



ロードマップでわかる!当世プロセッサー事情 第796回
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
2024年11月04日 12時00分更新

5種類のモデルが存在するMTIA v1
それぞれのPEはメッシュ構成で接続されているそうで、これを踏まえると個々のPEの内部は下図のような構成になっているはずだ。
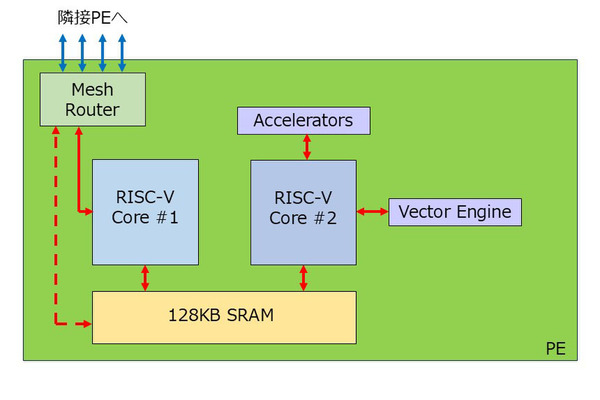
PEの内部構造図
演算の主体となるRISC-V Core #2は、CPUというよりはDSP的に、ひたすらVector Engineとアクセラレーターをブン回し、演算結果をまたSRAMに戻す格好であろう。1サイクルあたり2KBのデータを読み込んで書きだす格好になるので、128KBなら最大で32サイクル分のデータを格納できることになる。演算前と演算後、両方のデータをSRAMに保持するためだ。実際にはウエイトの分などもあるので、もう少し数は減るだろう。
この演算後のデータをほかのPEに送り出したり、新しいデータを読み込んだりというのはRISC-V #1の方が担当する。おそらくはDMA Engineも持っており、これでメッシュルーターとSRAMの間で直接データ交換ができる(図中の赤の破線のルート)ものと思われる。
ちなみにMetaによればこのプロセッサーはTLP(Thread Level Parallelism)とDLP(Data Level Parallelism)の両方をサポートしているそうで、RISC-Vはどちらもイン・オーダーながらマルチスレッドをサポートしているのかもしれない。
MTIAの内部構造に戻ると、64個のPEを囲むように、32個の4MB SRAMブロックが配されており、合計128MBとなる。その外にはLPDDR5のI/Fが搭載され、容量は最大128GBとされている。上図では16のブロックになっているから、おのおのが16bit幅。実際には容量128Gbitで64bit幅のLLPDDR5チップを4つ接続する形だろうか?
例えばSamsungであれば、128Gbit品がすでに量産に入っており、速度は最大6400Mbpsとされる。これが256bit幅だからメモリー帯域は204.8GB/秒というところで、性能や消費電力を考えれば悪くない帯域と言える。最終的にはデュアルM.2ボードに搭載され、ホストとはPCIe Gen4 x8で接続。消費電力はボード全体で35Wとなっている。

これはテスト用ボードに搭載されたMTIA v1
MetaではこのMTIA v1カードをYosemite V3ブレードに装着する。Yosemite V3ブレードはデュアルM.2カードを2枚装着可能だが、MTIA v1カードはブレードあたり1枚に留め、残るデュアルM.2のスロットはPCI Express Switchの接続に利用しているとのこと。
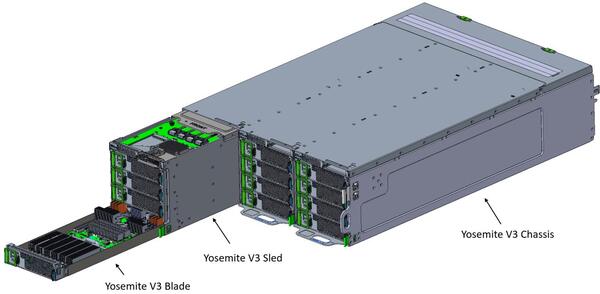
Yosemite V3の仕様はopencompute.orgにまとめられている。ブレードの手前にヒートシンクが6つ並んでいるが、これは拡張カードのエリアでこのヒートシンク(の下にある拡張カード)を抜いて、MTIAボードを装着する格好だ
1本のYosemite V3シャーシ(4U)には12枚のYosemite V3ブレードが装着でき、通常1本のラックにはこのシャーシを8本装着するので、ラック1本にMTIA v1が96個搭載される格好だ。なお内部構造の写真右下にあるアクセラレーターは制御専用のユニットで、システム全体のファームウェアが実行され、ホストとの通信やPEへのジョブ制御などをつかさどると説明されている。
GPUがなにか、に関しての説明はないのだが、A100かH100のどちらかだろう。なんとなくA100な気はする
冒頭でも少し触れたがMTIA v1はMetaのRecommendation Engineの置き換えを目的としている。もっともRecommendation Engineと一口で言っても、Metaの内部では複数のRecommendationのシステムが利用されている。説明では5種類のDLRM(Deep-Learning Recommendation Model)があり、それぞれの特徴は以下のようになっている。
| 各DLRMの特徴 | ||||||
|---|---|---|---|---|---|---|
| サイズ | 複雑さ | |||||
| Low complexity 1 | 53.2GB | 0.032GFlops/batch | ||||
| Low complexity 2 | 4.5GB | 0.014GFlops/batch | ||||
| Medium complexity 1 | 120GB | 0.140GFlops/batch | ||||
| Medium complexity 2 | 200GB | 0.220GFlops/batch | ||||
| High complexity | 725GB | 0.450GFlops/batch | ||||
複雑さというのは、その処理を実効するのにどの程度の能力が必要かの目安で、これが高いほどbatch(推論1回分の処理)に時間がかかる計算だ。
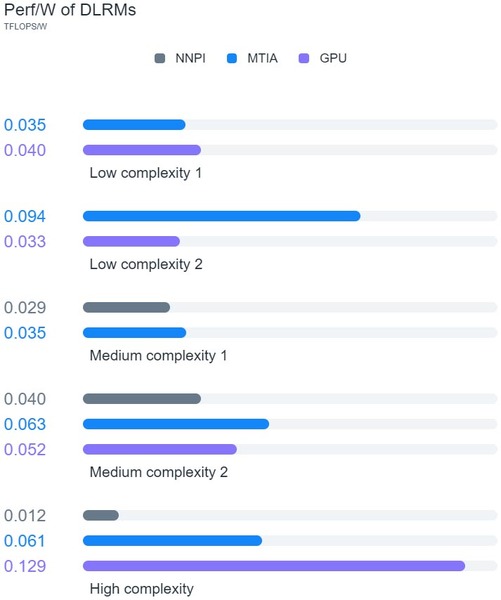
Metaはこの5種類のDLRMを、MTIA v1とNNP-I、それとGPUを利用してそれぞれ実施したそうで、その結果が下の画像である。NNP-Iというのは、インテルが放棄してしまった旧Nervana Systems由来のSprint Hillのことである。どうもMetaはNNP-Iをけっこう導入していたようだ。
結果を見ると、Low complexity 1ではGPUにやや負けているし、High complexityでは半分以下の効率なので、万能ではないものの、Low Complexity 2やMedium ComplexityではGPUやNNP-Iを凌ぎ、一番性能効率が高い結果を得られたとしている。
言うまでもなく昨今のAIをベースにしたサービスのボトルネックは電気代であり、少しでも電力効率が改善されるのであれば長期的には十分採算が合うものになる。万能ではないにせよ、自社のサービス向けには十分役に立つチップとなったわけだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























