




ムーアの法則の恩恵を一番享受したデバイス
図3上側はPALの基本的な概念図(実際には4入力・4出力のデバイスは存在しなかったはず)であるが、縦の配線は入力信号、横の配線がANDの配線となる。入力信号はそのままとNOTを介したものの両方が用意される形だ。
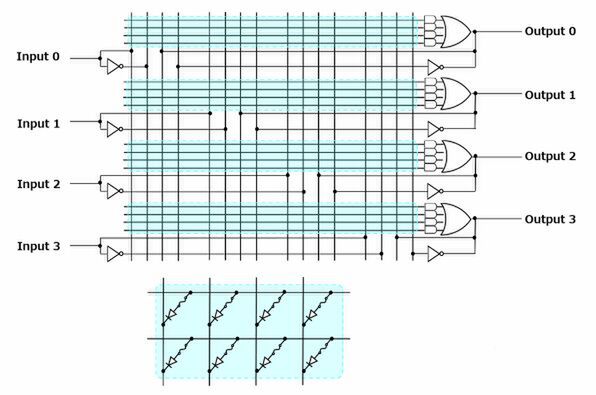
図3 PALの基本的な概念図(上)とPAL16R8の内部回路(下)
水色の部分が回路を入力するところである。その回路の詳細が図3の下側である。縦配線と横配線をつなぐ形でヒューズが入っているのがわかるかと思う。このヒューズをOn/Offすることで、どの信号をどのANDに入力するかを選択できるというわけだ。
このANDユニットの後にはORユニットが用意されており、ANDとORを組み合わせる(さらに信号はそのままと、NOT付きが用意される)ので、これを組み合わせて図1や図2の表にあたるものを実装しようというわけだ。
ちなみに図3の構造は、PAL風に言うならば8R4(8入力、4出力)に相当するが、実際には16R8や22R10など、もっと入出力が多い構成が一般的である。
下の画像はPAL16R8の内部回路である。フリップフロップが付いて後段でラッチできるなどの違いはあるが、基本的には図3の回路そのままなのがおわかりいただけよう。
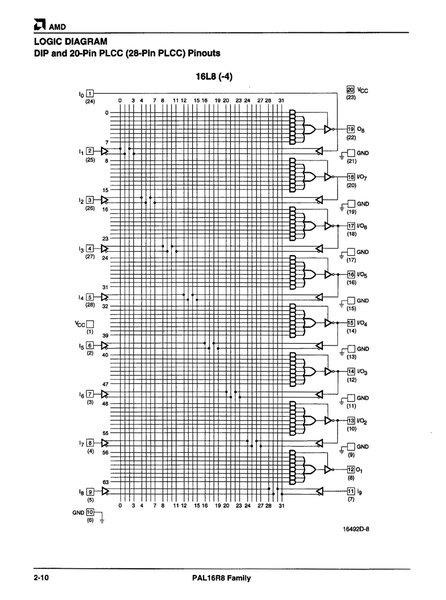
PAL16R8の内部回路。パッケージは20ピンのDIPのほか、20/28ピンのPLCC(正方形のプラスチックパッケージ)も用意された。
画像の出典は、AMDが1996年2月にリリースしたPAL16R8 Familyのデータシートより
このPALのアイディアはあっというまに広がり、PLA(ANDだけでなくOR側もプログラム可能)、GAL(AND/ORのプログラムが可能なほか、OR出力をAND入力にできる)など機能が増えた。
また当初はロジックのプログラミングは文字通りのヒューズ式で、一度書き込むと二度と上書きができないものだったが、EPROMと同じ方法で紫外線によるプログラム消去と電気的な再プログラミングを可能にしたものや、EEPROM同様に電気式消去/再プログラミングが可能なもの(GALがこれに相当する)など、さまざまな製品が出てきた。

紫外線によるプログラム消去と電気的な再プログラミングを可能にしたもの。AlteraのEP300というPALの一種で、紫外線でプログラムを消去するための窓があいているのがわかる
画像の出典は、“アルテラの設立当初を振り返る”
やがて、このPALやGALを複数搭載して大規模な回路を作れるCPLD(Complex Programmable Logic Device)も登場している。
ではFPGAとはなにか? というと、また表に話が戻る。配線の組み合わせを駆使して表を実現しようとするから話が難しいのであって、表を表のまま保持してそれを見て出力を決めれば話は簡単になる。
例えば図1/2の表であれば、入力が4bit、出力が3bitだから1行あたり7bitになる。なのでこれを16行分、容量にして112bitのテーブル(これをLUT:Look Up Tableと称する)をSRAMの形で保持しておく。
入力はそのままテーブルのアドレスとみなせるので、入力値にあわせたアドレスのテーブルに格納された出力の3bit分をそのままアウトプットとして出力すれば処理が終わる。
このFPGAは、基本SRAMだけで構成できるため、プロセスの微細化の恩恵を受けやすい。つまりプロセスを微細化すればそれだけ多くのSRAMを利用可能で、より大規模な回路が構成できることになる。
また90nmあたりからは多少スピードダウンしてきたが、それまでは微細化すればそのまま動作周波数があがり、消費電力が減るというムーアの法則の恩恵を一番享受したデバイスかもしれない。
もちろん単純なLUTだけですべてを構成させるのは無駄が多いため、専用回路もどんどん増えてきた。例えばバッファ用メモリー(※)や、DSPユニット、高速なI/Fなどで、やや前からはARMのプロセッサーを搭載しているモデルも出てきた。
※:これもSRAMだが、LUTベースでSRAMセルを再構築するのはバカバカしいので、メモリー専用のSRAMも用意されるようになった。
Xilinxが昨年末に出荷を開始したZynq UltraScale+MPSoCというシリーズ(製造プロセスはTSMCの16FF+)の場合、ハイエンドだとCortex-A53(1.5GHz)×4にCortex-R5(600MHz)×2という6つのCPUコアと、ARM Mali-400MP2(667MHz)のGPUコア、さらに周辺回路(DDR3/DDR4/LPDDR4 I/F、PCIe、USB、SATA、DP、GbEなど)を搭載し、それとは別に最大50万4000個のLC(Logic Cell:LUTに相当するもの)と38MbitのオンチップSRAM、1728個のDSPなどを搭載するに至っている。
またアナログ回路を搭載したFPGAもあり(旧Actel、現MicrosemiのSmartFusion 2シリーズがこの代表例)、さまざまな用途に利用できるようになっている。
※お詫びと訂正:図3とそれに伴う本文の一部に誤りがありました。正しい表記に訂正し、お詫びいたします。(2016年6月6日)
この連載の記事
-
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 - この連載の一覧へ





















の1台が今ならオトク!")
























")













