さとうなおきの「週刊アジュール」 第97回
「Build 2019」アップデート ~データ編~
Azure Cosmos DBがSparkやJupyterノートブックをサポート
2019年06月10日 13時00分更新

こんにちは、さとうなおきです。2019年5月6日~8日にかけて、米国シアトルでMicrosoftの年次カンファレンス「Microsoft Build 2019」が開催されました。「週刊アジュール」では、Build前週の事前発表、基調講演での発表をまとめた「Build 2019」特別号外に続いて、Build 2019でのAzureアップデートを、インフラ編、アプリ開発編、データ編、AI/IoT編の4回に分けてお伝えします。今回はデータ編です。
Azure Cosmos DB:Spark、Jupyter、etcdなど
Azure Cosmos DBは、複数のデータモデル/APIをサポートしたグローバル分散型のNoSQLデータベースサービスです。
Azure Cosmos DBで、次のアップデートが発表されました。
- Apache Sparkの組み込みサポート(プレビュー):Azure Cosmos DBのデータに対して、Azure Cosmos DB上でSparkを使った分析を実行可能
- Jupyterノートブックの組み込みサポート(プレビュー):すべてのAzure Cosmos DB API/データモデルで、ノートブック エクスペリエンスをネイティブにサポート
- etcd APIのサポート(プレビュー):分散キー/値ストアであるetcd APIをサポート。セルフマネージドのKubernetesクラスターでetcdクラスターを管理する代わりに利用可能
- (特に集計クエリの)クエリ実行のコストパフォーマンスの大幅な向上
- SQL APIの新しいSQLクエリ機能:OFFSET/LIMIT、DISTINCT、複合インデックス、相関サブクエリ
- Gremlin APIの拡張:パフォーマンス評価用の実行プロファイル関数、Apache Tinkerpop仕様に合わせた文字列比較関数
- Cassandra APIの拡張:Cassandra CQL v4とのほぼ完全な互換性、CQL拡張コマンドとしての変更フィード
- Azure Cosmos DB .NET V3 SDK(GA)
- Azure Cosmos DB Java V3 SDKの機能強化
- Java用変更フィードプロセッサ
- クロスプラットフォームのTable .NET Standard SDK(GA)
- Azure Resource Managerが、データベース、コンテナー、オファーをサポート
- Azure Cosmos DBオペレーターロール
- アカウントの単一リージョン書き込みから複数リージョン書き込みへのアップグレード
- 固定コンテナーから無制限のコンテナーへの自動アップグレード
- Azure Cosmos DB ExplorerでのAzure Active Directoryのサポート
- Azure Portal、Azure Advisorの機能強化
詳細は、次のページをご覧ください。
- 更新情報「すべての Azure Cosmos DB API にノートブックのサポートのプレビューを提供開始」
- 更新情報「etcd 向け Azure Cosmos DB API のプレビューを提供」
- 更新情報「Azure Cosmos DB の強化された SQL API クエリ機能の提供を開始」
- 更新情報「Azure Cosmos DB 用のアップグレード済み Gremlin API 機能の提供を開始」
- 更新情報「Azure Cosmos DB の強化された Azure Resource Manager のサポートを開始」
- 更新情報「ロール ベースのアクセス制御 (RBAC) の Azure Cosmos DB オペレーター ロールの提供を開始」
- ブログポスト「Azure Cosmos DB による世界規模の運用分析と AI」
- ブログポスト「Cosmos 開発者向けの Azure Cosmos DB に関する最新発表」
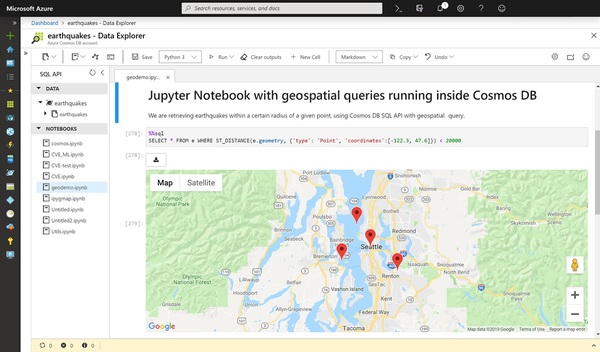
Azure Cosmos DBによるJupyterノートブックの組み込みサポート
Azure SQL Database:Hyperscale、サーバーレス、Edgeなど
