





筆者が、Stable Diffusion 3 Mediumで出力した画像
6月12日、Stability AIの画像生成AI「Stable Diffusion 3 Medium(SD3M)」が公開されました。Stability AIは安定的な収益につながるビジネスモデルの構築に課題を抱えており、最新シリーズ「Stable Diffusion 3(SD3)」をどう位置づけるかが生命線と思われます。そこで、有料APIの使用が必須という形で性能の高い「Stable Diffusion 3 Large(SD3L)」を先行リリースしていました。SD3を「オープン化する」とX上で発言していた創業者のEmad Mostaque氏が4月にCEOを退任したことで約束は守られるのか……とも危惧されてきました。結果としてStability AIは、品質を落としたSD3Mを出すという判断をしてきました。しかし、SD3Mはライティングに高い表現力を持つ一方、意図的に落とされた品質に大きな課題が発見されており、普及が進むのか見えない状況になっています。
文章のように複雑なプロンプトも的確に理解
Stability AIはSD3Mを「生成AIの進化における大きなマイルストーン」と位置づけ、「強力なテクノロジーを民主化するという当社の取り組みを継続するもの」としています。ライセンスとしては、非商用向けの無料ライセンスと、売上が100万ドル以下などの条件が付いた月20ドルのクリエイターライセンス(商用ライセンス)が用意されています。それ以上の収益を得る企業の場合は別途ライセンス契約を結ぶ必要があり、その料金は明らかにされていません。
そもそも、Stable Diffusion 3の画像生成の方法はこれまでとアーキテクチャーが大きく異なっています。過去のStable Diffusionモデルでは、画像処理に特化した拡散アーキテクチャー「U-Net」が使われていました。それがSD3では自然言語処理で成功を収めたTransformerベースのモデルに移行し、「Multimodal Diffusion Transformer (MMDiT)」と「Rectified Flow」という新しい仕組みを採用しています。
MMDiTは、テキストと画像とを同時に扱うことが得意で、より複雑な文章のプロンプトを書いても、それを適切に読み解き、画像化する能力が高い技術とされています。Rectified Flowは、ノイズ除去プロセスを改善した手法で、これまでよりも高品質な画像が出力可能です。SD3はこれにより、長文のテキストプロンプトを入力しても、それに合わせた適切な画像を生み出せることを強みとしてアピールしています。
SD3がこうしたアーキテクチャーを採用したのは、複数の種類のデータ(モダリティー)を組み合わせて理解・処理できるマルチモーダルAIを目指して開発されたためです。画像だけしか扱えないAIから文字などの複数のデータを理解・処理できるようにすることで、今後応用範囲を広げていくことが目指されています。
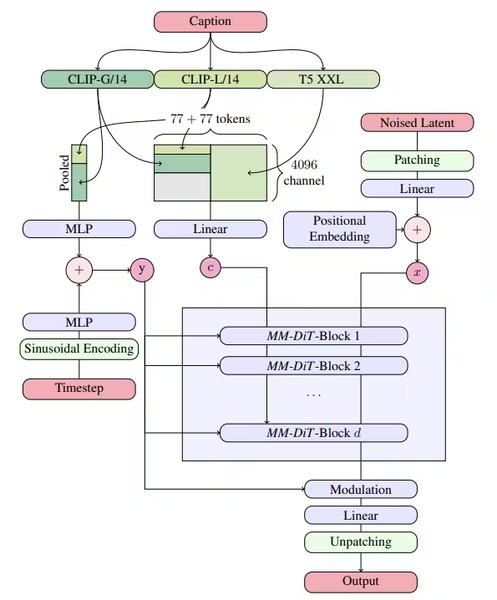
SD3の生成過程の概念図。プロンプト(Caption、キャプション)の入力を受け、2つのCLIPと1つの言語モデルで処理され、画像を生成するための概念へと変更される。新しいアーキテクチャのCLIPのT5 XXLが言語認識能力を向上させている(Stable Diffusion 3: Research Paperより)
実際に、テキストの理解は非常に強化されています。
公式にサポートされている実行環境のアプリ「ComfyUI」向けにサンプルとして公開されたWorkflowを見ると、テキストによりプロンプトを入力すると、テキストを画像化するうえで処理をする2つのクリップと1つの言語モデルで分析する仕組みになっています。特にSD3は、Googleが公開している「T5 XXL」という言語モデルを使うことで、複雑な文章を入れてもしっかりプロンプトに追従してくれるようになっています。これまでのStable Diffusionでは通常、クリップは1つでした。プロンプトも「a girl, black hair」などの単語を並べていくことが中心でしたが、SD3ではかなり複雑な文章で指示しても、文脈を踏まえて画像を生成してくれるようになったのです。
ただ、このT5 XXLのサイズが半端なく大きくて、圧縮率の低いものが10GB、もしくは15GBもあり、もっとも圧縮した基本のものでもファイルで5GBあります。SD3Mで小さな言語モデルと学習データ本体を使用するように設定するだけでVRAMが最低12GBくらい必要となります。なので、そのために、SD3Mを動かすための要求されるPCスペック水準は高いですね。SD3Mの画像の学習済みデータの本体ファイルが4.34GBなので、必要とされる言語モデルのほうが大きいくらいです。
なお、SD3Lは80億パラメーターを持つとされていますが、Mediumは20億パラメーター。ファイルサイズはSDXLの6.94GBよりも小さいサイズになっています。
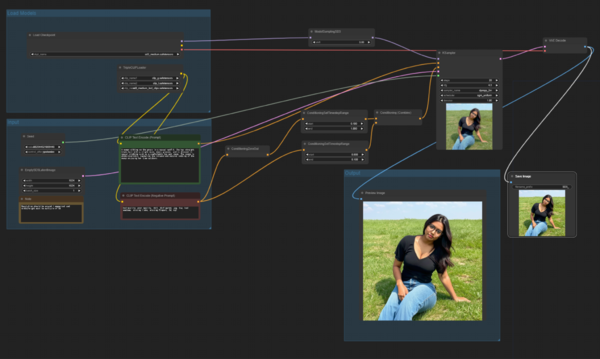
ComfyUIのサンプルのワークフロー。スペックを満たすローカルPC環境があれば、導入自体はそれほど難しくない。画像のセーブ機能がついていなかったので、独自に追加している
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第150回
AI
無料でここまで? 動画生成AI「LTX-2.3」はWan2.2の牙城を崩すか -
第149回
AI
AIと8回話しただけで“性格が変わる” 研究が警告する「おべっかAI」の影響 -
第148回
AI
AIが15万字の小説を1週間で執筆──「Claude Opus 4.6」が示した創作の未来 -
第147回
AI
ゲーム開発開始から3年、AIは“必須”になった──Steam新作「Exelio」の舞台裏 -
第146回
AI
ローカル音楽生成AIの新定番? ACE-Step 1.5はSuno連携で化ける -
第145回
AI
ComfyUI、画像生成AI「Anima」共同開発 アニメ系モデルで“SDXL超え”狙う -
第144回
AI
わずか4秒の音声からクローン完成 音声生成AIの実力が想像以上だった -
第143回
AI
AIエージェントが書いた“異世界転生”、人間が書いた小説と見分けるのが難しいレベルに -
第142回
AI
数枚の画像とAI動画で“VTuber”ができる!? 「MotionPNG Tuber」という新発想 -
第141回
AI
AIエージェントにお金を払えば、誰でもゲームを作れてしまうという衝撃の事実 開発者の仕事はどうなる? -
第140回
AI
3Dモデル生成AIのレベルが上がった 画像→3Dキャラ→動画化が現実的に - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















