




ROMPとは対照的な贅沢な構成
ROMPとの違いは、むしろ実装面にあるだろう。2μmというかなり大きな(いや、当時としては標準的なのだが)プロセスで、しかもダイサイズとチップ数を削減するために、ROMPではキャッシュの類を徹底的に減らさざるを得なかった。
実際ROMPの場合、プロセッサー本体よりもMMUの方が大きいというのは、MMUは要するにアドレス管理テーブル=SRAMの塊であって、SRAMは通常のロジックよりもどうしても大きくならざるを得ない。なにせ1bitの記憶領域に6~8トランジスタを必要とするため、32bitのエントリーを1つ作るだけで200トランジスタ以上を要する。
キャッシュも同じでこれもSRAMの塊である。かくしてROMPはキャッシュやバッファなどを最小限に抑え、それでも性能が出るような工夫をした結果として、メモリーアクセスの速度で性能が決まるようなアーキテクチャーになってしまった。
対してAMERICA architectureでは命令/データキャッシュに加えてMMUやTLBまで内蔵する、ROMPとは極めて対照的な「贅沢」な構成である。性能を優先にするとどうしても贅沢な構成にならざるを得ないというのは最近でも同じなのだが。
結果、このAMERICA architectureの最初の実装であるRIOS-1の構成図が下の画像だが、もうまんま前述のCPU概念図の構成そのまま、ということがわかる。
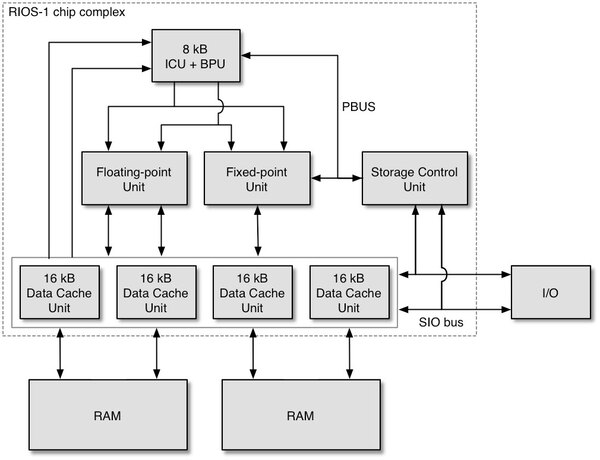
RIOS-1の構成図。chip complexだけで8チップが必要。ただし実際にはこれらのユニットが必ずしも1チップで実現しきれなかったため、10チップに膨れ上がった
画像の出典は、Wikipedia
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























