




連載108回でも少し触れた話だが、2011年第3四半期中にはAMDから、「Bulldozer」アーキテクチャーを搭載した「Zambezi」こと、「AMD FX」シリーズが投入される予定だ。今回はこのBulldozerアーキテクチャーの内容について解説しよう。
2コアでFPUを共有する
Bulldozerアーキテクチャー

Bulldozerコアの概略図。2010年8月に開催された「HotChip 22」での講演資料より引用。スライド画像は以下同
Bulldozerの特徴は、2つのCPUコアをモジュールという単位でまとめ、FPUはモジュール単位で1つを共用する構造になっていることだ。ちょっとわかりにくいので、一般的なCPUコアの構造と比較してみた。図1は共有2次キャッシュを持つ一般的なデュアルコアCPU(強いて言えばBobcatに近い構成)だ。これがBulldozerではどう変化したかを示したのが図2である。要点は以下のようになる。
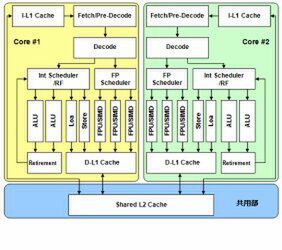
図1 一般的なデュアルコアCPUの構造
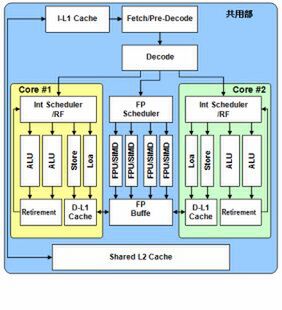
Bulldozerアーキテクチャーの構造
- フロントエンドの1次命令キャッシュや命令TLB、フェッチ/デコードは2つのコアで共用する
- 整数演算のスケジューラー~実行ユニット、Load/Storeユニット(図では省略)、データTLBなどはコアごとに用意
- FPUはスケジューラーを含めて共用
こうした構成をとることについて、AMDはいくつかの理由を挙げている。まずは「ダイサイズの効率化」である。FPUブロックは浮動小数点演算を本格的に処理するようになったことで、大きなダイサイズを占めるようになった。ところが実際の使われ方を見ると、それがフルに使われることは極めて稀である。科学技術計算など一部の用途を除くと、ほとんどの場合FPUは無駄に遊んでいることになる。「ならば、2つのコアで共用にしても実質的に性能にはほとんど影響がない」と判断した結果が、FPUの共用部分への追い出しである。
これにより、2つのメリットが生まれた。ひとつは「AVX」互換の256bit FMAC命令を実装しても、ダイサイズへの影響が軽微な事である。AMDはSSE5をあきらめてAVX互換命令を採用した話は、2年ほど前の連載25回で説明している。AVXではレジスター長が増えたのみならず、かなり多くの命令が追加されている。これを実装するためには、FPU側の実行ユニットも肥大せざるをえない。
ところがBulldozerでは2コアでこれを折半することになるので、コアあたりの面積ではそれほど大きなインパクトはない。「K10」(Phenom II、Athlon II)までの世代では、コアごとに「FPU/MMX/SSE1~3」の実行ユニットとスケジューラーを用意していた。それに対して今度は2コアで共用だから、FPU関連の面積は半減する。トータルではK10世代のFPUとさして変わらないダイサイズのままで、AVXまでの対応が可能になったわけだ。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")



















