ロードマップでわかる!当世プロセッサー事情 第644回
業界初のマルチダイGPUとなるRadeon Instinct MI200の見事な構成 AMD GPUロードマップ
2021年12月06日 12時00分更新

FrontierはInfinity Fabric経由でEPYCと接続
HPCはPCIe経由でEPYCと接続
最後にノード構成について。まずFrontier向けだが、連載635回で説明したようにFrontierではノードが1つのEPYCと4つのRadeon Instinct MI200から構成される。
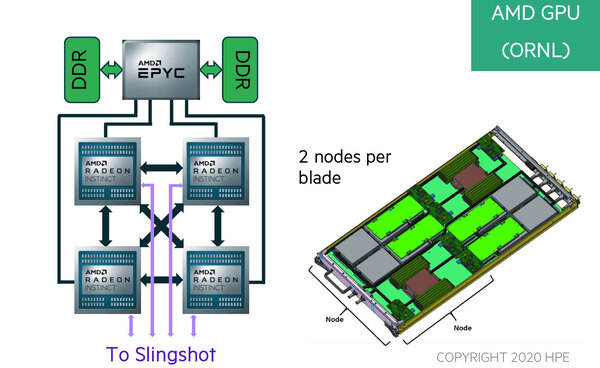
Frontierのノードは1×EPYC+4×Radeon Instinct構成になる
ということは1つのノードには8つのRadeon Instinct MI200のダイが存在するわけで、この8つがすべて相互接続するのかも? ということで描いたのが下の図であるが、実際はもう少しシンプルであった。
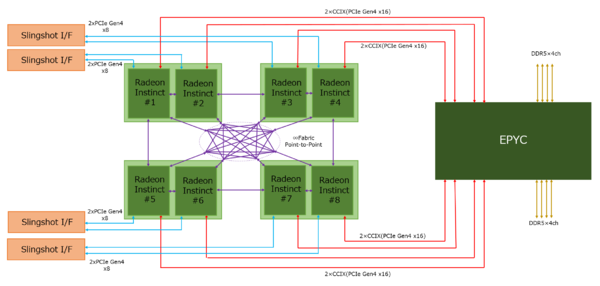
連載635回に掲載したRadeon Instinctを搭載したノード構成推定図
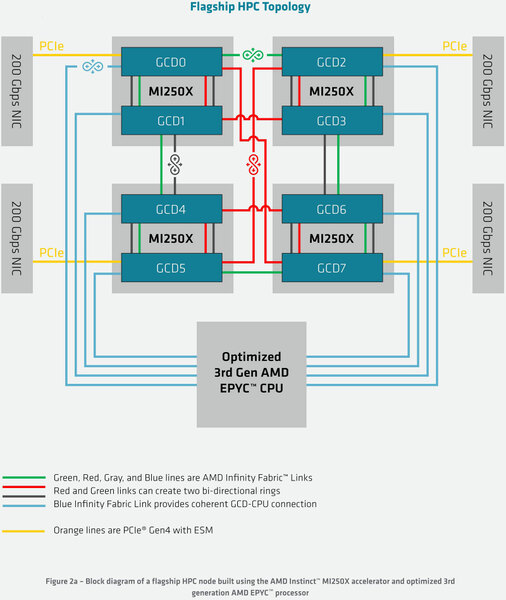
もっともこれ、図を簡単化しているだけで、内部的には完全Point-to-Point接続なのかもしれない。200Gbps NICというのはCray(というよりHPE)のSlingshot I/Fのことだ
決定的に違うのは、EPYCとの接続がCCIXではなくInfinity Fabricでの接続になっていることだ。正直これは意外だった。ということは、PCIe/CCIXではなく、Infinity Fabric経由でEPYCからRadeon InstinctをアクセスするためのAPIが、RoCmで提供されるかと思われる。
ただ、AMDとしては別にFrontier「だけ」にRadeon Instinct MI200を提供するつもりではなく、広くさまざまな用途向けに提供することを考えている。下の画像がメインストリームのHPC/機械学習向けの構成で、4つのMI200同士は相互にInfinity Fabricで接続されるが、それとCPUの接続はPCIe経由となるというものだ。
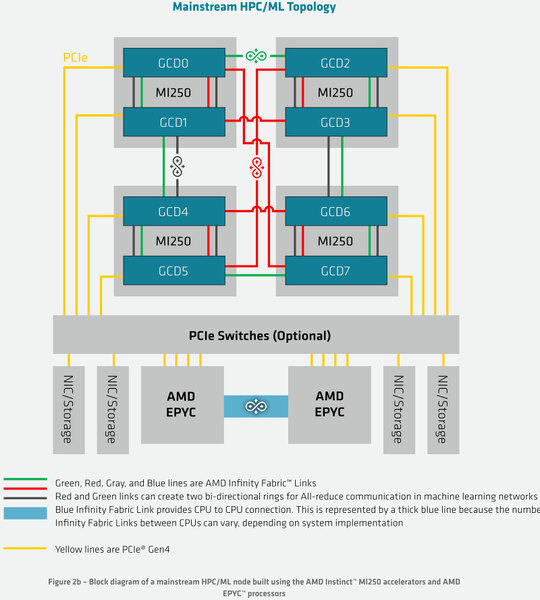
Photo10の構成はHPEのSlingshotが前提になるので、他のインターコネクトを使いたい場合にはこちらの構成が現実的だろう
システム全体へのインターコネクトもCPU側に置かれる構造になる。またRadeon Instinctで機械学習向けのハイエンドシステムを構築した例が下の画像だ。8枚のMI200でノードを構成するイメージとなる。
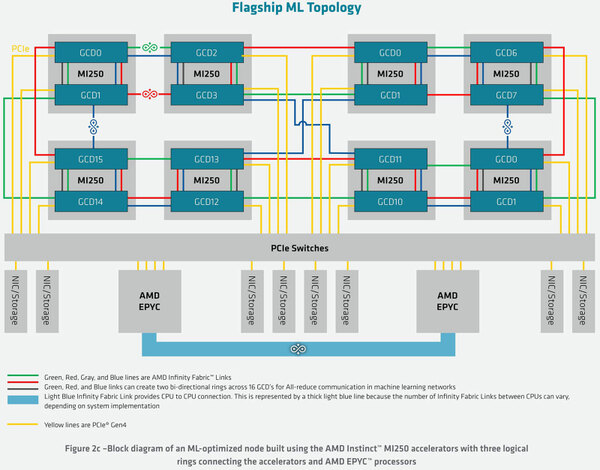
Radeon Instinctで機械学習向けのハイエンドシステムを構築した例。PCIeレーンがこれだけ多数あると、このPCIeスイッチの価格はいくらなのかが気になる
MI200の性能はNVIDIA A100の約2倍前後
ラインナップはMI250X、MI250、MI210の3製品
