




直接2つのダイを接続する
Foveros Direct
このFoveros Omniを一歩進めたのがFoveros Directである。要するにインターポーザーも挟まずに、直接2つのダイを接続する方法だ。Microbumpすらないため、配線密度は非常に高くとれる。
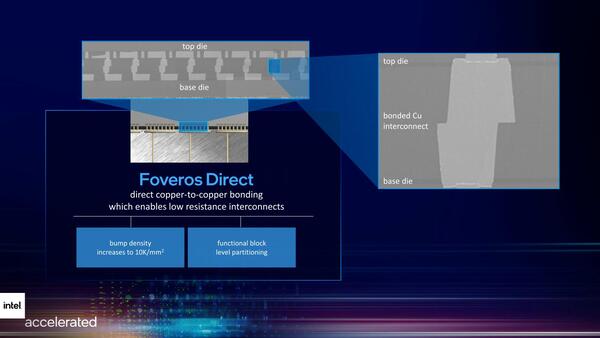
Foveros Direct。もうインターポーザーすらない
ただしインターポーザーが入らないということは、仮に上と下のダイのサイズが完全に一緒だと、一切外部に信号が出せないことになる。したがって、製品として構築するためにはBase dieの方が小さくないといけない。つまり下図のような構成である。
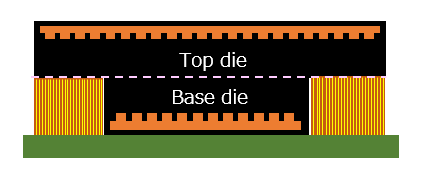
Foveros Directの模式図
このFoveros Directであるが、実はTSMCのSoICの中でチップの表面同士をつなげる方法(論文ではSoIC F2Fと表記されていた。Face-to-Face SoICの意味である)とまったく同じである。ということは、例えば大容量キャッシュを3D積層するといった用途には非常に向いていることになる。
この場合Top dieにプロセッサーが入り、Base dieにキャッシュを追い出す形になるが、それであればBase dieの方がダイサイズが小さいのは普通だし、キャッシュなら発熱が少ないから放熱にも問題が出にくい。
まだインテルはFoveros Directの用途を明確にしていないが、大容量LLCの実装オプションとして使うことはできそうだ。少なくとも、AMDの3D-VCacheに近い(≠同じ)構成を作ることはできるだろう。同じでない、というのはこちら(https://ascii.jp/elem/000/004/057/4057940/3/)で紹介したようにV-Cacheは1~4スタックまで作り分けられるが、Foveros Directでは1スタックしか実現できないからだ。
ちなみにIntel Foundry Serviceの最初の顧客の1つとして、Amazonがこのパッケージング技術を利用すると明らかにした。おそらくチップそのものはAmazonの子会社であるAnnapurna Labsが開発するArm Neoverseベースの製品で、前工程はインテル以外の可能性があるが、それをインテルの後工程ファブに持ち込んでパッケージングすることを想定していると思われる。

Foveros Omni/Directとは思えないので、Foveros+EMIBあたりだろうか?
ついでに言えば前回紹介したIntel 20Aの最初の顧客としてQualcommが名乗りを上げているが、同社はもともと複数のファブを使う(TSMCとSamsungの両方を現在も使っている)ことを考えると、これは不思議ではない。別にIntel 20A「だけ」を使う、とは言っておらず、おそらくTSMCやSamsungの2nm世代もやはり同時に利用するだろうし、Qualcommはそうした開発コストを支払えるだけの体力がある。
Auroraの納期遅れに対する罰金は3億ドル
最後に前回の補足を。Auroraの納入が間に合わないことに触れたが、これに関しておもしろい言及がその2日前のEarnings Conferenceの中であった(こちらはhttps://edge.media-server.com/mmc/p/zamhm4tgから視聴できる)。
まずインテルCFOのGeorge Davis氏が説明の最後で「DCGについては、E&Gおよびクラウドの回復にともない、下半期の収益は上半期を大幅に上回り、通期の収益は前年同期比で若干減少する程度と予想している。その結果、DCGは第3四半期、第4四半期共に前年同期比で増加に転じると予想している。ただし下半期の売上総利益率は、主に7nmファブの立ち上げ、顧客への供給状況の悪化、および第4四半期に連邦政府向けビジネスに関連する一時的な費用により、低下すると予想される。第4四半期の売上総利益率は第3四半期とほぼ同水準になると思われる」と言及した。
この「連邦政府向けビジネスに関連する一時的な費用」とは何だ? と当然アナリストから突っ込みが入っており、「詳細は省くがこれはHPC向けに関するものだ」という説明があった。ちなみにこの費用は3億ドルほどとされる。
Auroraの契約は総額5億ドルほどとされており、Auroraを予定通りに納入できなかったペナルティが3億ドルの罰金と考えれば良いかと思う。この返事に続き、ゲルシンガーCEOが「第4四半期に一時的な費用が発生するが、この事業は当社にとって長期的に素晴らしい事業であり、技術的にも市場的にもビジネス的にも多くの利益をもたらしてくれるものと考えている」と、あまりフォローになっていないフォローをしているあたりからもお察しである。Auroraの遅延はゲルシンガーCEOの責任ではないが、インテルにとってはまた大きな自責点をHPC市場で喰らった形だと言えよう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























