
MLやコンテナ活用が目立った第8回X-tech JAWS前半レポート
X-Tech JAWSで聞いたナビタイム、Resola、千のAWSの使いこなし
2019年07月16日 07時00分更新

2019年7月11日、「時代を突き抜けるX-Tech企業の真髄」をタイトルにした第8回目となるX-Tech JAWSが開催された。ビジネスとテクノロジーという両面でさまざまな業界でのAWSの使いこなしを学びあうX-Tech JAWS。今回は前半となるナビタイムジャパンやResola、千のセッションをサポートする。
EC2フリートでスポットとリザーブドをうまく活用するナビタイム
冒頭、LTとして「オンデマンドインスタンスを極限まで減らしたらこうなった」を披露したのは、会場提供元であるナビタイムジャパン田中一樹さんだ。ナビタイムではほとんどのサービスでAWSを用いているが、既存システムから移行するのにともない利用費用が激増。「AWS使ってるのに、なんでこんなにかかってるの?」という経営陣の声に応え、コスト削減に取り組んだのが今回のテーマだ。

ナビタイムジャパン 田中一樹さん
ナビタイムのシステムはEC2ベースのECSでコンテナを管理しているため、コストが上がっていた。もちろん、ECSをやめて、サーバーレスのFargateを使うという手段もあったが、ストレージが10GBしかないので、地図や探索データが格納できなかった。結局、ECSのときと必要な台数が変わらなかったほか、障害時の調査方法がまだまだクラウドネイティブになっておらず、調査に時間がかかりそうで、Fargateの利用は断念した。
EC2と手切れするのが難しいということで、EC2インスタンスのコスト削減に手を付けた。EC2にはいくつかの購入形態があるが、同社では年間契約することで割引が効くリザーブドインスタンスを毎年かなりの数を購入しており、高い利用率をキープしている。「確保しにくいインスタンスもAZごとに購入しており、バランスよく使っている」(田中さん)。また、ダウンするリスクを許容することで最大9割の値引きが行なわれるスポットインスタンスも、オンデマンドインスタンスの半分程度の価格で入札。スポットインスタンスのローテーションを条件にあわせて自動的に管理しているスポットフリートの機能で管理していた。
さらに2018年5月には「EC2フリート」を利用することにした。EC2フリートは、同じオートスケーリンググループで、オンデマンド、スポット、リザーブドなどの混在したインスタンスの台数や割合等を指定できるEC2の管理機能。CPUベースでスケールアウトするので、同じコア数のリザーブドインスタンスを指定し、今回はオンデマンドをゼロに指定。これにより、変更直後からオンデマンドが減り、ほとんどリザーブとスポットになったという。
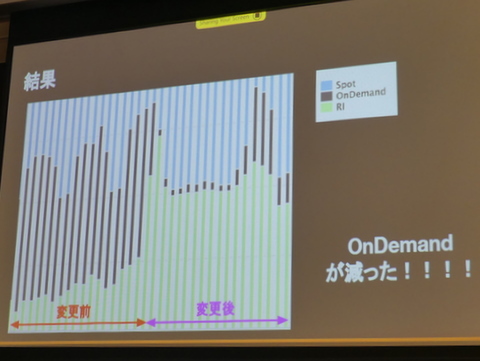
オンデマンドインスタンスがいったんは減ったが……
しかし、変更後、途中からオンデマンドが増えて来たという。EC2フリートでは、極力先頭のインスタンスタイプで起動するのだが、起動できない結局後続のインスタンスタイプを使ってしまう。後続のインスタンスタイプはリザーブドで購入していないので、オンデマンドで起動してしまうわけだ。
田中さんは、「EC2フリートを使えば、リザーブドとスポットだけの構成がみなさんでも簡単に作れますが、予想外のオンデマンド起動にだけは気をつけてください。あとスポットインスタンスは余裕で落ちるので、ドレイニング(Draining)処理をきちんと入れておくと、うまくいくと思います」とまとめた。
行動と会話のデータでパーソナライズ対応を実現する「SYNALIO」
2番手はマーケティングプラットフォーム「SYNALIO(シナリオ)」を手がけるResola(リソラ)代表取締役社長、ギブリー取締役の奥田栄司さんだ。半分が外国人で構成されるエンジニア集団であるResolaは、今回紹介するSYNALIOを開発しており、技術やライセンスを顧客やグループ企業であるギブリーに提供している。

Resola 代表取締役社長、ギブリー 取締役 奥田栄司さん
ResolaのSYNALIOは簡単に言えば、「マーケティング向けのチャットボットツール」だという。もともとは「インターネットでの企業と消費者間の情報伝達方法をアップデートしたい」という目的で作られており、20年来用いられてきたユーザーによるキーワード検索から、ユーザーに最適な情報提供を実現するために作られた。
これまでのマーケティングツールは、Webサイトに来た訪問者の行動データをベースにユーザーをスコアリング・クラスタリングして、ステップメールやキャンペーンを展開するものだった。しかし、そもそも行動してくれないとユーザーがターゲティングできないという点と、行動からは見えてこない「非観測要因」が見えないため、ユーザーが意思決定しにくいという弱点がある。
この解決方法として、SYNALIOは「なにを探しているか」を理解するための行動データに加え、「ユーザーがなぜを探しているのか」という会話データをチャットから取得。これらのデータを分析することで、1人ごとに最適な会話のシナリオを作り、異なるスコアリングと接客を実現していくという。
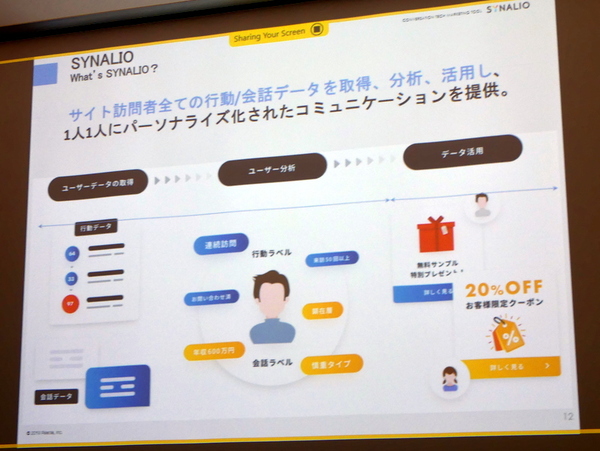
サイト訪問者全体の行動/会話データをベースにパーソナライズドされたコミュニケーションを実現
たとえばリスティング広告からサイトに訪問し、2分間滞在したユーザーに対しては、離脱を防ぐために最新のランキングを提案。ユーザーがランキングから商品ページまで進んだら、スコアを格上げする。ここまで来たら、ほしい商品はわかっているので、「なぜ探しているのか?」をチャットで聞き出す。ここで「彼氏の誕生日プレゼント」「予算は3万円」まで引きだせば、最適な商品をリコメンドでき、クロージングアクションにまで至るわけだ。
これらSYNALIOの行動データ・会話データはダッシュボードや各種レポートのほか、ポップアップやチャットウインドウの出し分けに用いられる。ユーザー属性と行動にあわせてウィンドウを出し分け、最適なものを学習していくという。
取得している行動データは、「どのチャネルから訪問したのか」「どのページに何秒滞在したのか」「何度目の訪問か」「デバイス・OS・ブラウザ」などのページビューと、「チャットボットを表示した」「チャットボットを使った/意図的に閉じた」「ポップアップを表示した」「ポップアップをクリックした/意図的に閉じた」などのイベントデータになる。ポイントとしては、Google Analysticに近づけ、利用感を共通化させているとおこと。また、会話データはユーザーが押した会話内容、特定の会話に到達した際るラベルに付与、決裁権限者などにラベルを付与する。
取得した行動データは大量になるのでまずは生データ用のS3バケットに送り、EC2上のETLサーバーで前処理を行なうS3へ。一方の会話データと行動データを統合されたデータはETL処理で不要なものを除去し、EC2上で分析され、ダッシュボードに表示される。また、会話データはSageMakerによる機械学習でも利用され、生成済みのモデルはユーザーごとに最適なポップアップを表示するのに用いられる。
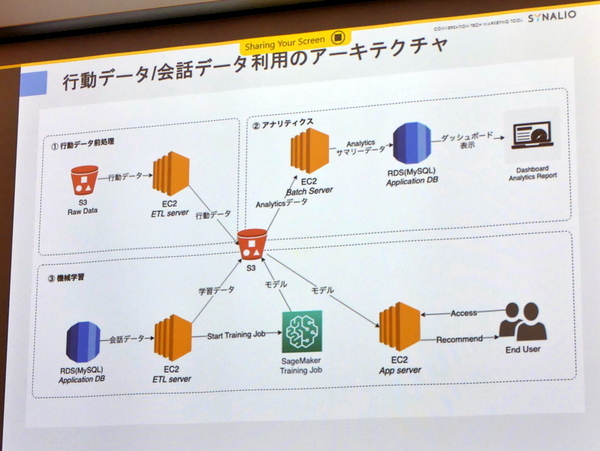
行動データ/会話データ利用のアーキテクチャ
今後の展開としては、「自動運転レベル3」のように特定の場所でシステムがすべて操作し、緊急時にドライバー操作するくらいのレベルまで引き上げたいという。具体的にはラベルの自動付与、ラベルのアトリビューション(貢献度)分析、AIによるサジェスト、クロスカンパニーデータの利用、システムによる自動改善まで進めたいという。
1万枚の写真から我が子を探せる顔検索の実現
3番手は千の吉田健太さん。千が提供する「はいチーズ!」は幼稚園や保育園での撮影代行サービス。プロカメラマンが園児1人1人が主人公となる写真を撮影するだけではなく、写真の印刷や掲示、代金回収までをカバーしており、日本国内で6000団体の利用があるという。

