




汎用演算性能向上には
GPU側もCPUと一体化する必要がある
その一方でGPU側も、単に3D描画用として使うだけではなく、もっと積極的に汎用的な計算を行なうためのプロセッサーとして、役割を拡大することを考えていた。もちろん、いきなりそちらに移行するのは無理だ。内部構造がそうした汎用演算には向いていないとか、命令インターフェースが独特すぎるなど、GPUの内部に起因する問題もある。
だが、実はそれより根深い問題がGPUの接続である。GPUはグラフィックスカードというI/Oデバイスとして扱われているから、接続はPCI Expressの先になる。そのためGPUは、キャッシュコヒーレンシ性を持たない。これが何を意味するかというと、CPUのキャッシュメモリーから直接データを受け取ったり、逆にキャッシュに直接データを書き込んだり、あるいはキャッシュの更新を同期させることができない、ということだ。
つまり、データは必ずメモリーを経由しての受け渡しが必須になり、これはGPUによるデータアクセスの遅延が、CPUに比べて非常に大きくなることを意味する。グラフィックス演算ではそれほど問題にならないが、GPGPUとして使う場合は何とかしないと、演算効率が上がらないことになる。
ここまでくれば、CPUとGPUをうまく組み合わせることができれば、両方の問題を解決できると容易に想像できる。もちろん、現在のFusionはまだここからかなり遠い場所にいるが、あくまで今はその第一歩という位置づけである。
組み合わせる場合、当然ながら「命令セットはどうなるのか?」という問題がある。これに対するAMDの最初の解は「SSE5」であった。SSE5は当初こそ全部CPUで処理されるが、長期的にはSSE5命令のいくつかを、GPU側でオフロード処理する方式を考えていた。その後、SSE5はインテルのAVXに歩調を合わせる形で発展的解消を遂げるが、完全に消えていないのは「XOP」という形で、AVXに加えて拡張命令を用意したことでも明らかだ(関連記事)。半精度浮動小数点変換など、GPUとの連携を考えなければまず不要な命令だからだ。
CPUとGPUの統合は
GPGPUにとってもいいことずくめ
これらの前提をご理解いただいたうえで、マクリー氏によるFusionの未来像を説明しよう。マクリー氏はまず現行のFusionについて、GPUを内蔵したことで、GPUとメモリー間の帯域が3倍になって遅延が下がった。またパッケージも小型化される(同じサイズならより大きなGPUを統合できる)という具合に、いいことずくめであるとした(写真1)。

写真1 チップセット側にGPUを統合した従来の構造とFusion APUの比較。従来だとGPUがHT Linkを経由してアクセスする構造で、どうしても遅延が多めだった
これはGPGPUの観点でも有利であり、前述の欠点の根本的な解決はまだできていないが、帯域や遅延の改善により、効果的な処理が可能になっている(写真2)。このGPGPUを扱うソフトウェアは、今のところは既存のソフトウェアのままだ。「OpenCL」や「DirectCompute」などのGPGPU用ミドルウェアを経由して、CPUとは別の形で扱うことを想定している(写真3)。
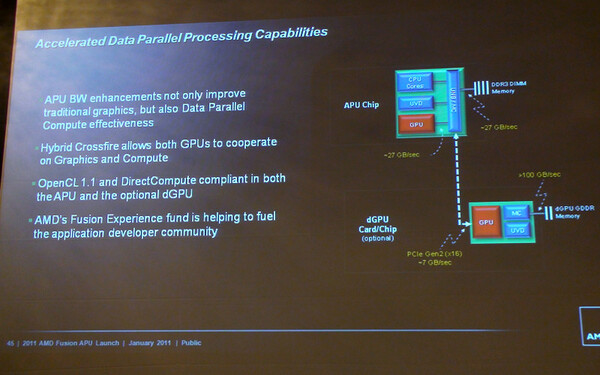
写真2 GPGPUとして使う場合の話。OpenCL 1.1とDirectComputeのどちらもFusionの内蔵GPUのほかに、PCIe経由で外部GPUも使える

写真3 現在のソフトウェアモデル。GPUはあくまでも「ディスプレー」というデバイスで、これをOpenCLやDirectXがデバイスドライバー経由でアクセスする形である
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ










が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

















