




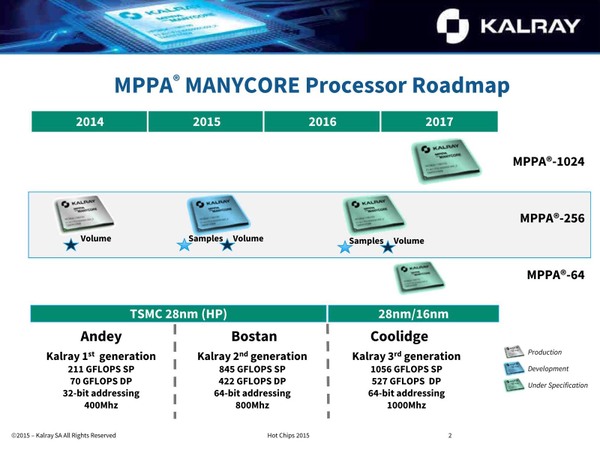
2015年にBostanをサンプル出荷
Bostanコアの詳細が下の画像だ。ALU×2、MAU(MAC Unit)×1、LSU(Load Store Unit)×1、コプロセッサーの5命令の同時実行が可能な構成で、パイプラインは最大7ステージである。分岐は3サイクル程度で処理できる。
Bostanの場合、データパスは原則32bitで、64bitデータは32bitレジスター×2をペアにして格納する形になっている。ALUは当然整数演算なので、浮動小数点演算はMAUを使って処理する格好だ。このALUが一番パイプラインが長く、実行に4サイクルかかっている。とはいえスループットそのものは1なので、けっこうな処理速度ということになる。
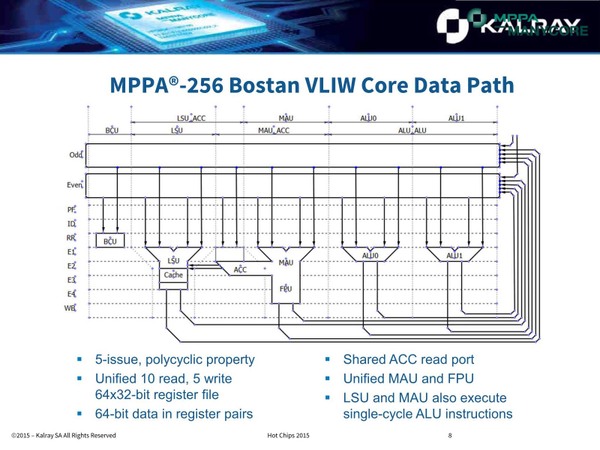
図がわかり難いのだが、例えばMAUの場合Odd BankとEven Bankからそれぞれ3本づつのパスが伸びている。Y=AXB+Cを計算する際に必要となるA・B・CがこのEven/Odd Bankから供給されるわけで、つまり1つのMAUでは同時に2つのMAC演算が可能になる仕組みだ。これはALUも同じで、要するに1サイクルあたり4つの32bit演算(あるいは2つの64bit演算)が可能である
結果として、600MHz駆動のコアであればMAC演算を1サイクルあたり2つということで2.4GFlopsという計算になる。ちなみにBostanではコプロセッサー命令は暗号化/復号化やCRCなどの命令に割り当てられている。
さて、KalrayではこのBostanを2014年にテープアウト、2015年にサンプル出荷を開始している。製造はTSMCの28nm HPで、600MHz動作で634GFlopsを25Wで実現する。ちなみに256コアだと634GFlopsではなく614GFlopsになるはずなので、634GFlopsというのは計算用ではなくマネジメント用の16コアのうち半分の8コアも計算にまわした264コア構成での数字のようだ。
1Wあたりの処理能力は25.36GFlopsになり、これは例えばインテルのXeon Phi(2147GFlops/300Wで7.16GFlops/W)やNVIDIAのTegra 4(75GFlops/8Wで9.38GFlops/W)などと比べてもおそろしく性能消費電力比が高い数字となっている。
実はこのBostanに先立ち、2013年にテープアウト、2014年に量産を開始したAndeyという第1世代のMPPAチップがあった。
2015年当時の製品ロードマップ
こちらは32bitアドレスだし、コアの数は同じながら1サイクルあたりの処理性能はBostanの半分程度だったようだ。BostanはこのAndeyをベースに規模を倍増させ、動作周波数を引き上げたモデルということになる。これに続き、第3世代のCoolidgeの設計に入っている、というのが2015年における状況だった。
多くのサードパーティーがソフトウェアを提供
MPPAのもう1つの特徴がソフトウェアのサポートである。2015年の時点でNode OSという独自のOSとSMP Linux、サードパーティーのRTOSが提供されたほか、GNU C/C++とデバッガー/トレーサー、さらにOpenCLでのプログラミング用ライブラリーと、必要に応じてDSPスタイルのLow Level Programming Language(要するにアセンブラ+α)が提供されている。
サードパーティーのRTOSとしては、日本のイーソルがeMCOSというOSを提供したほか、ERIKA Enterpriseという車載システム向けのRTOSが移植されている
ちなみにSMP Linuxは、下の画像で言えば、全体の四隅にある“Quad core”と書かれた制御用の4コアのどれか1つで動作し、I2CやSPI、GPIO制御用のドライバーなども提供される。残りの3つのQuad coreは、メインの計算用CPUクラスターの制御に利用される格好だ。
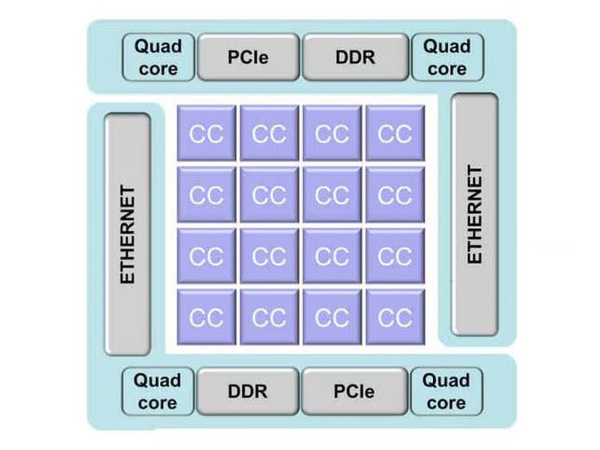
前掲のBostanの概要画像から、一番左側の図を抜き出したもの。SMP Linuxは、全体の四隅にある“Quad core”と書かれた制御用の4コアのどれか1つで動作する
そのメインの計算用CPUクラスター(というより各々のコア)上では独自のNode OSが動く格好だが、これはPOSIXのThreadをサポートし、GCCベースのOpenMPを利用してのコア間の同期なども取れる。なお、1コアあたり1スレッドでの動作となっている。
この連載の記事
-
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 - この連載の一覧へ

















の1台が今ならオトク!")



























")













