




今回はフランスKalray社のMPPA(Massively Parallel Processor Array)を紹介したい。フランスのプロセッサー会社というのはそれほど数が多くはないが、Kalray以外にも独自プロセッサーIPから最近はRISC-Vに鞍替えしたCortus S.A.S.などがあるし、2014年に同じフランスのAtoSに買収されたが、Bullというコンピュータメーカーもあった。
古い話ではACRIなどもあるため、フランスの会社がすごく珍しいわけでもない。そしてKalrayは意外にも老舗であり、実は日本でもけっこうがんばって販売しようとしていた。

KalrayはもともとCEA(Le Commissariat à l' énergie atomique et aux énergies alternatives:フランス原子力・代替エネルギー庁)のFrench Labから独立する形で2008年に創業したメーカーである。
当初のCEOはJoel Monnier氏で、当時STMicroelectronicsのCorporate Vice Presidentからの転職で、2018年の株式上場にともない現在のEric Baissus氏にバトンタッチするまでCEO職を務めていた。
リアルタイムで処理ができて
プログラミングが容易なプロセッサーを開発
Kalrayは当初、データプロセシング向けのスペシャル・プロセッサーを開発していた。もともとCEAのラボの時代から、どうも大量のデータをリアルタイムで処理できるようなプロセッサーを研究していたようで、2015年のHot Chipsでは同社のMPPAの目的を「Time-Critical Computing(実時間処理)が可能ながらプログラミングが容易なプロセッサー」としている。

time-critical computingとHigh Level Languageでのプログラミングが、既存の製品では両立しないのが問題という話。それは良いが、一番下にIntel MICが出ているあたりが2015年という時期を感じさせる
当時のことなので、まだFPGAはVerilogなどの専用言語が必要で、DSPもまだCなどの高級言語で記述というのは難しく、その一方でGPUやメニーコアプロセッサーではTime-critical Computingは難しいというわけで、この境目を狙った格好である。
ここで言うTime-Critical Computingというのは、要するに「ある一定の処理が、一定の時間で処理可能であることを保証できる」仕組みである。

Time-Critical Computingの説明。下に出ている「軍需航空や自動運転、金融取引、物理制御、ロボットや設備制御」などが主な用途だが、元はCEAということを考えると最初のターゲットは発電所のシステム管理などを狙ったのではないかという気もする
この「一定の時間」というのが難しいところで、例えば「1分以内の制御」なら、GPUやIntel MICなどでも間に合うはずだ。ところが「1秒以内」と言われると「たぶん大丈夫だけど、たまに怪しいことがある」となり、「ミリ秒以内」になると「保証はできない」ということになる。
どのあたりに狙いを定めるかだが、“Execution timing issues”で投機実行や分岐予測、あるいはコア間のリソース(キャッシュ/バス/デバイス)の競合、Cache turbulenceなんていう項目まで出てくるあたり、MPPAはミリ秒~マイクロ秒以内のTime-Critical Computingを狙ったものに見える。
この結果としてMPPAは、DSP風の演算ユニットを、C/C++などの高位言語でプログラム可能で、しかも多数のコアを同時に動かすという構成を取ることになった、としている。

MPPAの概要。このあたりはわりと良く見かける話である。実装がうまくいくかはまた別の問題だが
こうしてできあがったのが、同社の第2世代のMPPAであるBostanプロセッサーことMPPA-256である。VILWにすることでIn-Orderのまま命令を同時に多数実行できるし、Out-of-Order実装にともなう不確実性(実行までの時間が不定になる)は避けられるし、メカニズムそのものも簡単になるので、多数のコアを集積する際にダイサイズの肥大化を抑えられる。
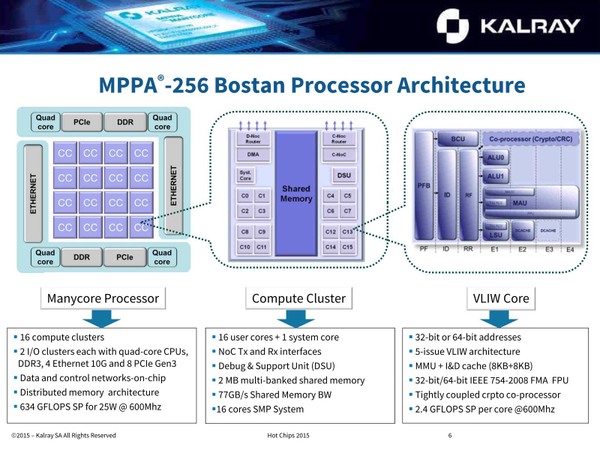
BostanことMPPA-256の概要。ベースのコアはVILWで、このコアを16個集積したクラスターをさらに16個集め、それぞれをNoC(Network on Chip)でつないだのがMPPA-256となる。ちなみにBCUは命令数には入っていない
コアそのものは8KB L1 I+Dキャッシュしか搭載しないが、これを16コア集めたクラスターでは2MBの共有メモリーが搭載されている。コアあたり128KBという計算になるから、L2キャッシュ代わりとして利用するには十分だろう。外部I/FはDDR3とPCIe Gen3、10Gイーサネットであるが、2015年という(Bostonのテープアウトは2013年だった)ことを考えれば妥当な構成である。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ














ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")
