Azure SQL Databaseは、SQL Serverベースのリレーショナルデータベースサービスです。
2018年9月のIgnite 2018カンファレンスで発表されパブリックプレビューになっていた「Azure SQL Database Hyperscale」が、GA(一般提供)になりました。
Azure SQL Database Hyperscaleでは、コンピューティングとストレージを個別にスケーリングできます。ストレージは、最大100TBです。
- 更新情報「単一データベースに対する Azure SQL Database Hyperscale のサポートが利用可能」
- ブログポスト「Hyperscale を使用して Azure データベース ワークロードでハイパフォーマンス スケーリングを実現する」
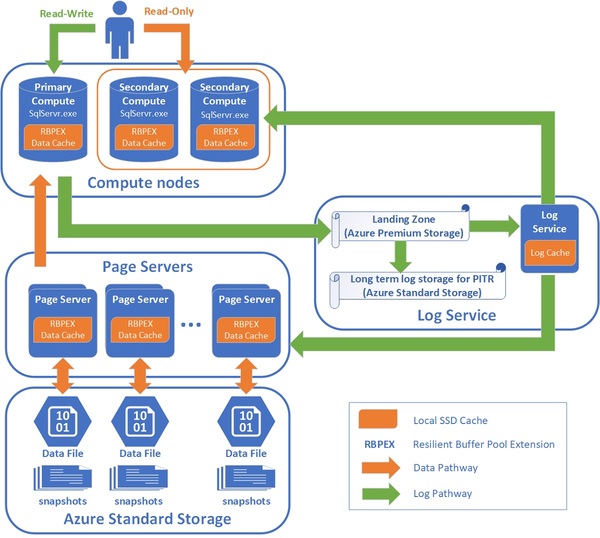
Azure SQL Database Hyperscale
「Azure SQL Database サーバーレス」が発表され、プレビューが始まりました。
Azure SQL Database サーバーレスは、使用量が断続的で予測不可能なデータベースのパフォーマンス管理を簡素化する、Azure SQL Databaseの新しいコンピューティングレベルです。ワークロードの需要に基づいて単一データベースのコンピューティングを自動的にスケーリングし、秒あたりのコンピューティング使用量に対して請求を行います。アイドル時には、自動的に一時停止します。
- 更新情報「Azure SQL Database サーバーレス」
- 更新情報「Azure SQL Database サーバーレス コンピューティング レベルのプレビュー提供」
- ブログポスト「Hyperscale を使用して Azure データベース ワークロードでハイパフォーマンス スケーリングを実現する」
- ブログポスト「Azure SQL Database サーバーレス レベル: コンピューティング能力の自動スケーリング、料金とパフォーマンスのバランスの最適化」
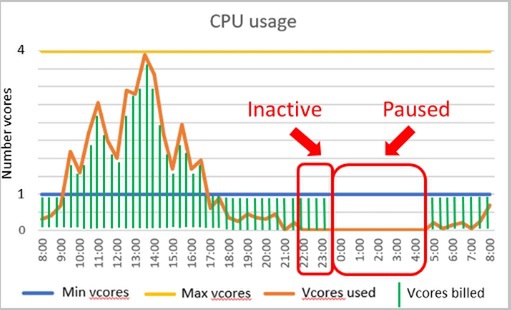
Azure SQL Database サーバーレス
Build 2019カンファレンスの前週に、「Azure SQL Database Edge」が発表され、プライベートプレビューが始まっていました。
Azure SQL Database Edgeは、組み込みのAI機能を備えた、フットプリントの小さい、エッジに最適化されたデータエンジンです。
- ブログポスト「Azure SQL Database Edge:エッジでインテリジェント データを有効にする」
- ブログポスト「データ、IoT、および複合現実にわたるインテリジェント エッジのイノベーション」
Azure Data Studioは、SQL Server、Azure SQL Database、Azure SQL Data Warehouseでのモダンなデータベース開発、運用のための、Windows、macOS、Linuxで動作する軽量なツールです。
4月リリースに続いて、Azure Data Studioの5月リリースが利用可能になりました。このリリースでは、スキーマ比較の拡張機能がプレビューになりました。
Data Migration Assistant(DMA)は、SQL ServerからSQL Serverの新バージョンやAzure SQL Databaseへの移行を支援するツールです。
2018年11月にプレビューになっていた、Data Migration Assistantの移行先Azure SQL Database SKU推奨機能での、Azure SQL Database Managed Instanceのサポートが、GAになりました。
Azure Database for PostgreSQL:Hyperscale (Citus)、pg_auto_failover
Azure Database for PostgreSQLは、PostgreSQLベースのリレーショナルデータベースサービスです。
2月に、Microsoftは、PostgreSQLデータベースをスケールアウトさせるテクノロジを持つCitus Dataの買収を発表していました。
今回、Citus Dataのテクノロジを活用した「Azure Database for PostgreSQL Hyperscale (Citus)」が発表され、プレビューが始まりました。
