このところ機械学習の成果を利用可能にするCore ML関連のフレームワークを使っています。前回は、Core MLを間接的に利用するVisionを使って、写真に含まれる人の顔と、顔の中の構成要素を認識するプログラムを書いてみました。
その際に入力するのは画像データだけで、あとはまったく自動的に顔の位置と、目鼻口などのパーツの位置、形状が座標として出力されてきました。しかも、その認識はかなり的確でした。それも、あらかじめ機械学習された成果を、Visionを経由したCore MLによって手軽に利用できるようになっているからです。
今回もVisionを使いますが、認識させるのは人の顔ではありません。今回は画像に含まれる文字を認識させます。Visionによる文字の認識は、まず単語単位で認識し、その後、その単語を構成する文字を認識するというパターンになっています。
ただし、ここで言う「単語」や「文字」というのは、基本的に英語などの欧文を想定したものです。そのため単語をスペースで区切らない日本語などの単語は、期待どおりには認識できません。それでも、単語の区切りを無視して考えれば、個々の文字は、ある程度の確度で認識できます。
Visionによる文字認識も、一般的には撮影した写真に含まれる看板などの文字を対象としたものと思われますが、雑誌や本をスキャンしたような画像でも機能を発揮できます。今回は、例によって週アスの表紙画像でトライしてみましょう。
Visionを使って単語と文字を識別する
前回のプログラムでは、顔の位置を表す長方形と、その中にある顔のパーツの輪郭線のパスを認識させ、それらを元の画像の上に線として描き込んでみました。それと同様のことを、今回は単語とその中に含まれる文字でやってみることにしましょう。単語の位置は、顔全体と同じように長方形で認識されます。文字は顔のパーツとは異なり、これも長方形で示されます。そのため、輪郭を描画するのは前回よりもずっと簡単です。
プログラムの構成は、前回とほとんど同じなので、ことなる部分だけを簡単に説明しておきましょう。
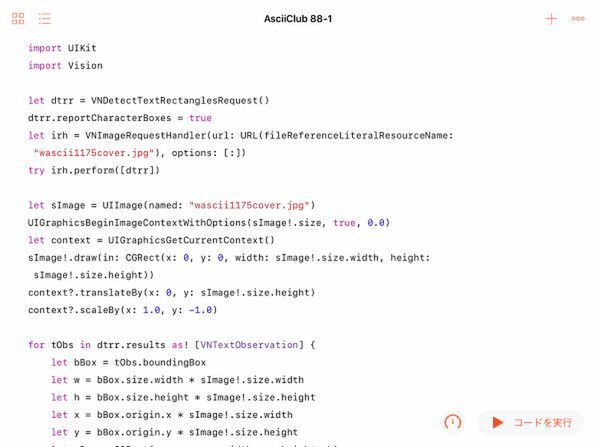
今回は検出のリクエストとして、VNDetectTextRectanglesRequestクラスを利用してテキストを囲む長方形を検出します。さらにその中の個々の文字も認識できるように、reportCharacterBoxesのプロパティをtrueに設定しています。デフォルトはfalseです
まず明確に異なるのは、Visionに対する認識リクエストのクラスです。前回の「顔の長方形」ではなく、「テキストの長方形」を表すVNDetectTextRectanglesRequestにします。そして、単語だけでなく文字まで認識させるために、そのクラスのオブジェクトのreportCharacterBoxesというプロパティをtrueにセットしています。
認識のリクエストについて異なるのはそれだけです。結果の処理についても、前半は前回とほとんど同じです。まず顔の長方形だったところが単語の長方形として返ってくるので、その外形線を描きます。
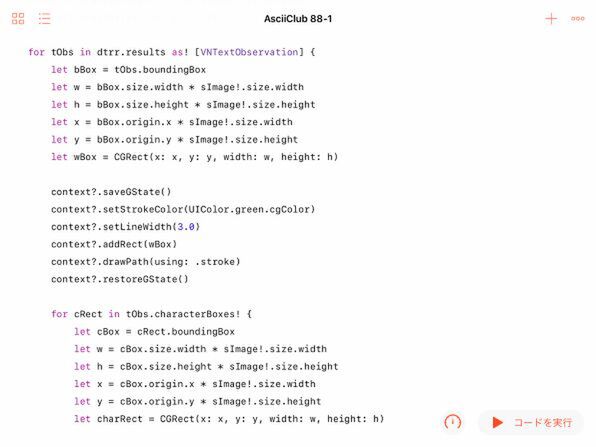
まず単語単位で認識した長方形を得て、さらにその中にある文字を認識した結果の長方形を得るという二重構造は、前回の顔の長方形とその中のパーツとの関係に似ています
結果の配列は単語単位で1つの要素になっていますが、その中にcharacterBoxesというプロパティが含まれてます。そこには個々の文字を囲む長方形の配列が入っています。その中から要素を1つずつ取り出して、個々の文字を囲む枠の長方形を描きます。
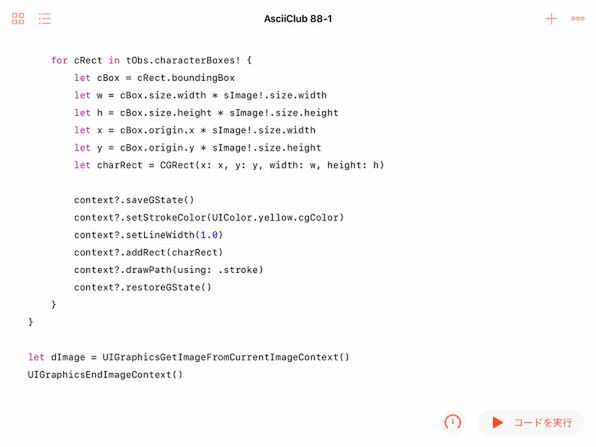
個々の文字の認識結果も長方形(boundingBox)として出力されるので、それを画像の上に描くのは簡単です。ここでは太さ1ポイントの黄色い線で描いています
今回も結果はプレイグラウンドのデバッグ機能で確かめましょう。

実際の認識結果は、プレイグラウンドのデバッグ機能で画像を表示して確認しましょう。背景が一様に塗りつぶされている部分は比較的認識しやすいのですが、人物の上に直接乗っている文字は認識できていません
これを見ると、以外に認識していない文字が多いと思われるかもしれません。それでも、背景が一様になっている部分については、日本語の漢字やひらがなも含めて、連続して認識できていることに気付くでしょう。背景に人物が被っているような部分は、やはり厳しいようです。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
- 第100回 SceneKitの物理現象シミュレーションとアニメーションをARKitに持ち込む
- 第99回 「物理学体」と「物理学場」を設定して物理現象をシミュレーション
- 第98回 SceneKitのノードに動きを加えるプログラム
- 第97回 いろいろな形のノードをシーンの中に配置する
- 第96回 SceneKitの基礎シーンビュー、シーン、ノードを理解する
- 第95回 現実世界の床にボールや自動車のモデルを配置する
- 第94回 ARKitを使って非現実世界との融合に備える
- 第93回 ARKitが使えるiPadを識別するプログラム
- 第92回 Swift Playgrounds 2.1での問題点をまとめて解消する
- 第91回 iPadの内蔵カメラで撮影した写真を認識するプログラム
- この連載の一覧へ