松本典子の「Azure Logic Apps」超入門 ~AI編~ 第9回
AI顔検出や画像処理ができるCloudmersiveコネクタを使い、ノンコーディングで実現してみた
人物写真の顔をAIが検出し、ぼかしてツイートするLogic Appsを作ろう
2020年07月27日 08時00分更新

3-1.「A:写真から顔を検出しぼかし処理をする」ワークフローの作成
まずは上図の左側、顔検出とぼかし処理のワークフローから作っていきます。今回の処理のポイントは、次の図のとおりです。

ワークフローAの処理内容
「顔を検出してぼかす」と言うと簡単そうにも聞こえますが、実際にはいったん顔部分だけを切り抜き、その画像にぼかし処理をかけたうえで、元画像と合成する必要があります。最後の画像合成で顔がずれてしまわないように、大きな透明画像を用意して位置合わせを行います。
このワークフローをLogic Appsで作成すると、次の図のような形になります。使うコネクタ数は少なくシンプルなのですが、「式」を多用します。

写真から顔を検出、ぼかし処理をするワークフロー
3-1-1. Azure Logic Appsのトリガーの作成
それではLogic Appsデザイナーの画面でワークフローを作成していきましょう。
まず、今回のトリガーには「HTTP要求の受信時」を選択します。そのうえで「要求本文のJSONスキーマ」(下画面の赤枠内)には、下に記したJSONスキーマをコピー&ペーストしてください。これはデータの入力形式を指定するものです。

トリガーには「HTTP要求の受信時」を選択し、以下のJSONスキーマをコピー&ペーストする
{
"properties": {
"events": {
"items": {
"message": {
"properties": {
"address": {
"type": "string"
},
"fileName": {
"type": "string"
},
"fileSize": {
"type": "number"
},
"id": {
"type": "string"
},
"latitude": {
"type": "number"
},
"longitude": {
"type": "number"
},
"packageId": {
"type": "string"
},
"stickerId": {
"type": "string"
},
"text": {
"type": "string"
},
"title": {
"type": "string"
},
"type": {
"type": "string"
}
},
"type": "object"
},
"postback": {
"properties": {
"data": {
"type": "string"
}
},
"type": "object"
},
"properties": {
"replyToken": {
"type": "string"
},
"source": {
"properties": {
"groupId": {
"type": "string"
},
"type": {
"type": "string"
},
"userId": {
"type": "string"
}
},
"type": "object"
},
"timestamp": {
"type": "number"
},
"type": {
"type": "string"
}
},
"type": "object"
},
"type": "array"
}
},
"type": "object"
}
JSONスキーマをコピー&ペーストしたうえで「保存」をクリックすると、「HTTP POSTのURL」欄にURLが表示されます。このURLは、次のLINE側の設定で使います。
3-1-1-1. LINE側のWebhook送信の設定をする

LINEでのMessaging APIの設定
「LINE Official Account Manager」画面に戻り、左メニューの「Messaging API」をクリックします。赤枠内の「Webhook URL」に、先ほどLogic Appsのトリガーを設定して表示された、「HTTP要求の受信時」の「HTTP POSTのURL」を入力します。
3-1-2. 透明画像を利用する準備/変数の初期化

透明画像を利用する準備
続いて画像合成に必要となる「透明画像」ファイルを用意します。今回はPhotoshopで1200×1200ピクセルの透明画像を作成し、PNGファイルとしてDropboxのフォルダに保存しました。
なお、処理対象となる元画像がこの透明画像よりも大きなサイズだと、最終的に出力される画像でぼかし処理した顔の位置がずれてしまいます。透明画像のサイズは、使用する元画像のサイズよりも大きくしてください。
次に、「新しいステップ」をクリックして、アクションを追加します。検索窓に「Dropbox」と入力し、Dropboxコネクタのアクション一覧から「ファイルコンテンツの取得」を選択します。取得する「ファイル」はもちろん、先ほど保存した透明画像です。
次のステップとして、透明画像の「高さ(タテ)」と「幅(ヨコ)」を指定する変数2つを初期化します。それぞれ「変数を初期化する」アクションを追加し、透明画像の高さ/幅のサイズ(ピクセル数、今回はそれぞれ「1200」)を初期値として入力しておきます。
今回は、高さの変数名を「cihight」、幅の変数名を「ciwidth」としました。この2つの変数は、のちほど利用するコネクタの「式」で使います。
3-1-3. For eachコネクタの設定とHTTPコネクタの設定
次に追加するステップは、繰り返し処理を実行する「For each」コネクタです。検索で「制御」と検索し、表示されるFor eachコネクタを選択します。

