




AVX-512 Unitを搭載しないことが判明
性能重視のP-Core
さて前回は軽く流したが、P-Coreの拡充ぶりはすごい。P-Coreの全体構造は前回示したが、それ以前のWillow Cove(Tiger Lakeに使われているコア:Rocket LakeのCypress Coveの次世代にあたる)と比較したのが下の画像である。フロントエンド、つまりスケジューラーまではまだしも、Issue Portの数が大幅に増えているのがわかる。

Cypress Coveのブロック図は昨年のArchitecture Dayの資料から引っ張ってきた。バックエンドのユニット数が大幅に増えた関係で、Golden Cove側が妙に狭いことに。Golden CoveにROBが含まれていないのは、単に省いただけだろう(同様にReservation Stationも省かれている。多分入りきらなかったのだろう)。
まずフロントエンドだが、Sunny Cove&Willow Cove/Golden Coveでは以下のようにデコード性能が大幅に強化されている。
| デコード性能 | ||||||
|---|---|---|---|---|---|---|
| 開発コード名 | デコード | μOpキャッシュ | マイクロコード | |||
| Sunny&Willow Cove | 5命令/サイクル | 6μOp/サイクル | 4命令/サイクル | |||
| Golden Cove | 6命令/サイクル | 8μOp/サイクル | 4命令/サイクル | |||
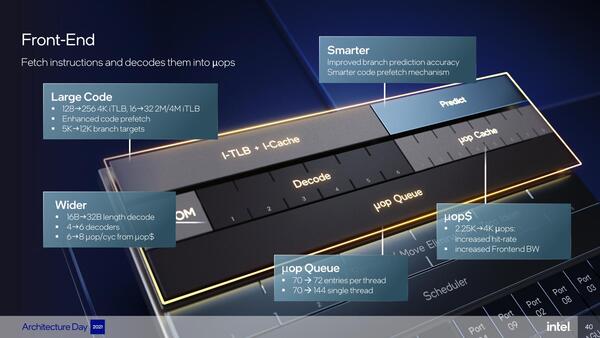
フロントエンド。正確に書けばSunny Cove&Willow CoveのデコードはSimple×4+Complex×1で、これがどうもGolden CoveはUnified×6になったように見える
さらにμOpキャッシュ容量やキューなど、すべてが強化されている。μOpキャッシュからはついに8μOp/サイクルでの供給になっており、キャッシュ容量の増加と相まって実効デコード性能を大幅に引き上げているように見える。
一方、バックエンドの方であるが、まずIssue Portが10→12に強化された。またアロケーションも同時6命令に強化されている。

バックエンドは、Port 10/11が新たに追加された。またROBも512エントリーに増強されている(Sunny Cove/Willow Coveは352)
そして増強であるが、まず5番目のALUが追加されたことで、通常のアプリケーションであってもついにx86命令換算で5命令/サイクルの実行が可能になった。

LEA(Load Effective Address)はアドレス計算に使う命令だが、フラグに影響を与えないこともあって、アドレス計算などではADDなどよりも広く使われている。また加算にADDの代わりに使われることもあり、1サイクルで処理できるとあってこれも広く使われている。
またFPU系で言えば、新たにFast Adder(FADD)が2つ追加されている。そしてALUが5つということは、メモリーアクセスをともなうALU命令が5命令/サイクルで実行される可能性があるわけで、これに対応してAGU(Address Generation Unit)も5つに強化された。

新たにFast Adderが2つ追加。AVX512に関しては、Alder Lakeでは無効化(削除?)されている

AGUも5つに強化。そしてLoad Unitも2→3に増強されている
2次キャッシュはWillow Coveの1.25MBを継承したが、これもサーバー(つまりSapphire Rapids)向けでは2MBに増強されることになっている。

この時点で、サーバー(Sapphire Rapids)向けとクライアント(Alder Lake)向けではコアそのものが物理的に異なっているのが明白である
ところで、クライアント向け(つまりAlder Lake)のP-CoreではAVX-512とAMXが利用できない。これはP-CoreとE-Coreで利用できる命令セットが完全に一致していないとスレッドの切り替えができないためだ。
このうちAMXはアクセラレーターなので搭載されていないのは間違いないとしてAVX-512は? という話だが、これは「無効化されている」のか「搭載されていない」のかに関しては、どうも搭載されていない公算が高そうだ。
HotChipsの質疑応答で、AVX-512 Unitは搭載されていないのか、それとも無効化されているのか? という質問に対し、説明したインテルのEfraim Rotem氏は「両方だ。Golden Coveのいくつかの機能はクライアント向けでは無効化され、いくつかは物理的に削除されている」と回答し、間接的にであるがAVX-512は搭載されていないことを示唆している。
そもそもSapphire RapidsとAlder Lakeは2次キャッシュのサイズが違うから、コアそのものが異なっている。またAVX-512ユニットは物理的にそれなりのサイズを占有するので、コストが厳しいクライアント向けに搭載する理由はない(し、外すのも簡単である)。無効化されている機能は、RAS関係などパイプライン内部にがっちり組み込まれており、外すのが困難な機能だろうと想像される。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























