



IBM THINK 2018で発表された「ICP for Data」「Watson Studio」「Watson Assistant」など紹介
「ビジネスのためのクラウドとAI」日本IBMが新製品と戦略説明
2018年05月15日 07時00分更新

日本IBMは2018年5月14日、「IBM Cloud」および「IBM Watson」に関する事業戦略のアップデートを行う記者説明会を開催した。3月に米国で開催された「IBM THINK 2018」で発表された新製品/サービス群も含め、「データとAIの時代」を迎えるための新たな方向性も示している。

日本IBM 取締役専務執行役員 IBMクラウド事業本部長の三澤智光氏

日本IBM 執行役員 ワトソン&クラウドプラットフォーム事業部の吉崎敏文氏
レッドハットと協業、「OpenShift」上でIBMミドルウェアのコンテナが稼働
説明会ではまず同社 IBMクラウド事業本部長の三澤智光氏が登壇し、これまでのIBM Cloudの方向性を振り返りつつ、THINK 2018で発表された新製品/サービスをふまえた新たな展開を説明した。
IBM Cloudは“ワン・クラウド・アーキテクチャ”というコンセプトで拡張してきた。これはオンプレミス、IBM Cloud、他社パブリッククラウド(AWSやAzure、GCP)を同一のアーキテクチャで構成することにより、アプリケーションとデータをいつでも最適な場所に配置できるようにするというコンセプトだ。
従来型の業務アプリケーション、モノリシックなアプリケーションについてはVMwareで、また新しいタイプのアプリケーション、クラウドネイティブアプリケーションについては「Docker」コンテナとコンテナ管理ツールの「Kubernetes」を採用し、アプリケーションとデータの柔軟な配置を可能にしている。
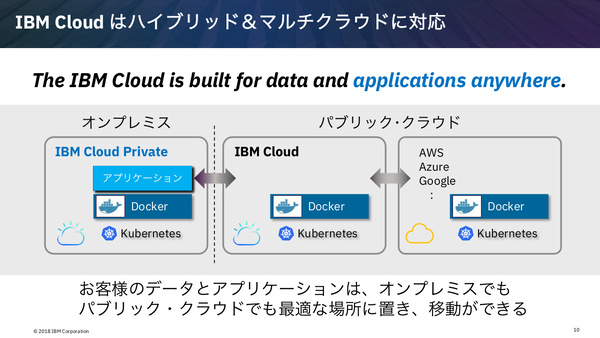
アプリケーションとデータを、オンプレミス、IBM Cloud、他社パブリッククラウドの間で柔軟に移動できる環境にするのがIBMの戦略
コンテナ環境については、昨年11月からCaaS(Container-as-a-Service)やPaaSをオンプレミス配置可能にする「IBM Cloud Private(ICP)」を国内提供している。ここではKubernetesだけでなく、コンテナカタログやマルチクラウド管理、ロギング/モニタリングなどの管理ツール群、IBM/OSSミドルウェア群もコンテナ化して提供しており、国内でもすでに数十社からの引き合いがあったと三澤氏は語る。