千 吉田健太さん
はいチーズで昨年導入されたのが、写真を選ぶ際の顔検出機能だ。従来の幼稚園や保育園では、数多くのイベント写真から探す必要があり、我が子を選ぶのは一苦労。実際、とある幼稚園の運動会の写真は約1.3万枚を超えていた。しかし、ユーザーとなる保護者は共稼ぎ世帯も多いので、写真探しに時間をかけられない。しかし、顔検索機能があれば、忙しいパパ・ママも我が子の写真をスマホから簡単に探すことができる。
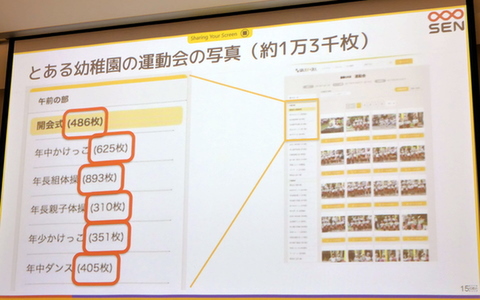
とある幼稚園の運動会の写真は1万3000枚を超えていた
この顔検出で採用したのがAmazon Rekognitionだ。Amazon Rekognitionは学習済みAIを利用できるマネージド型の画像認識サービスで、画像内の物体やシーン、顔などの検出、表情の分析、写真内にある顔と顔が似ているかも検出できる。初期コスト不要で、使った分のみの従来課金というメリットのほか、処理速度も高速で、試作品で試したところ精度も十分だった。「子どもの顔は大人の顔より特徴量が少ないので学習が難しいが、きちんと検出できた」と吉田さんは語る。
具体的なRekognitionで実現した購入フローとしては、まず保護者が子どもの写真をアップロードすると、同じ顔の写真を検索して候補を表示してくれるというもの。また、過去に購入した写真から子どもの顔を抽出し、おすすめ写真として表示するという機能も実装した。顔研修導入の結果、ビューに対して購入した割合に当たるコンバージョン率が向上し、忙しいパパ・ママの写真探しも容易になったという。
技術的な悩みとしては、1万枚以上の写真の学習をどうするか?これに対してRekognitionは「コレクション」という機能があり、検出した顔に関する情報をサーバー側のコンテナに保存することができる。特徴ベクトルをあらかじめインデックスできるようになるため、APIを1回叩くだけで高速な検索が可能になる。
この顔コレクションで利用するAPIは「顔コレクションを作成する(CreateCollection)」「顔のメタデータを顔コレクションに追加する(IndexFaces)」「指定した画像で顔コレクション内の類似画像を検索する(SearchFacesByImage)」の3つ。前述の通り、Rekognitionの顔コレクションは特徴情報(メタデータ)のみ保持しており、検索画像はすべてS3に保存されている。吉田さんはAWS CLIから顔写真のアップロードや検索のデモを披露。顔検索が容易に利用できるRekognitionのメリットをアピールした。
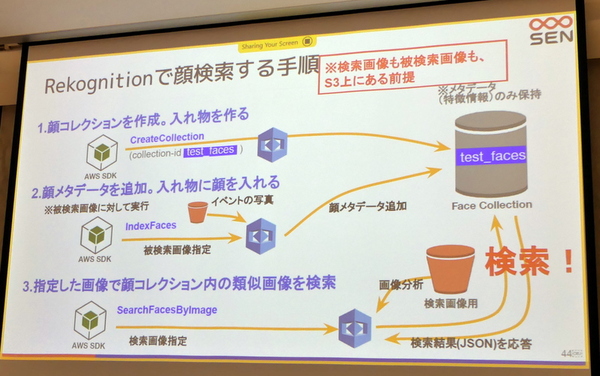
Rekognitionで顔検出するまでの手順
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第26回
デジタル
コロナ禍で社会インフラとなった保育園 ルクミーはこうして支えている -
第25回
デジタル
オンライン診療の規制緩和にいち早く対応したMICINの新機能開発 -
第24回
デジタル
「Cariot」のリアルタイム性を強化するKinesis、Lambda、DynamoDBの整え方 -
第23回
デジタル
Timers、POL、PIAZZAなどがビジネスと技術を語る第10回X-Tech JAWS -
第22回
デジタル
メンヘラ彼女向けのサービスを1週間で開発させられた話 -
第21回
デジタル
教育市場を盛り上げる「AWS EdStart」と「AWS Educate」 -
第20回
デジタル
AIで時事クイズと高校野球の戦評記事を作ってみた -
第19回
デジタル
おやつのサブスク「snaq.me」でのLambda活用術 -
第17回
デジタル
契約書のレビューを支援するLegalForce、CTOと事業開発担当が語る -
第16回
デジタル
「SQL書きたい」のリクエストにukkaのエンジニアはどう応えたのか? - この連載の一覧へ




















")

