
AI×メディアの可能性を追求する朝日新聞社のチャレンジ
AIで時事クイズと高校野球の戦評記事を作ってみた
2019年09月10日 10時00分更新

2019年4月23日の第7回目のX-Tech JAWSの2番手はAI×メディアの可能性を追求し続ける朝日新聞社。昨年のAWS Summit 2018では記事の見出しを自動生成する取り組みを披露したが、今回のX-Tech JAWSでは時事クイズと高校野球の戦評記事をAIで作るという話だった。

朝日新聞社 情報技術本部 開発部 佐渡昭彦さん
楽しくニュースに触れられる時事クイズをAIで作る
続いて登壇したのは朝日新聞社 情報技術本部 開発部の佐渡昭彦さん。佐渡さんは長らくサイトのセキュリティ対策を長らく手がけ、米国留学を経て、いまは情シス内R&D部門である「ICTRAD」でAI活用を検討している。今回は「メディアにおけるAI活用とAWSに期待すること」と題して、昨年取り組んだ時事クイズと高校野球戦評記事の自動生成の舞台裏を語った。
時事クイズとは、毎日大量に出稿されるニュース記事を利用して作られたクイズだ。「最近は新聞がとられないだけではなく、ニュースも読まれなくなっている。だから、まずは時事ニュースに触れる機会を増やそうと考えた」(佐渡さん)ということで作られたという。新聞記事から正解となる重要語を抽出し、単語の特徴を数値化した「単語ベクトル」に基づいて選択肢を検出し、時事ニュースがテーマの4択クイズを作るというのがおおまかなフローになる。

時事クイズの生成フロー
最初の重要語抽出は自然言語処理サービスの「AWS Comprehend」を使おうとしたが、残念ながら日本語に未対応だった。そのため、東大・横国大がオープンソースで公開している「専門用語自動抽出システム」を活用した。50万件の過去記事を学習し、重要語を抽出。抽出した重要語はスコア付けされ、選択肢の中で利用されることになる。
続いて、抽出された重要語を単語ベクトルで表現する。単語ベクトルで表現すると、たとえば「王」という単語から「男」をひいて、「女」を足すと、「女帝」や「女王」、「君王」「クイーン」などの単語が引っ張られてくる。朝日新聞社は記事800万件から学習した「朝日単語ベクトル」を公開しているので、これを使えばクイズの選択肢で利用しやすい類似度の近い言葉を検出できるわけだ。
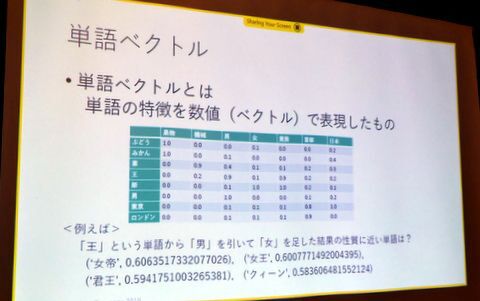
単語ベクトルとは?
とはいえ、最初はギャグとも思えるクイズも提案されてきた。たとえば、「12日の_で最大の焦点となるのは、北朝鮮の非核化の行方だ。」というクイズ。答えは「米朝首脳会談」だが、「米朝」という固有名詞を考慮したため、選択肢には桂米朝師匠をはじめとした落語家の名前が並んだという。また、答えが「ソフトバンク」となる経済記事のクイズでも、本来はIT企業が選択肢として並べてほしいのだが、野球チームが並んでしまうという。言語というものの扱いの難しさを感じる逸話だ。

米朝ってそっちですか
なお、システム構成はほぼAWSを採用。取得した記事データをElasticSearchに格納し、毎日クイズを作っているのだが、フロントはGCPを利用している。「ユーザーアクセスはGCPを使っています。SNS認証はGCPの方が簡単に作れる」と佐渡さんは語る。ここらへんはAWSのサービスに期待したいところだ。
記者でも見分けが付かなかった高校野球の戦評記事
続いて高校野球の戦評記事の自動作成に話が移る。戦評記事とは野球の試合のポイントを短い文字数(100~150文字)で伝える記事。電子スコアが整備されたこと、そして高校選抜野球が100回目という記念だったこともあり、自動生成にチャレンジした。
佐渡さんが2つの戦評記事を参加者に披露し、どちらが記者が書いたのかを聞いたところ、ほとんどが当たった。「『まさか入るとは思わなかった』と笑った」や「『好調が続いている感じ。リラックスして打席に入れている』と充実感をにじませた」といった表現は、やはり直接取材をした記者にしか書けない。ところが、続いての戦評記事はもはや記者か、自動生成かなかなか判断できない。会場でも約半分が間違え、記者でも判断が困難だった。事実ベースであれば、このレベルまで自動作成可能と言うことだ。