「(ミドルウェア群がコンテナで提供されることの)顧客メリットは2つある。まず、既存のモノリシックなアプリケーションのモダナイゼーションに役立つ。また、新規アプリケーションを開発する場合でも、ミドルウェアはメーカー製でやりたいというニーズはまだまだ強い。加えて、クラウド環境における(高可用性などの)非機能要件はミドルウェアで担保したいというニーズも強い」(三澤氏)
このICPに関して米IBMは先週、レッドハットとの協業強化を発表している。具体的には、ICPで提供している管理ツール群や主要ミドルウェア群(Db2、WebSphere、MQシリーズなど)のコンテナについて、レッドハットのコンテナ/PaaS基盤ソフトウェアである「Red Hat OpenShift」上での動作保証を行うというもの。これにより、すでにOpenShiftでコンテナ基盤を構築している顧客が、基盤はそのままに、ICPの管理ツールやミドルウェアを追加して環境を整備できるメリットがあると、三澤氏は説明した。
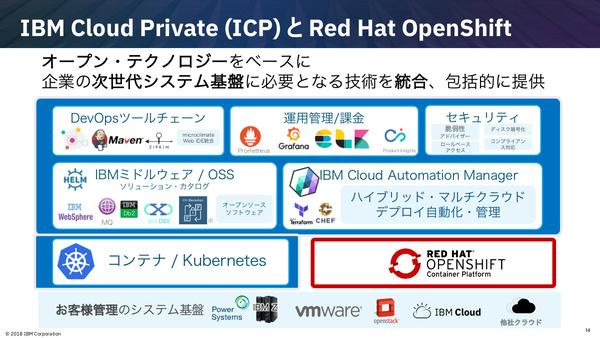
レッドハットとの協業による“ICP on Red Hat OpenShift”。ICPが提供する主要なIBMミドルウェアや管理ツールのコンテナを動作保証する
また、従来型の業務アプリケーション、モノリシックなアプリケーションについては、改修することなく「VMware on IBM Cloud」へと“リフト”する手段も提供している。三澤氏は、こちらもベアメタルサーバー+VMwareの機能でオンプレミス同様に非機能要件をカバーできる強みがあり、大企業顧客を中心に“リフト”のビジネスは好調に推移していると語った。
AIに“きれいなデータ”を提供?「データとAIの時代」に向けた新たな戦略
こうした“ワン・クラウド・アーキテクチャ”をベースに、IBMが次なる方向性として取り組み始めているのがデータとAIの時代」に向けた基盤整備だ。特に、単なるデータレイクを超える“Beyond Data Lake”の実現をテーマに掲げており、AI/機械学習との組み合わせによるデータ活用を前提としたビジョンを持っている。
「賢いAIを生み出すためには『きれいなデータ』で学習させることが必要だ。しかし、社内のさまざまなデータを集めただけだと、えてして“(データ)レイク”ではなく“沼”になりがち」「先進企業におけるAI/機械学習の事例を見ると、工数の8割は『データの準備作業』に費やされており、この部分を短縮していく必要がある」(三澤氏)
3月のIBM THINKでは、ICPベースでデータサイエンティスト向けアプリケーション群を備えたオンプレミスデータ基盤「IBM Cloud Private for Data」が発表されたほか、データ/Watson連携基盤のSaaS「IBM Watson Studio」も強化された(後述)。これにより、データの蓄積から探索/加工、分析、活用まで一貫した流れを、オンプレミスとクラウドの両環境でサポートする環境が整った。
