




第4世代GCNを採用する
新アーキテクチャー「Polaris」
さて問題はその次である。前回の記事でも少し触れたが、今年のCESにおいてAMDはPolarisアーキテクチャーの発表を行なうとともに、実際のシリコンを利用してのデモも行なった。まずはこの話をしよう。
今回AMDはFinFETを利用して製造する新世代製品にPolarisアーキテクチャーという名称をつけたことを明らかにした。

Polarisの概要。“プロセスの違いにあわせて再設計した”となにげなく書いてあるところが怖い
ただ基本的には「第4世代GCN」という言い方をしているため、従来のGCNのアーキテクチャーを全部捨てたわけではなく、GCNをさらに強化したという方向性に見える。
これは下の画像の一番左で、ハードウェアベースのスケジューラーや命令プリフェッチを追加したり、シェーダーの効率性を上げたりといった項目が並んでいるからだ。

Polarisの詳細。あくまでも「歴史的な」飛躍(Historic Leap)であって、根本的な飛躍(Quantum Leap:量子力学的飛躍)ではないあたりは、前のアーキテクチャーを継承しているように思える
他にもDisplay Port 1.3(1.4aでないのが不思議だが)や、HDMI 2.0のサポート、H.265で最大4K60fpsのエンコード、あるいはH.265 main10のデコードなどを備えたビデオアクセラレーターも搭載されるとしている。
下の画像がそのPolarisアーキテクチャーの内部構造である。もっともこれだけでは旧来のGCN(例えばRadeon HD 7970の内部構造)となにが違うのかがさっぱりわからないのだが、1月時点ではその詳細を公開するつもりはないようで、これ以上の情報はない。
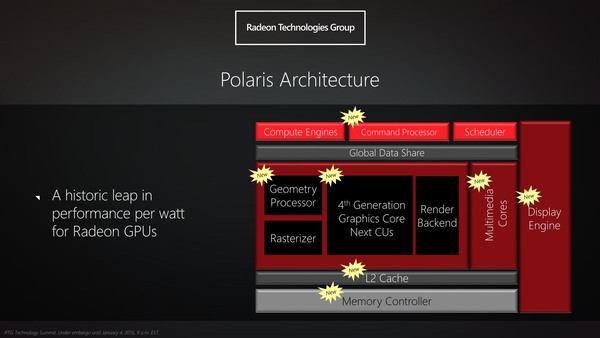
Polarisの内部構造。Global Data ShareとRasterizer、Render Backend以外は全部再設計した、ということを示したい「だけ」なので、これだけ見ても実はよくわからない
さて、ではCESにおいてなにに力点を置いたかといえば、FinFETの性能である。なぜFinFETを使うのかについてのAMDとしての回答がこちら右下の画像であるが、要するにプロセスをそのままだと静的なリーク電流を減らすことはできても、有効電力は下がらないからということになる。

