



ロードマップでわかる!当世プロセッサー事情 第667回
HPですら実現できなかったメモリスタをあっさり実用化したベンチャー企業TetraMem AIプロセッサーの昨今
2022年05月16日 12時00分更新

今回はIntel Visionの話でも、と思ったのだがオンラインでの情報配信は5月18日からと発表の1週間遅れになっており、現時点では基調講演くらいしか説明する内容がないので後送りにさせていただき、AIプロセッサーの話をしよう。Linley Spring Processor Conference 2022で発表されたTetraMemのmemristor(メモリスタ)だ。

メインメモリーだけで演算処理を行なう高速化技術
In-Memory Computing
AI処理の効率化、というテーマでのアーキテクチャーの提案はいろいろあることについてはこれまでいくつか紹介してきたが、その1つにIn-Memory Computingがある。
要するにメモリーと演算器が別々に置かれており、かつ演算にあたっては「メモリーからデータを取り出す」「演算結果をデータに格納する」にそれぞれ無駄に消費電力がかかる(データの移動には相応の電力を要する)ので、昨今では演算処理そのものよりもデータ移動の方が消費電力が大きくなってしまっている。
ならば、メモリーと演算器を融合させて一体化してしまえば、無駄なデータ移動がなくなり省電力化できる=性能/消費電力比を大幅に向上できる、という仕組みだ。SamsungのHBM-PIM(連載606回と連載636回)はこの最右翼だし、連載591回で紹介したMythicもこれに近い。
ただSamsungのHBM-PIMは、物理的には近い(なにしろ演算器とDRAMが同じダイ上に混在している)とは言え、演算器とメモリーは別のブロックになっているので、かなりIn-Memory Computing「っぽい」とは言え、厳密には違う。
これに比べるとMythicはメモリー(NANDフラッシュ)をそのままアナログ計算機として利用するというアイディアで、こちらは真の意味でのIn-Memory Computingになっているのは間違いないが、NANDフラッシュを使うというあたりで製造プロセスに縛りが出てくることになる。
2018年に創業したばかりのTetraMem
すでに44の特許を出願し18が成立
ということで今回のTetraMemになる。こちらは2018年にフレモントで創業されたばかりの企業である。創業者はNing Ge博士で、STマイクロエレクトロニクスでマスターテクノロジストを12年務めたあと、2018年に同社を創業している。
TetraMemの会社概要。In-Memory Computingにフォーカスを置いているとする
ただ創業直後はまだ会社そのものもステルスモードになっており、オープンになったのはごく最近のことだ。同社は他にも創業者としてScientific Board Chief Advisorという肩書で南カルフォルニア大のJ. Joshua Yang教授と、Chief Process Advisorという肩書でマサチューセッツ大学アマースト校のQiangfei Xia教授が加わっている。
さらに2020年から同社にCTOとして参加するまでの間はニューヨーク州立大ビンガムトン校の助教だったMiao Hu博士も経営陣に加わっており、こうしたアドバイザーが同社の技術的なバックボーンになっているようだ。
ちなみに現時点での従業員はまだ20人に満たないようで、まだベンチャー企業の、しかもまだアーリーステージ扱いである。ただこの短い期間に同社はすでに44の特許を出願、うち18が成立しているなど、技術力そのものはかなり高いと推察される。
さてそのTetraMemの発想である。In-Memory Computingが特にAIなどでは効果的である、という話は冒頭でも触れた通りだ。
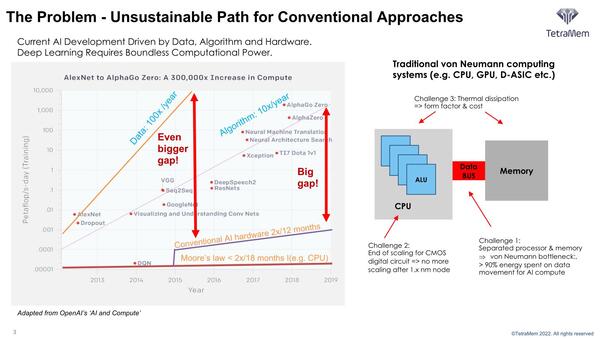
左の図は、扱うべきデータ量は毎年100倍、アルゴリズムの複雑さも毎年10倍の割合で増加しているのに、AIのハードウェアは年間2倍程度でしか強化されない(ムーアの法則では18ヵ月で2倍程度とさらに低い)ことで大きなギャップがあるとしている。
右側の、つまりCPUとメモリーが別々になった従来型の構成では、以下の問題が出てくる。
1. 従来型のアーキテクチャー、つまりノイマン型の構成ではデータの移動に消費電力の90%以上を費やすことになり、これが性能/消費電力比向上の妨げになっている。性能を上げようとしても、供給できる電力に限りがあるから、性能が上げきれないことになる。
2. CMOSの微細化がどんどん厳しくなり、10nm世代以降では微細化のペースが落ちている。ということは、大規模なプロセッサーをどんどん作り難くなる。
3. 1.と2.に絡んで、消費電力増大にともなう発熱がシステムの性能や規模を妨げることになる。
これを解決するための一番効率的な方法がIn-Memory Computingだというわけだ。もちろんこれはAIのような並列性の高いデータドリブンな処理だからこそ通用する話で、例えばWordの高速化にはまるで向かないわけだが。
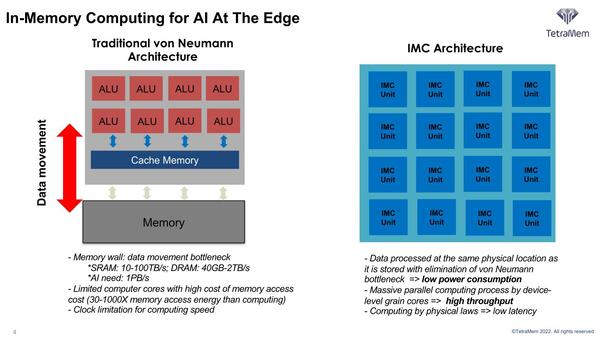
In-Memory Computingの特徴。演算器とメモリーが混在すればデータ移動の消費電力がまるっと減らせるし、配線も大幅に簡潔化できるから演算器の密度を上げやすく、高い性能を実現できる
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ


















ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")
