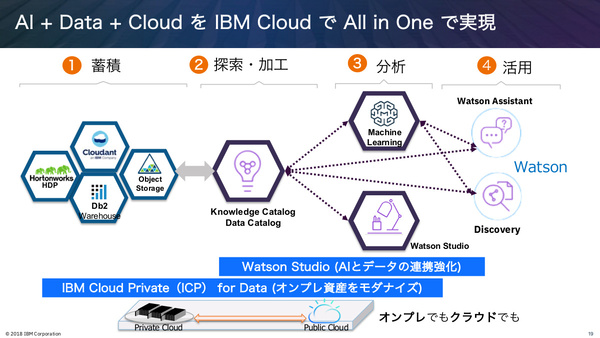
データの蓄積から探索/加工、分析、活用まで、一貫したデータ環境を提供。オンプレミス、クラウドの両方で提供するという点も重要な戦略だ
「特に、ファイアウォール内(オンプレミス)に配置できるICP for Dataは、持ち出せないデータがある一方で、そのデータを学習したモデルは活用したいという顧客にメリットがある。日本では5月末に発表する予定だ」(三澤氏)
AI/機械学習で有効活用できる「きれいなデータ」を提供可能にするために、IBMではデータ基盤に『データカタログ/ナレッジカタログ』を実装している。ICPが備えるのが「Data Catalog」、Watson Studioが備えるのが「Watson Knowledge Catalog」(今年3月に名称変更)だが、両者はほぼ同じ機能を提供するものであり「他社(クラウドベンダー)にない差別化ポイントだ」と三澤氏は説明した。データを活用したい社内ユーザーが、目的のデータを容易に探索/加工できるように支援するツールだ。
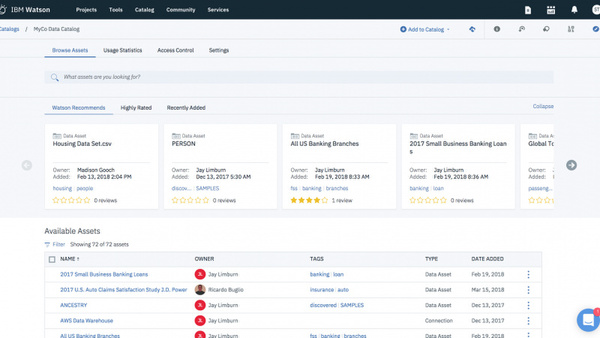
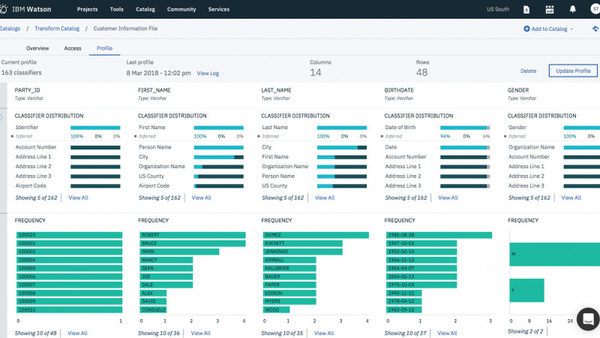
「Watson Knowledge Catalog」の画面(公式サイトより)。保有するデータ資産やデータソースがカタログ化されており、データ統合や匿名化などの処理も可能。またWatsonによる分析によりデータの内容予測や個々のユーザーへのデータレコメンドも行われる
THINK 2018で発表された「Watson Studio」や「Watson Assistant」を紹介
続いて同社 ワトソン&クラウドプラットフォーム事業部の吉崎敏文氏が、THINK 2018で新たに発表された主要なWatson関連サービスを紹介した。ここでは2つを紹介する(残る「IBM Watson Services for Core ML」は過去記事を参照いただきたい)。
まず、前出のWatson Studioにおける強化だ。多様なデータソースからデータを取得/準備し、カタログ化された学習データを使った機械学習/ディープラーニング処理と結果(モデル)の共有、データ分析などが行えるオールインワン基盤として、統合が強化された。
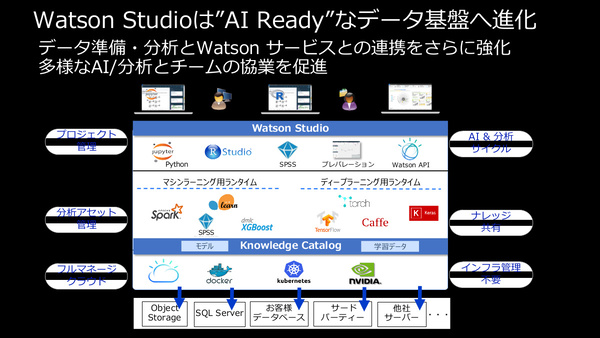
Watson Studioの概要。AI/データ分析基盤として、データカタログや機械学習/ディープラーニングのソフトウェアスタック、Watson API連携までをオールインワンでカバー
