピクセルの描画色決定、ポリゴン生成など多種多様に渡ってきています。 現在はゲームの表現力向上のために、人体の肌の内部散乱や大域照明などさまざまな物理現象をピクセル単位で計算するなど、高度な演算が必要とされ、そのためにGPUも進化してきました。 また、CUDA、OpenCLなどで、汎用的な演算処理も実現されるようになりました。
シェーダー用の並列処理はOSのスレッドと大きく異なります。
- スレッドは常にハードウェアごとの許容される最大数が作られて稼働しており、生成も終了もない
- NVIDIA系の最新のGPUでは32スレッド、AMD系の最新のGPUでは64スレッド単位で同じタスクを処理する。前者はWarp、後者はWavefrontと呼ぶ
- ハードウェア上、計算ユニットがSM(Streaming Multiprocessor: NVIDIA用語)やCU(Compute Unit: AMD用語)という単位のブロックに分割されている
- スレッド切り替えはハードウェアで高速に行われる
- どのSM/CUにどのプログラムを割り当てるかは、ハードウェアが高速に実行されるようランタイムが決定し、プログラマは指定できない
たとえば、筆者のパソコンに入っているGeForce GTX 970は13個のSMを持っています。 1個のSMは128個のコア(CUDAコア)で構成されており、13 × 128 = 1664が、GPUのスペック表にあるCUDAコア数と一致します。 1個のSMは、128個のCUDAコアを利用して、4つのWarpを同時実行(4 × 32)します。
このようなGPUにおけるスレッド処理では、OSのスレッドとは異なるプログラミングモデルが必要になります。 具体的には、OSスレッドではスレッドごとにスタックやレジスタ、現在実行しているメモリアドレス(IP: Instruction Pointer)を持つのに対し、GPUでは同時実行するスレッドの間でIPを共有しており、それに伴う違いがあります。
たとえば、アニメ調の表現を行うフラグメントシェーダーで一定以上の明るさかどうかをif文で判定して色を出し分けていたりすると4、同じスレッドグループの中でもtrue節を実行するスレッドとfalse節を実行するスレッドとが同時に発生することになりますが、GPUのスレッドではIPが共有されているため、同時に別のコードブロックの実行ができません。 そこで、まずはtrue節が実行されるスレッドだけを有効化して実行し、その後でfalse節が実行されるスレッドを改めて実行し直します(これを分岐ダイバージェンスと呼びます)。
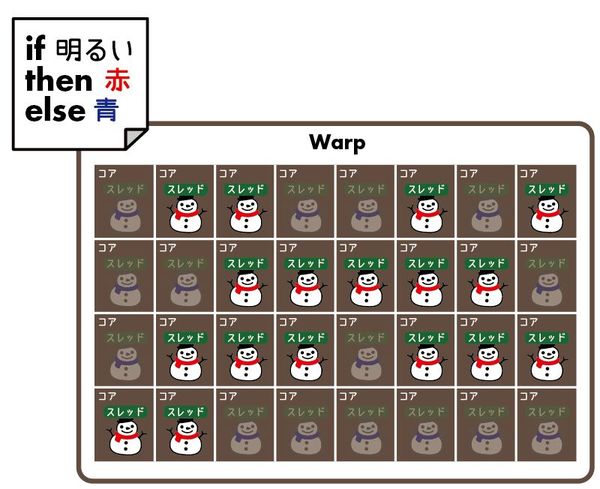
また、自スレッド以外の任意のスレッドが処理しているデータにアクセスするためには一旦結果をバッファに書き出してあらためて新しいプログラムをロードして実行し直す必要があるなどの制限もあります。
これらの違いは、プログラミングモデルとして見ると不便に思えますが、GPUでは数百〜数千のハードウェアスレッドのジョブスケジュールを効率よく行うスケジューラの実装や高度な分岐予測ロジックを実装するのではなく、単純な演算器を大量に並べることで解決する物量作戦に特化した構成となっているわけです。
さらに、現代のコンピューターでは、演算機(ALU)の速度と比較してメモリの速度がボトルネックになりがちです。 そのため、CPUにおける実行速度の向上ではデータの順番待ちをいかに隠蔽するかが重要になり、これを自動的にやる「アウト・オブ・オーダー実行」機能の有無でパフォーマンスが大きく異なります。 一方、GPUが処理するコードの場合には、演算器の数(同時処理ピクセル数)と比較して画面を構成するピクセル数のほうが多い(フルHDで200万)ので、高速なタスク切り替えを生かし、処理を一時保留して他の仕事をこなしつつデータがくるのを待つという、別の戦略でメモリ遅延に対抗しています。
