
3次キャッシュを積層しても
それほど原価率は上がらない
もう1つおもしろいのが価格である。試しに今回の4製品と、おそらくは競合と位置付けられるであろうIce Lakeベースの第3世代Xeon Scalableのスペックを並べてみたのが下表である。Xeon Scalableはコア/スレッド数を合わせ、その中で一番動作周波数が高いものをピックアップしてみた。なお、64コア製品はXeon Scalableには存在しないので、一番多い40コア製品を入れてある。
| 第3世代Xeon Scalableとのスペック比較 | |||||||
|---|---|---|---|---|---|---|---|
| AMD | |||||||
| スレッド数 | モデルナンバー | 周波数 | TDP(W) | 価格 | |||
| Base | Boost | ||||||
| 128 | EPYC 7773X | 2.20GHz | 3.50GHz | 280W | $8,800 | ||
| 64 | EPYC 7573X | 2.80GHz | 3.60GHz | 280W | $5,590 | ||
| 48 | EPYC 7473X | 2.80GHz | 3.70GHz | 240W | $3,900 | ||
| 32 | EPYC 7373X | 3.05GHz | 3.80GHz | 240W | $4,185 | ||
| インテル | |||||||
| 128 | Xeon Platinum 8380 | 2.30GHz | 3.40GHz | 270W | $8,666 | ||
| 64 | Xeon Platinum 8362 | 2.80GHz | 3.60GHz | 265W | $5,828 | ||
| 48 | Xeon Gold 6342 | 2.80GHz | 3.50GHz | 230W | $2,706 | ||
| 32 | Xeon Gold 6326 | 2.90GHz | 3.50GHz | 185W | $1,392 | ||
こうしてみると、64コアや32コアに関しては、インテル製品の価格に近いところに合わせてある感じがするが、24/16コアに関しては独自の価格設定という感じになっており、あまり価格を合わせている感じがしない。むしろ、3D V-Cacheなしモデルに1000ドル増し、という方が自然に感じられる。
1000ドルを8ダイで割るとダイあたり125ドルという計算になる。もちろんEPYCだから原価率は低く抑えていると思うが、仮に5割だとすると3D V-Cacheのダイの製造コストと3Dスタッキングのコストを足すと62.5ドルという計算になる。
前回も書いたが、3D V-Cacheのダイサイズは41mm2と、もともとのZen 3のダイの半分弱なので、ダイコストは50ドルかそのくらい。後工程で位置合わせをして実装するのに10ドルくらいというのはわりと妥当な推定ではないかと思う。というより、位置合わせと積層のコストをこの程度に抑えないと普及しないだろう。
これはRyzen 7 5800X3Dの449ドルという価格を考えても妥当な推定に思える。Ryzen 7 5800Xも2020年11月の発表時の価格は449ドルだったが、現状の市販価格は例えばNeweggでは348.99ドルといったところ。こちらは原価率はそこまで高くないと思うが、ショップが仮に10%の利益を取ったとしてAMDからの卸価格は315ドルくらいだ。
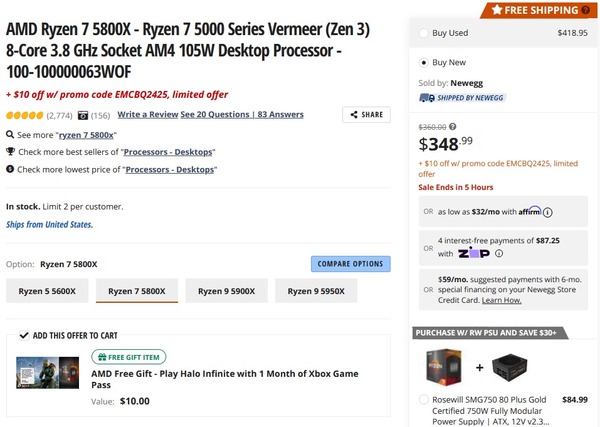
3月26日における価格。さらに10ドルオフのクーポンも使えるらしい
これに1ダイ分の3D V-Cache積層の原価62.5ドルと多少の利益を載せたとして、卸価格は400ドル程度。そこから10%の利益を載せるとちょうど449ドルあたりになる計算で、これまた辻褄が合う計算だ。
例外はEPYC 7373Xで、EPYC 73F3との価格差は600ドルほどしかない。つまりEPYC 7373Xのみ原価率が低い計算になる。ただEPYC 7373Xの場合、8ダイで16コア、つまり各ダイあたり2コアしか使っていないモデルなので、おそらくはコア側に欠陥があるダイ(3次キャッシュは無事)を救済できるわけで、その分原価率は低く抑えられる。したがって3次キャッシュを積層してもそれほど原価率が上がらないと考えられる。
ところで今回のMilan-Xは、必ずしもすべての用途に向いているとは言えない。実際AMDも、Milan-Xはあくまでも“Cache Sensitive Use Case”(キャッシュの効果が大きい用途)向けにのみお勧めとしており、既存のMilanベースのEPYC 7003シリーズも併売されることになっている。

