




自由度が高すぎる
チップの配置配線
マザーボードの配線と同じことはチップの配置配線にも言える。論理設計が完了した、というのは回路図ができたという話であって、ここから製品の状態まで持ってゆく作業が配置配線ということになる。こちらも同様に自由度が恐ろしく高いこともあって、配線作業には時間がかかる。これに関しても自動配線ツールは存在するが、必ずしも効率が良くない。はっきり言うと論外に悪い。
やや古い話であるが、下の写真は2006年にTIが公開したF1プロセッサーの内部レイアウトである。当時ARMはまだCortex-A8のHard CoreやPOP(後述)を保持していなかったので、TIはARMからCortex-A8のSoft Coreを購入し、自前で物理実装した。
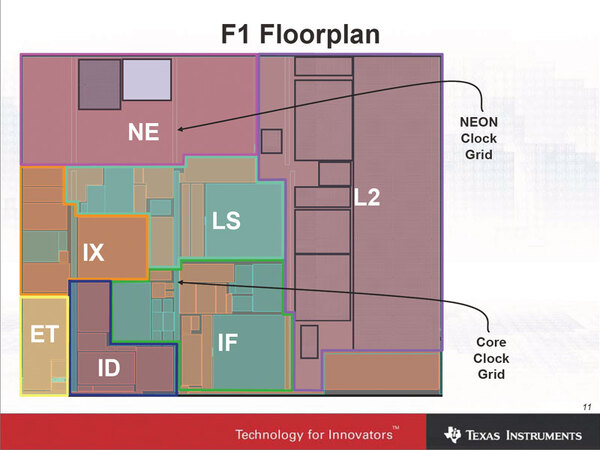
F1プロセッサーの内部レイアウト。2006年5月に開催されたSpring Processor Forumでの発表より。F1というのはCortex-A8プロセッサのTIの社内名称。同社はこのF1をOMAP 3などに搭載している
上の写真がそのF1のフロアプランという、ダイの中にある個々の回路位置であるが、これをどう配線したのかが下の写真である。フロアプランと見比べてもらえるとわかるが、L2キャッシュの実際のデータ保持部やIF(Instruction Fetch:命令取り込み)、LS(Load/Storeユニット)、ID(Instruction Decode)の一部、IX(Instruction eXecution:命令実行)の一部、NE(NEONユニット)の一部など、結構勘所は自動配置配線ではなく手動で配置配線を行なっているのがわかる。
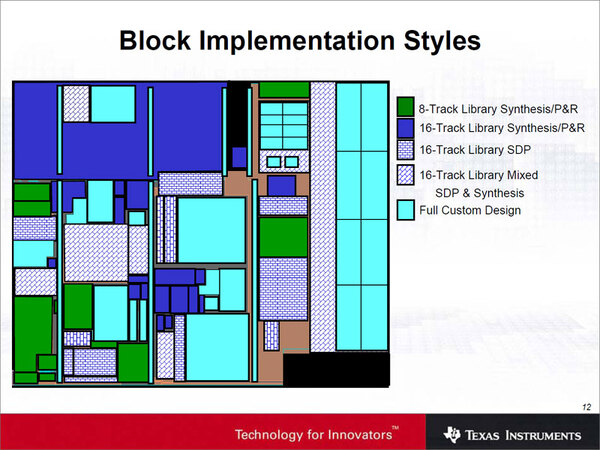
“Synthesis/P&R”が自動配置配線、SDPはStructureed DataPathと呼ばれる、やや自動化(規則化)を行なった配線。最初に人間が配置を決めたうえで、これを繰り返す仕組み。Full Custom Designが手動配線である
一般論としていえば、自動配置配線の効率はどんどん良くなっているものの、それでも熟練したエンジニアによる手動の配置配線に比べると数十%~数百%悪いと言われる。これはダイサイズが数十~数百%肥大する、あるいは配線遅延が発生するからだ。
数字がばらつくのは回路規模と複雑さによってだいぶ変わるかだらだが、オーバーヘッドが発生することそのものは間違いない。従って本当に性能が必要なところでは自動配置配線ではなく、手動で行なうことで遅延の最小化、つまり高速化や省電力化、あるいはダイサイズの最小化などを図ることになる。
もちろんLSI全体を全部手配線にすれば、理論上は非常に効率が良いプロセッサーができるが、今度はエンジニアのコストと手間が馬鹿にならない。以上のことから、性能に直結する場所を選んで手動配線を持ち込むというのが一般的な流れである。
ただそれでも、この配置配線には猛烈な時間がかかる。若干の変更、例えばICH10におけるSATA2ポートの修正は、全体のごく一部を修正するだけだから、ものの一週間もあれば終わるかもしれない。しかし新規のSoC全体になると、なにしろ規模が大きいだけに、数ヵ月~1年程度を要するようになってきている。ちなみにこの物理設計まで終わった段階を「デザイン終了」と称することもある。