14nmでも16nmでもなく、“FinFET”と書くところがポイント

FinFETを使う理由。Body Biasの説明は連載255回を参照してもらいたい
もっともBack bias(RBB:Reverse Body Bias)に言及するのなら、Forwad bias(FBB:Forward Body Bias)使えば性能上がるのでは? という議論もあるのだが、FBBでは消費電力が増えてしまうので性能/電力比は悪化するため、あえて入れていないのだろう。
その結果として、業界としては16nm以下に関してはほぼすべてがFinFETに移行することになった。
16nm以下はほぼすべてがFinFETに移行した。久本大博士のDELTA(DEpleted Lean-channel TrAnsistor)に関する話は(他メディアで恐縮だが)2011年にインタビューをさせていただいているのでよろしければお読みいただきたい
実用化という意味ではインテルの22nmが最初だが、その後TSMCやGlobalFoundriesなどが20nmのプレーナ型をリリースしているので、完全にFinFETに統一されたのは16nm以下、という話である。
理論上FinFET構成にするとプレーナ型よりも有利、という話は連載248回でも解説したが、結果として28nm世代と比較して「同じリーク電流ならば、より高速にトランジスタを動かせる」ことになる。
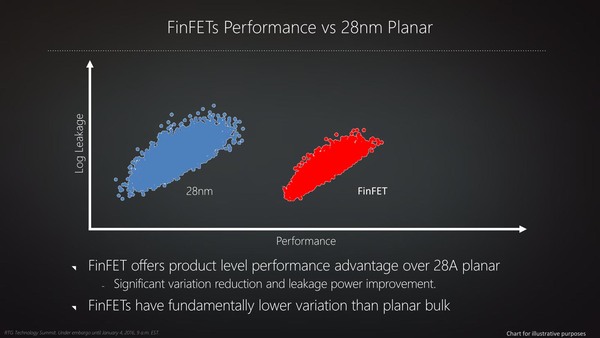
28nm世代との比較。これは概念図に近い上、TSMCの16FF+とSamsung/GFの14LPxを混在したデータと思われるので、FinFETのデータのプロット位置にはあまり意味がないと考えて良いと思う
同じように、28nmと比較して「同じダナミックパワーならば、より高速にトランジスタが動かせる」ともいえる。
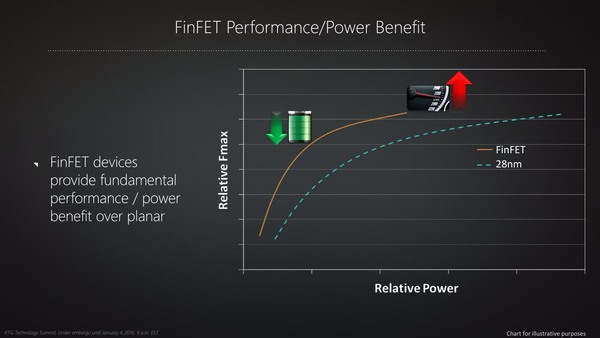
性能/電力費の比較。こちらもグラフは相対的なものである
ただGPUの場合、必ずしも高速にトランジスタが動く必要はない。それは昨今のGPUがいずれも1GHzあたりの動作周波数に留まっていることからも容易に想像がつく。むしろ問題は熱密度である。
とにかく大量のシェーダーを同時に動かすことが性能向上のポイントであり、そのためには大量の回路が同時に動作しなければならない。ところがここで静的あるいは動的な電力が大きいと、単位面積あたりの消費電力が急増することになり、その結果発熱も急増する。
したがってFinFETを利用しつつも、あえて動作周波数を増やさずに留めることで、より多くのシェーダーを同時に動かしても消費電力あるいは熱的に問題ない範囲にとどめよう、というのが基本的な設計目標である。
これを端的にしめしたのがCESにおけるデモである。このデモではGTX950とPolarisベースのGPUを同程度の負荷で動かした場合、消費電力が54Wも削減できることが示された。

数字はCore i7-4790Kベースのシステムで2つのビデオカードを差して、StarWars Battlefrontを1080p/60fpsで動かした際の数字とのこと。それはいいのだが、右下の説明を見るとCore i7-4790K with 4×4GB DDR4-2600 memoryとか書いてあって「?」である。多分DDR3-1600なのではないかと思うが確認は取れていない
この様子はAMD公式のYouTube Videoの2:00あたりから確認できる。正確な数字はわからないが、GeForce GTX 950が90W TDPの構成で、逆算するとCPUその他が50Wということになる。
筆者はGeForce GTX 950でStar Wars Battlefrontの評価を行なった経験はないのだが、海外メディアの評価を見ていると設定がHighの場合にだいたい60fps前後の平均フレームレートだそうだ。
今回のようにMed Presetの環境で動かしたテストでは、ややGPUの負荷は低くなるだろうから、GeForce GTX 950の消費電力はおおむね80W前後ではないかと思う。
だとするとCPUその他が60W程度。そこから推定するとPolarisベースのGPUは26Wそこそこで動作するということになる。
この推定が正しければ、スライドにある“Significant Perf/W improvement”(非常に大きな性能/消費電力比の改善)の文言は、その意味では大げさではないことになる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