このあたりの話を詳しく知りたい人は、英語になりますがアニメーション付きで説明しているRender Hellというページ、あるいはCUDAの書籍などが参考になります。 どちらかというとグラフィックスのAPIよりも、CUDAなどの汎用演算のほうがアーキテクチャを学ぶための情報は豊富に得られます。
- Render Hell 2.0: https://simonschreibt.de/gat/renderhell/
- CUDA C プロフェッショナルプログラミング(Impress刊): http://book.impress.co.jp/books/1115101001
まとめと次回予告
今回は、並行・並列処理に強いプログラムの構造として著名なパターンをいくつか紹介しました。 Goでは、標準の文法だけでも並行・並列処理を実現できますが、 効率的な並行・並列処理を行うには、そもそもタスクやロジックをうまく分割することがポイントです。 うまく分割できなければ、いくらGoを使っていても並列処理の恩恵にあずかることはできません。
「標準のシンプルな道具」を使いこなすには、 用意されたレールに乗るだけで一定の成果が得られるようなフレームワークを使うときとは異なり、使用者自身がレールを敷く必要があります。 実行効率やメンテナンス性を考えながらゼロから道具を再発明していくのも楽しいものですが、大抵の場合は既存のソリューションの形式に落ち着くと思いますし、実績のあるメソッドに則ったほうが他の人にとっても理解しやすいプログラムになるでしょう。 今回は、他の言語では一般的な一方、必ずしもGo言語で一般的に使われていないもの(Future/PromiseやReactiveX、アクターモデル)も取り上げていますが、そうした一般的なパターンを知っておくことも、Goによる解決策を考える上でマイナスにはならないでしょう。
さらに今回の記事では、Go言語の話からはそれますが、これまで説明してきたのとは異なる並列化のモデルとして、機械学習などで大活躍のGPUの構造も紹介しました。
次回は、メモリについて掘り下げていきます。
脚注
- https://github.com/kr/beanstalkd↩
- https://github.com/kr/beanstalk↩
- 正確にはErlang/OTPをインスパイアして作られたJava/Scala用のライブラリであるAkkaを、さらにインスパイアして作られたAkka.NETをベースに、Akka.NETの作者がリライトして.NET用とGo用に同時開発したライブラリのようです。↩
- 実際には色をif文などのハードコードされたロジックで計算することはあまりなく、明るさと出力する色の対比表のテーブルをテクスチャとして渡して表検索で解決する方が一般的だと思われます。↩
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第20回
プログラミング+
Go言語とコンテナ -
第19回
プログラミング+
Go言語のメモリ管理 -
第17回
プログラミング+
Go言語と並列処理(2) -
第16回
プログラミング+
Go言語と並列処理 -
第15回
プログラミング+
Go言語で知るプロセス(3) -
第14回
プログラミング+
Go言語で知るプロセス(2) -
第13回
プログラミング+
Go言語で知るプロセス(1) -
第12回
プログラミング+
ファイルシステムと、その上のGo言語の関数たち(3) -
第11回
プログラミング+
ファイルシステムと、その上のGo言語の関数たち(2) -
第10回
プログラミング+
ファイルシステムと、その上のGo言語の関数たち(1) - この連載の一覧へ



ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")








ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")