ここからは性能と製品構成について説明しよう。性能に関しては非常に限られているが、NVIDIA A100との比較が下の画像だ。2020年に出たNVIDIA A100に負けていたらお話にならないわけで、後追いである以上当然性能は向上している。
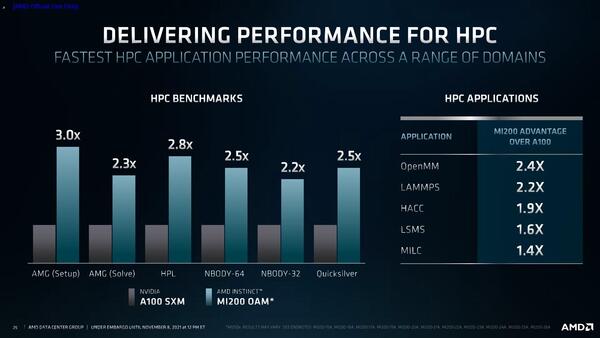
左が代表的なベンチマーク、右がいくつかのアプリケーション例である
次にラインナップであるが、まずOAMタイプでRadeon Instinct MI250XとMI250が投入され、PCIeカードタイプのRadeon Instinct MI210は後追いとなる。

MI210に関しては現在スペックを含めて詳細は未公開。消費電力を300W以下に抑えるためにはそれなりに性能を落とさないと厳しいだろう
そのOAMタイプ2製品であるが、以下のようになっている。
| Matrix Unitの構成 | ||||||
|---|---|---|---|---|---|---|
| MI250X | MI250 | |||||
| XCU数 | 220 | 208 | ||||
| 動作周波数(Boost) | 1700MHz | 1700MHz | ||||
| FP32/64 Vector(Peak) | 47.9TFlops | 45.3TFlops | ||||
| FP32/64 Matrix(Peak) | 95.7TFlops | 90.5TFlops | ||||
| FP16/BF16(Peak) | 383.0TFlops | 362.1TFlops | ||||
| INT4/INT8(Peak) | 383.0TOPS | 362.1TOPS | ||||
| HBM2e | 128GB | 128GB | ||||
| TDP | 560W | 500W | ||||
実はOAMの場合、12V供給で許容されるのは最大350Wまでであり、48/54V供給では700Wまで可能という仕様になっている。おそらくはMI250X/MI250ともにOAMは48V供給の形になっていると想像される。
また先にMI250Xは1700MHz駆動と説明したが、ではMI250は? というと、計算では1701.4MHzになるので、動作周波数は変わらずにCU数だけ208に減らした構成になるようだ。TDPの数字はAMDのホワイトペーパーからの抜粋だが、CUを12個減らすだけで60Wも減るのか? というと少し疑問ではある。この数字はピーク値らしいので、実際はもう少し差が少ないのかもしれない。
ちなみにFrontierの場合、何度も繰り返すがMI250Xが4枚+Milan-Xで1ノードである。ということはMI250X×4+EPYCで2520W。マザーボードやメモリー、ネットワークカードまで入れるとノードあたり3KW弱といったところ。これが9000ノードだと27MWほどになる。Frontierの性能を示す数字にあるPower Consumption 30MWattを実現するのはけっこう難しいように思うのだが、さて実際はどんな具合になるのだろうか? 来年6月のTOP500ではそのあたりの数字も出てくるはずであり、結果が楽しみである。
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ













