




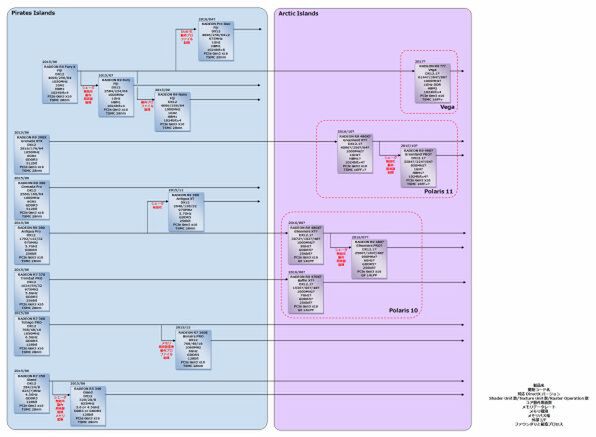
2015年~2017年のAMD GPUのロードマップ
ハイエンド向けの
Polaris 11
次がPolaris 11の話である。前回のロードマップではここにHBM2を「?」付きで入れたのだが、先のRaja Koduri氏のスライドからここがHBM1でほぼ確定したことになる。
実際のところHBM2のままでは、4チップではやや帯域が過剰すぎ、一方1/2チップだと容量的に不足があったので、HBM1のままというのは理に適っている。
強いて言えばハイエンド品が4GBのままでいいのか? というあたりだが、本命はより大容量のチップが利用可能なHBM2を採用したVega世代が2017年に登場するので、それまでのつなぎと考えれば妥当な戦略だろう。なお、Vega世代が登場するとPolaris 11がミドルレンジ~メインストリームになり、Polaris 10がメインストリーム~ローエンドに移動する形になる。
ちなみにPolaris 10/11世代の共通の特徴、つまりGCN世代との大きな違いの1つは、より広帯域なメモリーシステムへの対応と思われる。下の画像はFijiコアの内部構造図である。
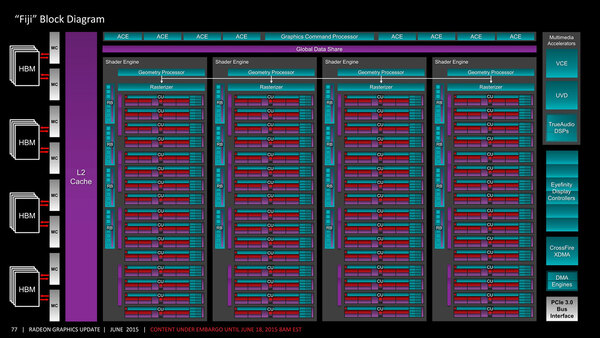
Fijiコアの内部構造図。CUは全部で64個搭載される。2015年のRadeon R9 Fury発表時のスライドより
64個のCU(Computation Unit)が2次キャッシュ経由でMC(Memory Controller)を挟んでHBMにアクセスする形になっている。問題はこの2次キャッシュとMCの間のつなぎ方である。
Hawaii/Grenadaコアの場合、8つのメモリコントローラーの先に、各々独立した32bitのGDDR5メモリーが接続されていた。GDDR5の場合、8nプリフェッチ(1回読み込み命令を出すと連続した8つのアドレス分のデータがやってくる)方式なので、1回のメモリーアクセス毎に32bit×8=32Bytes単位で読み取れることになっていた。
ところがHBM1の場合、プリフェッチこそ2nであるが、メモリバス幅は512bitとなる。もっと正確に言えば、HBM全体のメモリーバス幅は1024bitであるが、内部は8つのチャネルに分割されており、それぞれ128bit幅となっている。
したがって、このうちの1チャネルだけを使えば1回の読み取りサイズは128bit×2=32Bytesとなるのだが、実際には8chが2つのMCに接続されているので、1つのMCからはまとめて512bit分のアクセスをすることになり、結局512bit×2=128Bytes単位でのアクセスになってしまう。つまり32Bytes読み込もうとすると128Bytesやって来ることになり、96Bytes分無駄が出てしまう。
これを避けるには、2次キャッシュから128Bytes単位でアクセスするようにすればいいのだが、これを変更すると今度はCUと2次キャッシュの間のアルゴリズムの変更も必要になってしまう。最終的にはCUが、もっと大きな単位でのメモリーアクセスを許容するような構成にする必要がある。
先ほど「技術的にはGDDR5Xを採用する可能性もある」と書いたのはまさにこの点である。GDDR5Xは16nプリフェッチを採用するので、1回のメモリーアクセスあたり64Bytesが読み込まれる。ただPolarisが仮に128Bytesだけでなく64Bytesも許容するような作りになっていれば、技術的にはGDDR5Xでも性能を引き出すことは容易だろう。
ということで、前回のロードマップからの変更点はそれほどないのだが、AMDのGPUアップデートをお届けした。来週はNVIDIAのアップデートをお届けする予定だ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















