



ロードマップでわかる!当世プロセッサー事情 第645回
ET-SoC-1の設計思想で納得、やっぱりEsperantoはDitzel氏の会社だった AIプロセッサーの昨今
2021年12月13日 12時00分更新

電圧を下げて効率を上げるのは
Esperantoの創業者Ditzel氏の得意技
消費電力20W以下をどう実現するかであるが、Espelantoは7nmプロセスを使いつつ、動作電圧をサブスレッショルド領域まで落とし込むことでこれを実現した。
筆者はこのスライドを見た瞬間に、「ああこれは間違いなくDitzel氏の設計だ」と強く感じた
一般論であるが、トランジスタの駆動電圧を上げると高速動作が可能になるが、その一方で消費電力は電圧の2乗に比例して増えるので、可能なら電圧は低い方が効果的である。
ただ通常のトランジスタの動作に関して言えば下限が決まっている。この下限をスレッショルド電圧と呼ぶのだが、この電圧を下回る領域で動かすことで、おそろしく効率を上げられることになる。ただしこの領域は通常ファウンダリーが動作を保証していない領域でもある。
実際温度特性や電圧のわずかな変動にとても敏感に反応するため、安定動作は難しいとされる。というか、実際難しい。あと性能/消費電力比は大幅に向上するが、性能の絶対値そのものは落ちるという欠点もある。
7nmプロセスの場合、通常0.6~0.7V程度の電圧でトランジスタは駆動されるが、EsperantoはET-SoC-1を0.4V未満で駆動することで、大幅に性能を改善したとする。
なぜこれが創業者のDitzel氏の設計っぽいか? というと、Transmetaの時もEfficeonの第2世代にBody Biasを使っての低電力動作をすることで大幅に性能/消費電力比を改善するという離れ業を実現したからだ(LongRun2)。
それのみならず、そのLongRun2をSONYやNEC Electronicsにライセンス提供までしている。Body Biasの仕組みは連載255回で説明したが、効果的な一方でコスト増加につながる面もあり、結局ほとんど普及しなかった。
これに変わる技術として注目されつつ、その技術的難易度の高さもあって一部のメーカーしかチャレンジしてこなかったサブスレッショルド領域での動作にためらいなく踏み込むあたりが、いかにもDitzel氏という感じに筆者には感じられる。
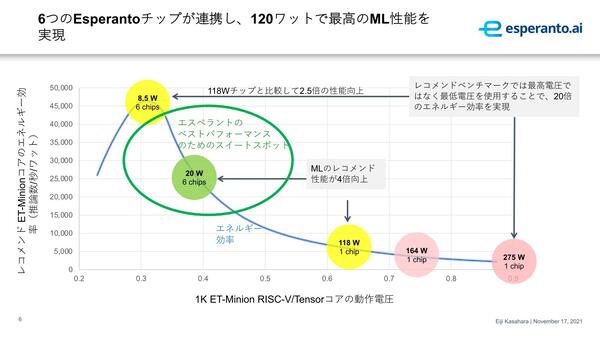
ちなみにET-SoC-1の場合、一番効率が良いのは0.3V前後らしいが、絶対性能はその分落ちるわけで、必要になるチップの数がおそらく6つでは効かなくなる。最終的に0.38Vあたりがベストバランス、というのがEspelantoの結論である。
おそらくET-Maxionが500MHz駆動(ET-Minionは後述するが300MHz程度と想像される)というのは、この0.4Vをやや下回るあたりでの動作周波数で、0.75V付近まで引き上げれば1.5GHz駆動、0.9Vで2GHz駆動というあたりかと思われる。ただ絶対的な消費電力で言えば、0.38V→0.9Vで5.6倍ほど増える形になるので、動作周波数の上がり方より消費電力の上がり方の方が激しい。
ET-SoC-1の特徴はこれだけではない。ET-SoC-1を構成する2種類のプロセッサーのうち、ET-Maxionの方は連載594回で内部構造を紹介したが、ある意味「普通の」RV64GCプロセッサーである。
後述する、ET-Minionに搭載された独自のベクトル演算命令などは搭載されていない、AI処理の中で比較的上位の処理(とWeightデータの取り扱いや入出力データのハンドリング)などを担うだけなので、ここであれこれ工夫をする必要もないというあたりだろう。
もしここは今であれば、それこそSiFiveなりAndesなりからアプリケーションプロセッサー向けのIPコアを買って使っても良いのだろうが、Esperantoが開発を始めた当初はこうしたIPコアが存在しておらず、自分たちで作るしかなかったから作った、という方が独自コアの理由としては大きな比重を占めるだろう。
