ロードマップでわかる!当世プロセッサー事情 第644回
業界初のマルチダイGPUとなるRadeon Instinct MI200の見事な構成 AMD GPUロードマップ
2021年12月06日 12時00分更新

連載635回でFrontierに納入される予定のRadeon Instinctの構成をいろいろ説明したが、“AMD Accelerated Data Center Premiere”では当然こちらの説明もあったので、答え合わせも兼ねてご紹介したい。
ちなみに発表記事で簡単にRadeon Instinct MI200シリーズの概要が紹介されているが、細かい製品仕様の話は最後にする。

1つのパッケージに2つのダイを搭載した見事な構成の
Radeon Instinct MI200シリーズ
連載635回のノード構成推定図で「1つのRadeon Instinctと描いたものが、2つのRadeon Instinctを搭載したモジュールだと仮定すると、このギャップはもう少し縮まる」と書いたが、実際に発表されたRadeon Instinct MI200シリーズは見事に、1つのパッケージに2つのダイを搭載した構成となった。

フォームファクターはOAM(OCP Accelerator Module)準拠。OCP(Open Compute Project)はFacebook(現Meta)が主導する、標準的なサーバー向け仕様を策定するプログラムで、多くのメーカーがこれに参画しており、NVIDIAのA100もこのOAM仕様のものがメインである
そのRadeon Instinct MI200シリーズの構成が下の画像だ。HBMはダイあたり4スタック、XCUはダイあたり110なので、実はRadeon Instinct MI100と比較すると、微妙にXCUの数が減っている計算になる。