Azure Database for PostgreSQL Hyperscale (Citus)を使うと、Azure Database for PostgreSQLをスケールアウトできます。
- 更新情報「Azure Database for PostgreSQL での Hyperscale (Citus) のプレビュー提供」
- ブログポスト「Hyperscale を使用して Azure データベース ワークロードでハイパフォーマンス スケーリングを実現する」
- ブログポスト「Introducing Hyperscale (Citus) on Azure Database for PostgreSQL」
Citus Dataのテクノロジを活用した「pg_auto_failover」が、オープンソースとして公開されました。pg_auto_failoverは、PostgreSQLクラスターの自動フェールオーバーのための拡張機能/サービスです。
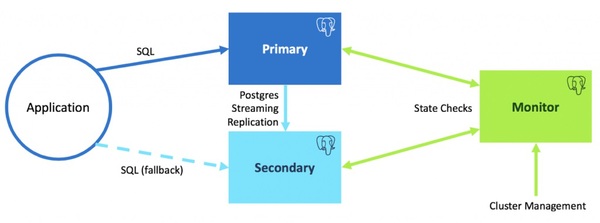
pg_auto_failover
Azure Database Migration Service:OracleからAzure Database for PostgreSQLへのオンライン移行
Azure Database Migration Serviceは、データベースのAzureへの移行を支援するサービスです。
Azure Database Migration Serviceで、OracleからAzure Database for PostgreSQLへのオンライン移行がプレビューになりました。
Azure Data Factory:マッピングデータフロー
Azure Data Factoryは、データ統合サービスです。
Azure Data Factoryの「マッピングデータフロー」が発表され、パブリックプレビューになりました。
マッピングデータフローでは、データ変換を視覚的に設計、デバッグ、管理、運用できます。マッピングデータフローは、内部でAzure Databricksを使っています。
Azure Data Factoryの「ラングリングデータフロー」(Wrangling Data Flows)が発表され、プレビューが始まりました。
ラングリングデータフローでは、コードを記述することなく、視覚的にデータの準備/ラングリングを行うことができます。
- 更新情報「Mapping Data Flows feature is now available in Azure Data Factory」
- ブログポスト「Azure での分析では常に他に類を見ない新たなイノベーションを取り入れています」
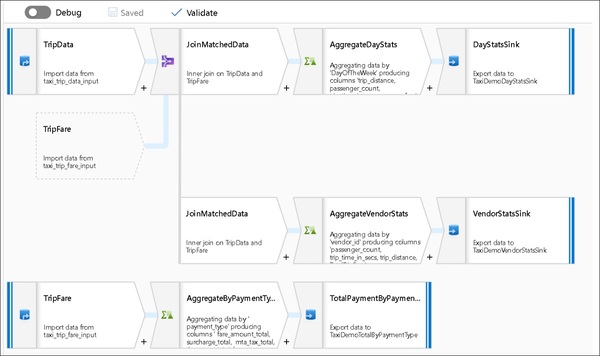
Azure Data Factoryのマッピングデータフロー
Azure SQL Data Warehouse:結果セットのキャッシュ、具体化されたビューなど
Azure SQL Data Warehouseは、SQL Serverベースのデータウェアハウス(DWH)サービスです。
Azure SQL Data Warehouseで、次のアップデートが発表されました。
- 結果セットのキャッシュ(プレビュー):対話型のダッシュボードで有効
- 具体化されたビュー(プレビュー):パフォーマンスを改善
- 順序付けされたクラスター化列ストアインデックス(プレビュー):高速なスキャン
- ワークロードの重要度(GA):3月にプレビュー
- JSONデータのクエリ、管理(プレビュー):構造化/半構造化データの両方をサポート
- 統計情報の自動メンテナンス/更新(プレビュー)
- 動的データ マスク(DDM)(プレビュー):機密データの保護
詳細は、次のページをご覧ください。
- ブログポスト「Azure SQL Data Warehouse releases new capabilities for performance and security」
- ブログポスト「Azure での分析では常に他に類を見ない新たなイノベーションを取り入れています」
Azure HDInsight:自動スケール、HBase書き込みアクセラレータ
Azure HDInsightは、Hadoop、Sparkなどのマネージドサービスです。