さて、これに対してET-Minionの方はAI処理の要の部分である。連載594回ではET-Minionの詳細が明らかにされていなかったが、今回はこちらがかなり明確になった。ET-Minionの基本的な構成が下の画像だ。
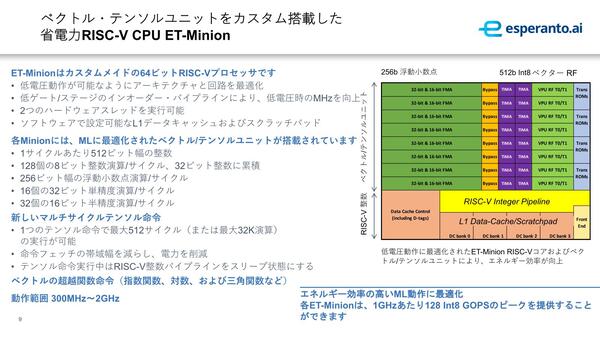
テンソル命令処理中はRISC-Vの演算パイプラインが休止するというのもすさまじい。ちなみに32K演算というのは、512bit Vector RFでは8bitなら64演算命令分で、これを512回自動で繰り返すので32K演算ということになる
基本的にはイン・オーダーの簡単なパイプライン構成を持つ小さ目のコアであるが、命令アクセス時のレイテンシー遮蔽用に2スレッドを実行可能になっているほか、猛烈に強力なVector/Tensor Unitが搭載されている。
なにがすごいかというと、1命令で最大512サイクル実行を続けられベクトル命令があることだ。限りなくDSP的というか、Vector/Tensor Unitはほぼアクセラレーターで、RISC-Vエンジンはそのアクセラレーターの制御用という扱いになっている。
また命令キャッシュそのものは32KBあるが、8つのET-Minionがその命令キャッシュを共有するという仕組みもなかなか見ない。
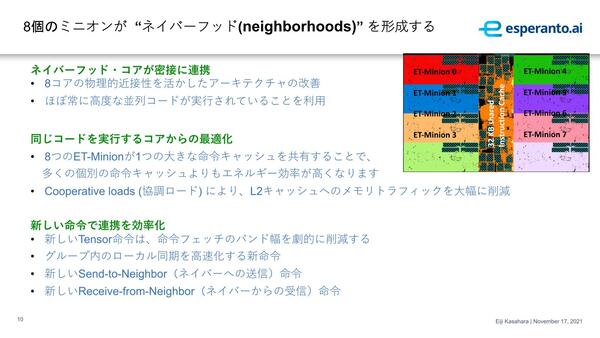
個々のコアは32KBの命令キャッシュと同程度のエリアサイズというあたり、いかにET-Minionがコンパクトかわかる
例えば畳み込みニューラルネットワークなどの場合、演算の大半はひたすら畳み込みを行なうことになるが、1命令で畳み込みを表現可能なら命令キャッシュは最小でいいし、なんなら複数のコアで畳み込みをひたすら行なっているのであれば、キャッシュを共有しても不都合は少ない。
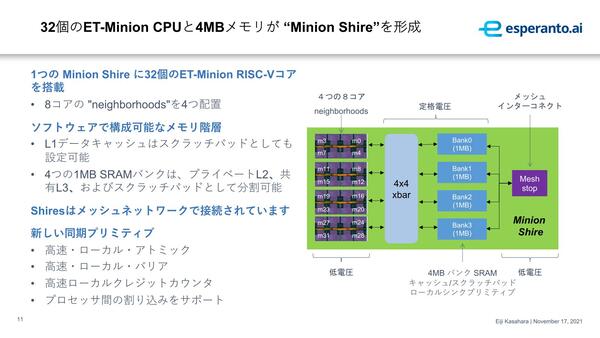
個々のSRAMをキャッシュとして使うか、ScratchPadとして使うかはアプリケーション要件に併せて変更できる模様。それはそれとして、Shireという用語はあまりCPUの内部で使うケースは見かけないのだが、なんでこんな言い方にしたのだろう?
おそらく実際のコードでは、畳み込みの処理をひたすらぐるぐる実行するスレッドを同時に複数発行、これをNeighborhoodsに所属するET-Minionで分散して処理する形になるのだろう。このNeighborhoods×4と4MB SRAM、それとメッシュ・ネットワーク用のMesh Stopで1つのShineを構成するが、このShine同士は2次元メッシュを構成して接続されることになる。
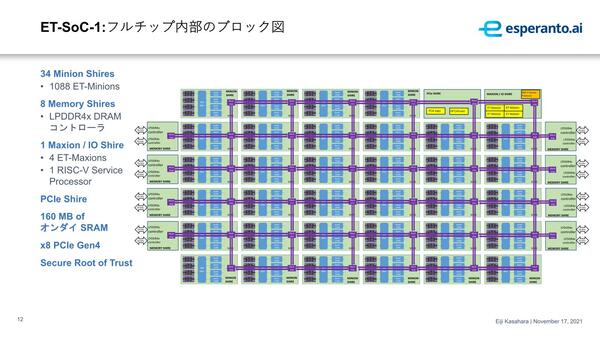
Shineあたり4MBなら4×34=136MBで、160MBにはあと24MBほど足りない計算になるのだが、Memory ShineなりET-Maxion/IO Shineあたりに搭載されているのだろうか?
ところで、512サイクルもの間自動で実行されるテンソル命令というのはRISC-Vの標準命令ではない。そもそもテンソル命令そのものがないし、ベクトル命令にしてもRelease 1.0が標準化完了したのは今年9月のことである。
当然そんなのを待ってるわけにはいかないので、このベクトル/テンソル命令はEsperantoの独自実装である。したがって互換性がないと言えばその通りなのだが、そもそもほとんどのAIプロセッサーは独自命令セットを提供しているので、開発環境さえ提供されれば別にRISC-Vとの互換性がなくても大きな問題にはならないし、それ以外の命令セットはRISC-V互換なので、これはRISC-Vの仕様にも適うことになる。

たしかに見たことのない命令がてんこ盛り。RISC-Vのベクトル演算はもう少し汎用向けになっている
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ














で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")










