HBM2eの寸法(9.975×10.975mm)から推定されるダイサイズは25.1×29.3mmで735.4mm2ほど。Radeon Instinct MI100の推定ダイサイズ(763.2mm2)とほぼ変わらない
それにもかかわらず、FP64のベクトル演算性能が4倍ほどに引き上げられている。ダイ1つあたりの性能で言っても軽く倍である。
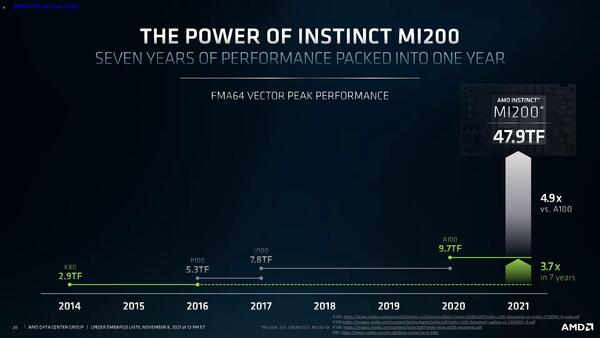
こちらはNVIDIAの製品との性能比較になっているが、Radeon Instinct MI100の性能はFP64で11.5TFlops、FP32で23.1TFlopsとされている
もう少し細かい数字が下の画像であるが、FP64のベクトル演算で47.9TFlops、FP64のマトリックス演算で95.7TFlopsというすさまじい数字を叩き出している。
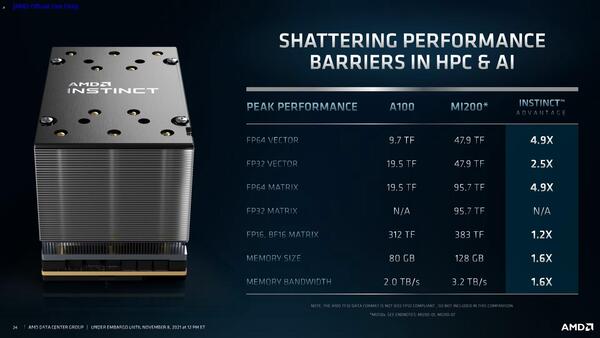
NVIDIA A100にはない、FP32のマトリックス演算もサポートされる
rennsai635回でFrontierのノード(EPYC×1+Radeon Instinct×4)の性能を49TFlops程度と推定したが、実際にはMilan-Xを無視してRadeon Instinct×4だけでも191.6TFlopsに達しており、スペック表の数字が正しければ9000ノードにおけるピークで1.72EFlopsに達する。1.5EFlops以上、というFrontierの目標数値はわりと堅く実現できる格好だ。
ではなぜこれが可能になったのか? という話であるが、MI100とMI200のダイの基本構成を比較するとわかる。
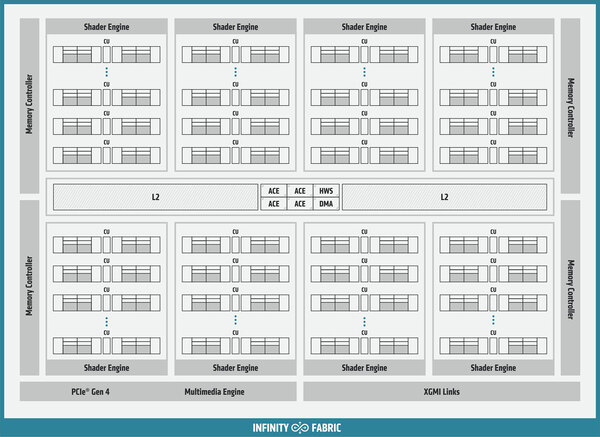
MI100の基本構成。XCUを16個まとめたShader Engineという単位があり、このShader Engineの単位でタスクが管理される
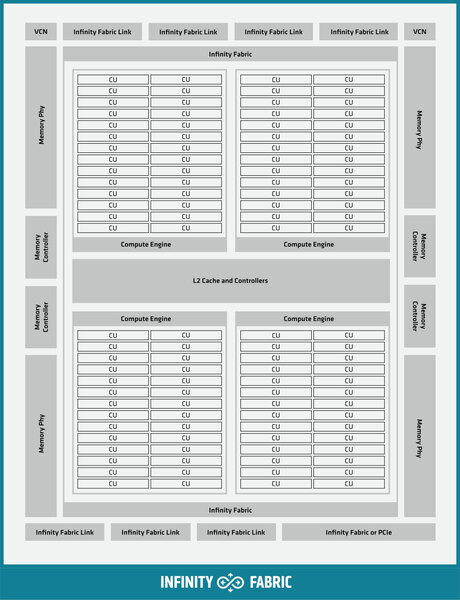
MI200の基本構成。Shader Engineが配され、28CUが直接1つのCompute Engineとして扱われる格好に
まずCU(CNDAからはXCUという呼び方に変わったが)の数そのもので言えば、MI100が16×8=128XCUで、うち8つを無効化して120XCU構成としている。一方MI200は14×8=112XCUで、うち2つを無効化して110XCUとしている格好だ。
細かいところでは、ACEがなくなったというか、これまではACEが任意のShader Computeに対してスレッドを割り振って処理する格好だったのが、どうもMI200ではACEが直接CUに対してスレッドを割り振るような格好で処理をすることになったようだ。このあたりの得失など、そのうちなにかしら話が出てくることを期待したい。
またHWS(HardWare Scheduler)のブロックもなくなっているが、これはCompute Engineにその機能が搭載されたのか、それとも全部ソフトウェアでスケジュールするようにしたのかも現時点でははっきりしない。
MI200の基本構成を見ると、一番上の左右にVCN(Video Codec Next)が搭載されているが、これはMI100にはなかった機能だ。このVCNではH.264/AVC、HEVC、VP9、JPEGのデコードと、H.264/AVC、HEVCのエンコードが可能とされている。
2次キャッシュのサイズそのものはMI100/MI200ともに8MBであり、16wayセットアソシエイティブ方式なのも同じであるが、MI100が64Bytes/サイクルなのに対し、MI200は128Bytes/サイクルと帯域が倍増されている。
メモリーI/Fが4組なのは同じだが、MI100はHBM2なので2.4GT/s、一方MI200はHBM2eで3.2TB/sとなっている。さらに、MI100にはXGMI Linksというポートが右下にあるが、これはInfinity Fabricのリンクのことだ。XGMIは“Socket/Inter-Chip Global Memory Interconnect”で、パッケージ同士の接続に利用されるものだが、MI100では最大4枚までのカードをRing Busの構成で接続できた。
一方MI200では後述するように、複数のダイ/パッケージ同士をPoint-to-Pointの形でInfinity Fabricで接続するため、MI200では外部向けに7ポートのInfinity Fabricと、1本のInfinity Fabric/PCIeポートが用意される格好になっている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ












