



ロードマップでわかる!当世プロセッサー事情 第667回
HPですら実現できなかったメモリスタをあっさり実用化したベンチャー企業TetraMem AIプロセッサーの昨今
2022年05月16日 12時00分更新

MAC演算を高速化するだけでAI処理が可能
ではメモリスタを使ってどうAI処理を行なうか? であるが、理屈は簡単である。そもそもAI処理の大半はMAC(Multiply-Accumulation)演算というのはこれまでも何度か説明した通り。畳み込みのほとんどがMAC演算なので、これを高速化するだけで大幅に性能が上がる。
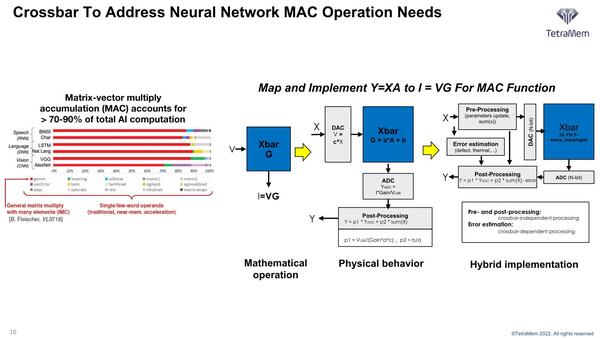
理屈で言えばDAC(Digital Analog Converter)でデジタル信号を、これに比例したアナログ電圧に変換。計算処理後にADC(Analog Digital Converter)経由でデジタル信号に戻すだけだが、やはりここで多少誤差が出るのは避けられないので、エラー補正回路などは必要になる
そしてMAC演算というのは要するにY=A×X+Bである。ここでAが係数(畳み込みニューラルネットワークならウエイトにあたる)、Bがオフセットである。ところでこのAだが、メモリスタはセル1つで11bit分(2048段階)の記憶レベルを持つ。なので、ウエイトの値をメモリスタに記憶しておけば良い。
メモリスタは先に書いたように「流れる電流に応じて抵抗値が変わる」ので、逆に記憶を固定しておけば「一定の電圧をかけた際に流れる電流が、その記憶の値によって決まる」ことになる。したがって、X(つまり入力値)に比例した電圧Eをかけた場合、流れる電流値はオームの法則により以下のように計算する。
I=E÷R(R:メモリスタの抵抗値)
ここでRの値を1÷ウエイトとなるように設定すれば、以下のようになる。
I=E×ウエイト
Eが入力値であればこれで自動的にMAC演算の前半の乗算が完了する。あとはBの分のオフセットを足してやれば、MAC演算が完了するというわけだ。
この仕組みは、MythicのNANDフラッシュを使った場合とまったく同じである。異なるのは、Mythicの場合は8bit分の記憶を1つのNANDフラッシュセルでは保持しきれずに2セルを使っていたが、TetraMemではこれを1つのメモリスタセルで実現している。
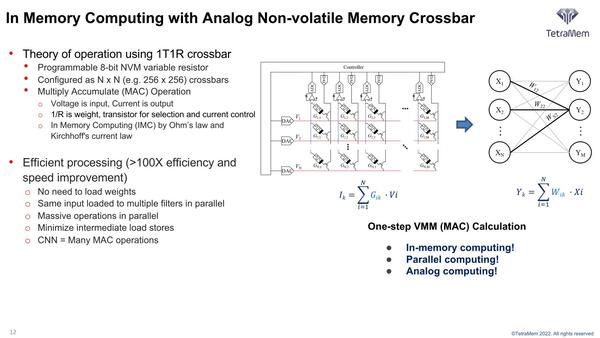
構成模式図。構図自体はMythicのものと非常に近いというか、原理そのものは同じなので当然同様のクロスバー構造になる
TetraMemはまず2019年に小規模なサンプルチップを製造。2020年にはやや大型化、2021年には大規模化したうえ、制御用のRISC-Vコアなどを搭載して、いよいよAIプロセッサーらしくなった。

理論上は11bit/セルであっても、実装するとなるとDAC/ADCの解像度などと合わせて難しいものがあったので、まずは比較的テストしやすい6bit/セルからスタート、2021年のものは広く利用されている8bitニューラルネットワークにあわせて8bit/セルでの試作となったのだろう
クロスバーそのものは256×256の規模なので、64K演算が1サイクルで可能になるが、システムではこのクロスバーを複数個搭載するような構成だとする。
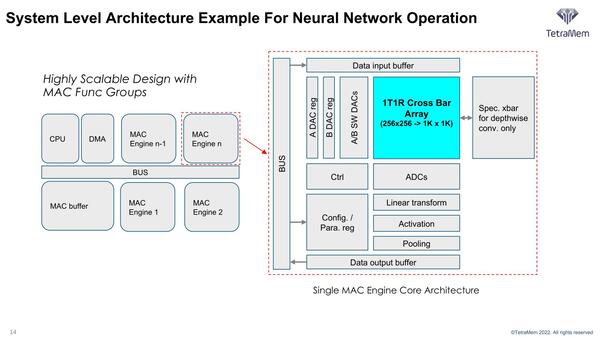
上の画像ではCrossbar、つまりここで言うMAC Engineが5つ搭載されているとする
すでに65nmプロセスを利用したテストチップで400MHzまでの動作は確認しており、実測値で最大25TOPS/Wが確認できたとしている。

右下のテーブルは、今年のISSCCで発表された他のIn-Memory Computingでの結果をまとめたもので、40nmフラッシュを使ったもので5.2TOPS/W、28nm SRAMで27.3TOPS/W、4nmの試作チップで11.59TOPS/Wとされる
現状はまだ65nmという古いプロセスを使ってこの成果であり、今後22nm(TSMCの22ULPあたりだろうか?)を使えば60TOPS/W、14nm(SamsungないしGFの14LPPあたりか?)を使えば100TOPS/Wが狙える、というのがTetraMemの説明である。
問題はこうした先端プロセス上でメモリスタをどう構築するか? というあたりであるが、そのあたりは特許との絡みもあってか今回は説明されなかった。ただHPですら実現しきれなかったメモリスタをあっさりベンチャー企業が採用して、しかも高性能なAIプロセッサーを実現できそう、というのはなかなか興味深い取り組みであると言える。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