Azure HDInsightの自動スケール機能が、プレビューになりました。
自動スケールは、負荷や事前定義されたスケジュールに基づいて、HDInsightクラスターを自動的にスケールアップ/ダウンします。
- 更新情報「Azure HDInsight の自動スケーリングのプレビュー提供」
- ブログポスト「Drive higher utilization of Azure HDInsight clusters with autoscale」
Azure HDInsightで、HBase向けの書き込みアクセラレータ機能がプレビューになりました。
これは、Azure Premium SSDマネージドディスクを使用して、Apache HBaseのログ先行書き込み(WAL)のパフォーマンスを向上させます。
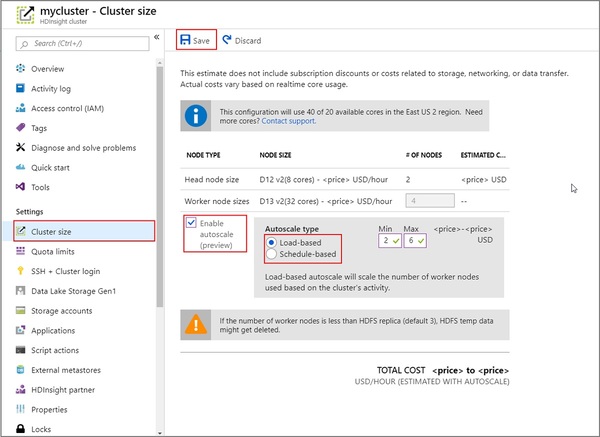
Azure HDInsightの自動スケール
Azure Data Explorer:Sparkコネクタ、Pythonプラグインなど
Azure Data Explorerは、大規模データに対してアドホッククエリを実行できる、データ探索サービスです。
Azure Data Lake Storageは、スケーラビリティ、パフォーマンス、コスト効率に優れたビッグデータ分析向けのデータレイクソリューションです。
- Sparkコネクタ(パブリックプレビュー)
- Pythonプラグイン(パブリックプレビュー)
- Azure Data Lake Storage Gen 2に対するクエリ(パブリックプレビュー)
- 継続データエクスポート(パブリックプレビュー)
詳細は、次のページをご覧ください。
- 更新情報「Azure Data Explorer と Python および Spark のより緊密な統合のパブリック プレビュー」
- 更新情報「ADLS Gen 2 と深く統合するための Azure Data Explorer 機能のパブリック プレビュー」
- ブログポスト「What’s new in Azure Data Explorer at //Build 2019」
Azure Stream Analytics:Visual Studio Code、カスタムデシリアライザー
Azure Stream Analyticsは、リアルタイムストリーム処理サービスです。
Azure Stream Analytics for Visual Studio Codeが、プレビューになりました。これを使うと、Visual Studio Code上でAzure Stream Analyticsジョブの開発、管理、テストが可能になります。
Azure Stream Analytics で、カスタムデシリアライザーのサポートがプレビューになりました。Parquet、Protobuf、XMLなど、あらゆるバイナリ形式について、C#でカスタムデシリアライザーを実装できるようになります。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第155回
TECH
「Ignite 2021」で発表されたAzureアップデート《AI/IoT編》 -
第154回
TECH
「Ignite 2021」で発表されたAzureアップデート《データ編》 -
第153回
TECH
「Ignite 2021」で発表されたAzureアップデート《アプリ開発編》 -
第152回
TECH
「Ignite 2021」で発表されたAzureアップデート《インフラ編》 -
第151回
TECH
「Ignite 2021」で発表されたAzureアップデート《ハイブリッド/セキュリティ編》 -
第150回
TECH
Azure CDNが準リアルタイムのログ/メトリックをサポート -
第149回
TECH
「Ignite 2020」で発表されたAzureアップデート《AI/IoT編》 -
第148回
TECH
「Ignite 2020」で発表されたAzureアップデート《データ編》 -
第147回
TECH
「Ignite 2020」で発表されたAzureアップデート《アプリ開発編》 -
第146回
TECH
「Ignite 2020」で発表されたAzureアップデート《インフラ編》 -
第145回
TECH
「Ignite 2020」で発表されたAzureアップデート《ハイブリッド/セキュリティ編》 - この連載の一覧へ