For eachコネクタの設定
設定項目の「以前の手順から出力を選択」欄には、動的なコンテンツから「events」を入力します。これにより、LINEに複数のメッセージ(写真)が投稿された場合に、それぞれを順に処理していきます。
次に追加するのは「HTTP」コネクタです。ここではLINEからメッセージ(投稿された写真)を取得します。HTTPコネクタの設定方法は以前の記事:3.2-3. HTTPコネクタの設定を参照してください。
3-1-4. 画像から顔を検出(Cloudmersiveコネクタの利用)
次はCloudmersiveを使い、LINE BOTから取得した画像から顔の検出を行います。

Cloudmersiveコネクタの認証画面(APIキーの入力)
初めてCloudmersiveを利用する際には、上のような認証画面が表示されるので、わかりやすい「接続名」と、先ほどCloudmersiveのサイトで取得した「APIキー」を入力します。「作成」ボタンを押すと、コネクタが接続できるかどうかをテストしたうえで、Detect and faces in an imageのアクション設定に切り替わります。
続いてステップを追加します。「Cloudmersive」で検索して「Cloudmersive Image Processing」(黄色いアイコン)コネクタを選択し、表示されるアクションの一覧から「Detect and faces in an image」をクリックします。
アクションの設定項目である「Image file to perform the operation on」(顔検出処理の対象とする画像ファイル)欄には、動的なコンテンツからHTTPの「本文」を選んで入力します。
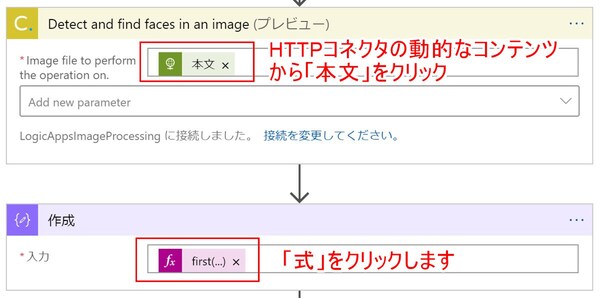
Cloudmersiveのコネクタで写真の顔部分を検出する
なお、このアクションでは画像から顔の部分を検出しますが、複数の顔が検出された場合は、その結果を配列として出力します。ただし今回は、前述のとおり無料版Cloudmersive APIの制約があり、処理を簡素化するため「最初に検出した顔だけを対象」とすることにします。
そこで次のステップでは、配列から最初の要素だけを取り出します。「データ操作」を検索して「作成」アクションを選び、設定項目の「入力」欄をクリックします。次の画面がポップアップ表示されるので、まず①「式」のタブをクリックし、②の入力欄に以下のコードをコピー&ペーストして「OK」をクリックします。

「式」の入力方法
first(body('Detect_and_find_faces_in_an_image')?['Faces'])
3-1-5. 写真の顔部分の切り抜きとぼかし処理
次は、顔として検出された部分の画像を切り抜いたうえでぼかし処理を行います。
新しいステップを追加し、先ほどと同じようにCloudmersive Image Processingコネクタを選択、今度は「Crop an image to a rectangular area」アクションを選択します。これで画像から顔の部分だけを切り抜きます。
設定項目では、次の画面に書き込んだ①~⑤の項目それぞれに「式」を入力していきます。先ほど取得した座標データを使って、画像から顔部分だけを切り抜く処理です。また末尾の「Image file to perform the operation on.」項目には、「動的なコンテンツ」からHTTPコネクタの「本文」を指定します。

設定項目①~⑤に以下の「式」または「動的なコンテンツ」を入力する
- outputs('作成')?['LeftX']
- outputs('作成')?['TopY']
- sub(outputs('作成')?['RightX'],outputs('作成')?['LeftX'])
- sub(outputs('作成')?['BottomY'],outputs('作成')?['TopY'])
- 動的なコンテンツからHTTPコネクタの「本文」をクリック
次は、切り抜いた画像にぼかし処理を行います。ステップを追加し、今度はCloudmersive Image Processingの「Perform a guassian on the input image」アクションを選択します。
設定項目の「Image file to perform the operation on.」には、動的なコンテンツから「Crop an image to a rectangular area」の「本文」を入力します。なお、「Radius in pixels of the blur operation.」はぼかし処理の半径(ピクセル数)、また「Sigma, or variance of the gaussian blur」は“にじみ”の強さを示す数値です。2つの数値を変更するとぼかし方が変わるので、試しながら最適な設定を探してみてください。