Watson Studioを導入している本田技術研究所(本田技研)では、複数リサーチ部門のデータサイエンティストが、全社のデータを自由に分析してその結果を共有する“デジタル・サンドボックス”として活用しているという。また、金沢工業大学ではAI講座のハンズオン環境として利用しており、作成されたモデルの背景情報(どんなデータから、どのようにして作成したか)がわかる点が好評だという。
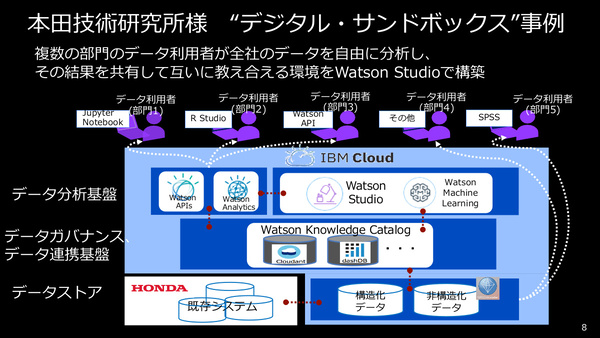
本田技研におけるWatson Studioの導入事例。各部門のデータ利用者が社内データに自由にアクセスでき、分析結果を共有できる環境を提供している
なお、クラウド上のWatson StudioとオンプレミスのICP for Data(前出)は、学習データやモデル、ナレッジカタログをセキュアに相互連携可能であり、顧客の要件に応じて“場所”を使い分けられる。たとえばWatson Studioのディープラーニング環境で開発したモデルを、オンプレミスのアプリケーションに適用する、といった使い方だ。
またTHINKでは、従来のWatson ConversationとWatson Virtual Agentを統合した「Watson Assistant」も発表された。チャットボット開発用に「照会応答機能」を提供するサービスで、いくつかのユースケースに特化した「学習済みインテント」があらかじめ組み込まれている点が大きな特徴。これにより、ユーザー自身で学習をさせる必要がなく、短期間でチャットボットを開発できるとしている。すでに一部ユースケースでは日本語のインテントも学習済みだ。
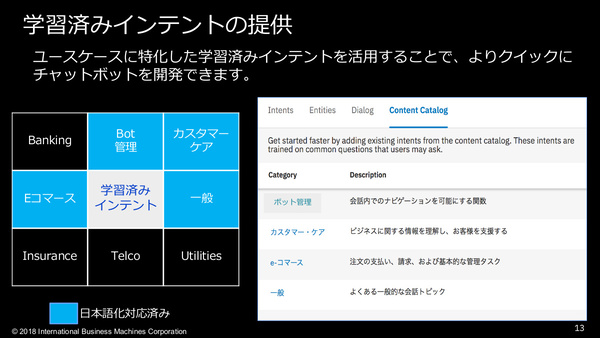
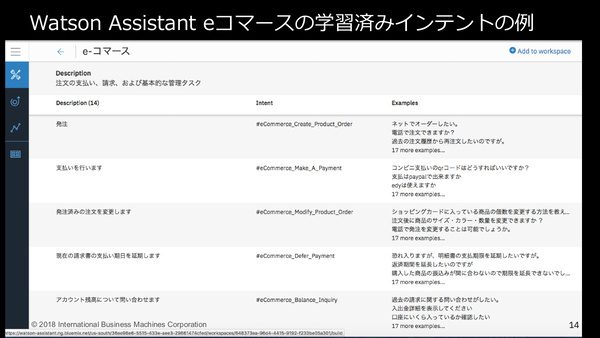
「Watson Assistant」では学習済みインテントが提供される。インテントとは、ユーザー(人間)の言葉がどんな「意図(intent)」を持つものかを示す辞書のようなもの
最後に吉崎氏は「WatsonはビジネスのためのAI」であるというIBMのテーマを掲げ、「AIをビジネスプロセスに組み込む」「より効率的な学習が可能」「顧客データに対する明確なポリシー」の3点を同社の優位性として挙げた。
なおWatson関連ビジネスの動向について吉崎氏は、一昨年の導入検討段階では個別案件に時間がかかっていたが、昨年は本番稼働段階へと一気に進んでそのペースが速まり、案件も増えたため「問題はやる人(エンジニア)が枯渇していること」だと述べ、パートナーへのスキルトランスファーも積極的に実施していきたいと語った。今年スタートした新たなパートナー制度「IBM Cloudパートナー・リーグ」が取り組みの主軸になるという。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