記者でも判断が困難だったというAIによる戦評記事
当初はスコアテーブルと戦評記事のペアを学習データとし、こういう試合では、こういう戦評になるということをAIで学習させようとしたが、過去のスコアブックの多くが手書きだったため断念。正確さを欠いた表現が許容されないという社風もあるため、「『満塁ホームランを打たれて、投手が泣いた』という戦評を学習してしまうと、事実ではなくても『投手が泣いた』という部分が出てきてしまう(笑)」(佐渡さん)というこの方法は採用されなかった。
そのため、ルールに基づいた戦評記事を自動生成するという方法を採用した。戦評記事とスコアデータ8万件に対して、関連づけやクレンジングを施し、戦評記事から試合の流れを分類し、さらにスコアデータから試合の流れを分類した。その上で、抽出したワードを含む記事をベクトル化したり、K-Meansで50種類にクラスタリングして、代表的な戦評記事をテンプレート化した。
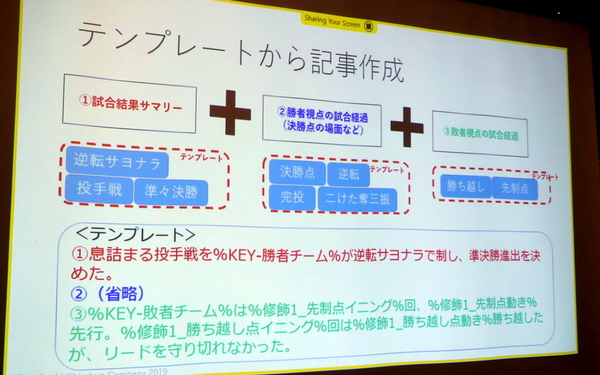
代表的な戦評記事をテンプレート化して記事作成
試合結果サマリー+勝者視点と敗者視点の試合経過のそれぞれにテンプレートがあるので、わりと杓子定規にはなるが、とりあえず事実を伝える戦評記事の自動生成はEC2インスタンス1台で完成した。それでも、「2ランスクイズ」のような希有な事象には対応できないし、スコアブックにないデータは載せられない。「この方法をやっている限りは積み重ねが必要という反省はある」という佐渡さんの弁だ。
佐渡さんは、「朝日新聞社の資産は毎日生成される記事と写真」「AI(機械学習)を活用して新しいことにも挑戦」「AWSを含めたインフラやツールは適材適所で利用」などを挙げ、最後に日本語の地黄処理サービスや画像認識、SNSとの連携などまだまだ弱い部分のあるAWSのサービスの進化に期待した。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第26回
デジタル
コロナ禍で社会インフラとなった保育園 ルクミーはこうして支えている -
第25回
デジタル
オンライン診療の規制緩和にいち早く対応したMICINの新機能開発 -
第24回
デジタル
「Cariot」のリアルタイム性を強化するKinesis、Lambda、DynamoDBの整え方 -
第23回
デジタル
Timers、POL、PIAZZAなどがビジネスと技術を語る第10回X-Tech JAWS -
第22回
デジタル
メンヘラ彼女向けのサービスを1週間で開発させられた話 -
第21回
デジタル
教育市場を盛り上げる「AWS EdStart」と「AWS Educate」 -
第19回
デジタル
おやつのサブスク「snaq.me」でのLambda活用術 -
第18回
デジタル
X-Tech JAWSで聞いたナビタイム、Resola、千のAWSの使いこなし -
第17回
デジタル
契約書のレビューを支援するLegalForce、CTOと事業開発担当が語る -
第16回
デジタル
「SQL書きたい」のリクエストにukkaのエンジニアはどう応えたのか? - この連載の一覧へ




















")