MilanベースのEPYC 7003シリーズも併売される。今年中にGenoaベースの第4世代EPYCが投入されるから、ここで製品ラインナップを刷新して混乱を招きたくないというのもあるだろう
なぜという話は以前マイクロソフトによるベンチマーク結果をご紹介した時にほぼ答えが出ているが、大量のデータをオンメモリーに置いてひたすら計算をかけるような処理では確かに性能が向上しやすいものの、ある領域を超えると結局追加の3次キャッシュも飽和してしまい、その先はメモリーアクセスがボトルネックになって性能が伸びない、という結果が実際にでているためだ。
下の画像のケースが一番わかりやすいと思うが、効果を一番引き出すにはノードあたり8VM程度を維持する必要があり、これを32VMなどにすると効果はあるものの、通常のMilanと大差ないことになってしまうためで、コストパフォーマンスを考えると使いどころが限られるのは致し方ないところだろう。
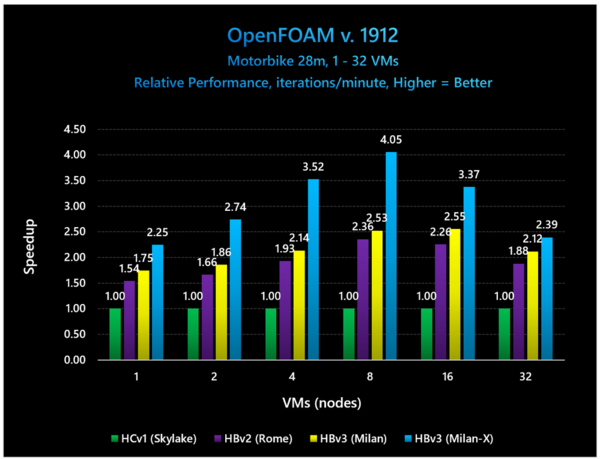
OpenFOAMは流体解析のソフト。これは28M要素のオートバイの解析のケースである
ちなみにAMDからはXeonと比較しての性能の高さをアピールするスライドも示されているが、Ice Lake世代に比べて勝っているのは当然であり、本命の対抗馬はIntel 7で製造されるSapphire Rapidsベースの第4世代Xeon Scalableということになる。
もっともそのSapphire Rapidsがどんどん投入が遅れている(間もなく第1四半期が終わってしまう)から、結局Sapphire Rapidsから時間を置かずにGenoaベースの第4世代EPYCが投入されることになりそうで、そのあたりも勘案するとMilan-XはIce Lake世代との比較が結果として一番適切なのかもしれない。

こちらではコアの数の差がモロに性能に出ている感は強い

32コア対決。ただこちらでも性能差が結構あるということになる。もっとも先のOpenFOAMのベンチマークではないが、これらのアプリケーションで一律これだけの性能差があるわけではないあたりが微妙なところ

ざっくりサーバーの数を半減でき、これにともないTCO(総所有コスト)も半減できるとする
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ











