



ロードマップでわかる!当世プロセッサー事情 第569回
性能が70%向上するCooper Lakeと200Topsの性能を持つPonte Vecchio インテル CPUロードマップ
2020年06月29日 12時00分更新

AI向けプロセッサーの話が細切れになってしまって恐縮だが、今回はやっと出荷されたCooper Lakeと、それとGPUであるXe/Ponte Vecchioのアップデートを説明したい。
Xeon E7 v4から7~8割増しの性能
Copper Lake
Cooper Lakeの発表内容はジサトライッペイ氏の記事にまとまっている。基本的にCooper LakeはCascade Lakeに少しだけ手を加えた派生型である。手を加えたのは以下のの3点となる。
- BFloat16のサポートを追加
- 動作周波数を若干引き上げ
- メモリーコントローラーを高速化(一部SKUでDDR4-3200のサポートを追加)したほか、第2世代Optane Persistent Memoryをサポート
このうちBFLOAT16に関してはAVX512ユニットそのものを拡張して、16bit FLOATをサポートする(AVX512_BF16)という、ある意味真っ当な実装になった。
ただこの実装はIce Lakeのインプリメントの「後」で始まったらしく、少なくともIce Lake世代ではサポートされていない。これが次のIce Lake-SPでサポートされるかどうかは今のところ不明である。スケジュール的に言えばIce Lake-SPでAVX512_BF16をサポートするチャンスはありそうに思う。そのBFLOAT16周りの性能比較として示されているのが下の画像だ。
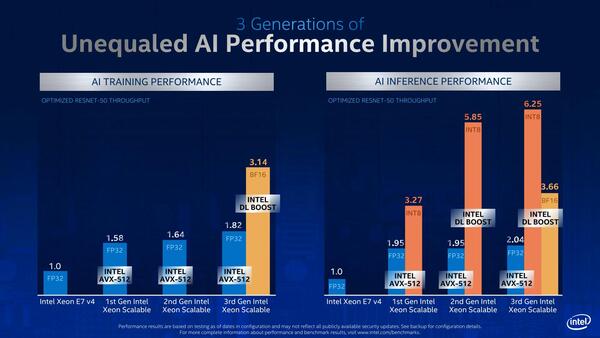
左がTraining(学習)、右がInference(推論)での性能である。BF16を使うと、TrainingでもIntel DL BOOSTが使えるというのは少しおもしろい
Xeon E7 v4を1.0とした時、TrainingにCooper LakeをFP32で使うと1.82、FB16で使うと3.14ということで、さすがに2倍にはならないものの72%ほど高速化が図れているとする。
Inferenceでは2.04→3.66なので79%ほどの高速化で、7~8割程度となる。演算ユニット的に言えば、FP32だとAVX512では1サイクルあたり16個のデータに対して演算可能なのが、BFLOAT16では32個で倍増するわけで、ピーク性能は2倍になる計算だが、その一方でデータ移動などのハンドリングの手間も増えるため、そうしたオーバーヘッドを加味すると8割弱の向上は妥当な数字だろう。
次にメモリーについて。下の画像にもあるように、Xeon Platinumは、1DPCの場合に限りDDR4-3200がサポートされた。一応Registered DIMMではあるのだが、それでも安定動作を念頭に置くと2DPCでDDR4-3200のサポートは無理だったようだ。
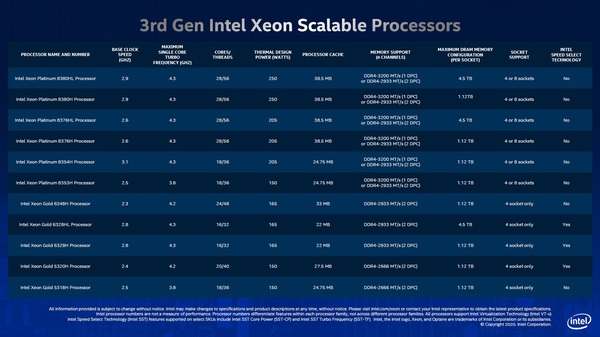
第3世代Xeon Scalableプロセッサーのラインナップ。1DPCの場合に限りDDR4-3200をサポートする
そして、Xeon Platinum 8380HL/8376HLとXeon Gold 6328HLという、末尾にLが付く製品のみ、最大メモリー搭載量が4.5TBに跳ね上がっている。これは、同時に発表されたOptane Persistent Memory 200シリーズを併用した場合の数字となっている。

同時に発表されたOptane Persistent Memory 200シリーズ。これは説明のビデオからのクリップである
この第2世代Optane Persistent Memoryは、128/256/512GBの容量のものがラインナップされており、512GBのものを各メモリーチャネルに1枚づつ装着すると6chで3TBになる。各チャネルの余ったもう1スロットに256GB DDR4-2933 DIMMを装着すると、こちらが合計で1.5TB。トータルで4.5TBとなる計算である。
もっとも容量そのものは第1世代のOptane Persistent Memoryも最大512GBなので、これをサポートしたCascade Lakeベースの、例えばXeon Platinum 8280Lも最大メモリー容量は4.5TBなので、この部分での差はない。
では第2世代Persistent Memoryはなにが良いのか? ということで下表に差異を簡単にまとめてみた。
| 第1世代と第2世代Persistent Memoryの違い | |||||||
|---|---|---|---|---|---|---|---|
| 容量 | 128GB | 256GB | 512GB | ||||
| 世代 | 第1世代 | 第2世代 | 第1世代 | 第2世代 | 第1世代 | 第2世代 | |
| 耐久性(PBW) | 100% WRITE 256B | 292 | 292 | 363 | 497 | 300 | 410 |
| 100% WRITE 64B | 91 | 73 | 91 | 125 | 75 | 103 | |
| 帯域(GB/s) | 100% READ 256B | 6.80 | 7.45 | 6.80 | 8.10 | 5.30 | 7.45 |
| 100% WRITE 256B | 1.85 | 2.25 | 2.30 | 3.15 | 1.89 | 2.60 | |
| 100% READ 64B | 1.70 | 1.86 | 1.75 | 2.03 | 1.40 | 1.15 | |
| 100% WRITE 64B | 0.45 | 0.56 | 0.58 | 0.79 | 0.47 | 0.65 | |
まず耐久性はPBW(Peta Bytes Written)で示すが、要するにどの程度書き込むと寿命が来るかという数値である。フラッシュメモリーベースのSSDでは、これが1.0~1.5PBWが寿命であるが、Optane Memoryベースということで100倍以上寿命が長い。128GB品を除くと第2世代はさらに寿命が増えている。
帯域は256Byteと64Byteの単位で、それぞれリード/ライトを行なった場合の実質的なアクセス帯域だが、それぞれ多少増えていることがわかる。ドラマチックに2倍以上にはならないが、それなりに性能が向上している。
最後に動作周波数についてだが、これはイッペイ氏の記事にもあるように2~3binほど向上している。ただAVX512_BF16の追加もあってか、消費電力はさらに上がっており、損得勘定を考えると難しいところである。
ところでこのCooper Lake、もともと広く一般に販売するというよりは、特定顧客向けになるという話が出ていた。フタを開けてみると、4Sないし8S向け「のみ」となっており、こうなると本当に特定の顧客以外は使いそうにない構成になっている(現在の主流は1~2ソケットサーバー)。
またコア数も最小で16というあたり、おそらくCooper LakeはLCC(Large Core Count)のダイしか存在しないものと思われる。また、モノがモノだけに、Xeon W向けの展開の可能性も非常に低そうだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")




