設計が終わったら製造
主流はエッチング技法
さてこれが終わったら、マスクの製造である。現在のLSIは基本的にエッチングという技法で製造される。エッチングというのは回路基板の製造以外にもデザインの現場で使われることもあるが、不要な部分を抜くという仕組みである。
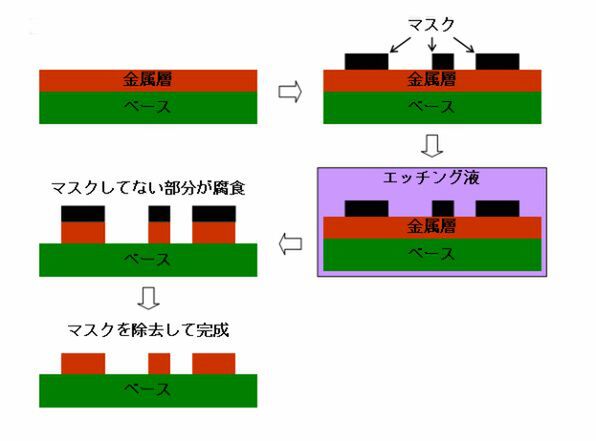
エッチング技法
上図はプリント基板の場合だが、まずベース層の上全体に金属層を張り、その上に回路として残したい部分にマスクを張る。ついでエッチング液を流し込む。このエッチング液は金属の種類によって変わるが、銅の場合だと塩化第二鉄液が使われる。
エッチング液は、金属層のうちマスクがされていない場所を溶かしてくれる。溶かし終わったら引き上げ、水洗いしてからマスクを除去すると、ベースの上に望む回路配線の形になった金属層が残るというわけだ。
LSI製造の場合、まずマスクそのものはシールなどではなく、写真のように配線を金属表面に露光させ、これをマスクとして使う関係で、写真で言うところのネガフィルムにあたるものを作る必要がある。
これを製造するのがマスク製造というわけだが、実際には単に配線そのもの以外にもマスクを使う必要がある。最近はプロセスの微細化にともない、ダブルパターニングという技法も必要になることがもあり、28nmクラスになるとこの枚数がLSIひとつあたり100枚のオーダーになることも珍しくない。
当然これを作るには相応の時間が必要になる。しかもマスクの価格も壮絶で、最近では1枚あたり数千万のオーダーに達するものもある。このマスクが完成した段階を、通常「テープアウト」と呼ぶ。
これは以前、マスクのデータをオープンリール式テープの形でファウンダリーに収めていたことに起因するが、もちろん今では完全にネットワーク化されているので、物理的なテープは利用されておらず、名前だけが残っている形だ。
ここからはファウンダリーの仕事である。まずはマスクにあわせてウェハーに回路を焼きつけ、LSIそのものを構成するのが前工程と呼ばれる部分である。これは回路規模によって必要とする期間が異なるが、大雑把に言ってマスクの枚数が増えるほど所要時間が増える。
以前の180nm前後の世代でも1~2ヵ月かかっていたが、最近の28nmや40nm世代の先端プロセスでは3ヵ月以上、今後投入される20nmや16/14nmではさらに長くなるといわれている。
これが終わると、完成したウェハーを後工程にまわす。ここではウェハーからダイを切り出し、単体テストを行ない、パッケージに組み入れ、最後に製品テストを行なって箱詰めという手順である。前回説明したMCMあるいはSiPといったものは、この後工程の段階で複数のダイを集積、パッケージに収め、テストするといった行程になる。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ










が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

