切り取った画像のぼかし処理を実行する
3-1-6. ぼかし処理済みの顔画像と透明画像を合成する
前述したとおり、ぼかし処理を行った顔の画像は、元画像の顔の部分にずれないよう合成しなければなりません。そこで、まずはぼかした顔画像をいったん透明画像と合成して、合成する位置を調整できるようにします。

ぼかし処理済みの顔画像と透明画像を合成する
ステップの追加で、Cloudmersive Image Processingの「Composite two images together」アクションをクリックします。これは2つの画像を合成するアクションですので、これを利用して、事前に作成しておいた透明画像とぼかし済み顔画像を合成します。
設定項目の「Location to composite the layered images;」は、透明画像に対する顔画像の配置位置です。ここでは「center」(中央)とします。さらにベース画像を指定する「Image file to perform the operation on.」にはDropboxコネクタの「ファイルコンテンツ」を、その上に合成する画像「Image file to layer on top of the base image.」には、ぼかし処理をした「Perform a guassian on the input image」の「本文」を、それぞれ入力します。
3-1-7. ぼかし処理済みの画像と元画像を合成
今度は1つ前のステップで処理した画像を、元画像の上から合成する処理を行います。その前に、1つ前のステップで合成した画像(ぼかした顔画像+透明画像)を、顔の位置が元画像とそろうように切り抜く処理を行います。
ステップを追加し、Cloudmersive Image Processingの「Crop an image to a rectangular area」アクションを再び選択して設定項目を入力します。ここでのポイントは、切り抜く「座標」と「高さ/幅」です。それぞれ次の内容を「式」として入力してください。なお「ciwidth」と「cihight」は、3-1-2章で初期化した変数の名前です。

1つ前のステップで合成した画像を切り抜く処理
- div(sub(variables('ciwidth'),add(outputs('作成')?['LeftX'],outputs('作成')?['RightX'])),2)
- div(sub(variables('cihight'),add(outputs('作成')?['TopY'],outputs('作成')?['BottomY'])),2)
- div(add(variables('ciwidth'),add(outputs('作成')?['LeftX'],outputs('作成')?['RightX'])),2)
- div(add(variables('cihight'),add(outputs('作成')?['TopY'],outputs('作成')?['BottomY'])),2)
- 動的なコンテンツ「Composite two images together」の「本文」をクリック

先ほど合成した画像を切り抜く処理
次は、切り抜いた画像を元画像の上から合成します。先ほども使った、Cloudmersive Image Processingコネクタの「Composite two images together」アクションを選択します。
設定項目ですが、まず「Location to composite the layered images」には「top-left」と入力して、2つの画像を画像の左上を基準点に合成するようにします。「Image file to perform the operation on.」にはHTTPコネクタの「本文」(LINEから取得した元画像)を、「Image to layer on top of the base image.」には「Crop an image to a rectangular area2」の「本文」(切り抜いた顔画像+透明画像)を入力します。
3-1-8. ぼかし処理済みの画像をDropboxに保存
顔部分のぼかし処理が済んだ画像ファイルとしてDropboxに保存します。アクションの追加で「Dropbox」を検索して「ファイルの作成」アクションを選択します。設定項目には次の内容を入力してください。

顔部分のぼかし処理を行った画像をDropboxに保存
- 処理済み画像を保存するフォルダを指定
- 「式」で「guid()」を入力し「.jpg」を追加で入力
- 「動的なコンテンツ」で「Composite two images together2」の「本文」を入力
ステップ数が多くなりましたが、以上で「A:写真から顔を検出、ぼかし処理をする」のワークフローは完成です。Logic Appsデザイナーの「保存」をクリックしましょう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第11回
TECH
AI+ノーコードで動画の字幕を自動生成するツールを作ろう -
第10回
TECH
メールで届く添付ファイルの暗号化を自動解除するLogic Appsを作ろう -
第8回
TECH
Power AutomateのRPA「UIフロー」でPhotoshopの操作を自動化してみよう -
第7回
TECH
「指定した場所に近づくとスマホに買い物リストを通知する」仕組みを作ろう -
第6回
TECH
文字入り画像を送るとテキストに書き起こすLINEボットを作ろう -
第5回
TECH
現在地から目的地までの道案内をするLINEチャットボットを作ろう -
第4回
TECH
音声認識AIを使ってLINEのボイスメッセージをテキスト変換してみよう -
第3回
TECH
自分用メモ的にLINE送信した予定をAIで読み取ってGoogleカレンダーに自動登録しよう -
第2回
TECH
AIで「alt属性」文章を自動生成しよう!もちろんノンコーディングで -
第1回
TECH
ノンコーディングで質問に自動回答するLINE BOTを作ってみよう - この連載の一覧へ




