




Cortex-A7より上でCortex-A9より下?
Cortex-A53の性能は
一方Cortex-A53については、もう少し細かな数字が示されている。まず同程度の動作周波数を持つ「Cortex-A9 Dual Core」「Cortex-A7 Quad Core」「Cortex-A53 Quad Core」の3種類で、あるベンチマークテストを実行した結果が下のグラフである(関連リンクの「Performance」タブ参照)。
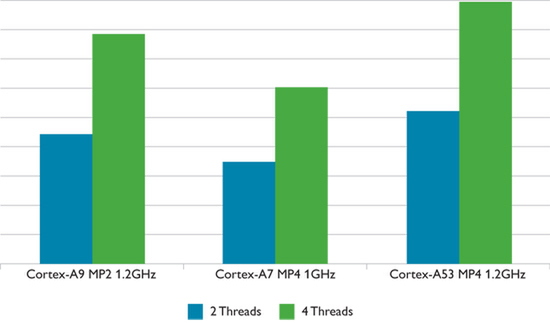
Cortex-A9/A7とA53の性能比較。ただしテスト内容は「整数演算および若干の浮動小数点演算を含む、大規模および中規模データの処理を行なうベンチマーク」としか書かれていない
これで見ると、Cortex-A53は飛びぬけて性能が高いように見える。しかしCortex-A9がデュアルコアであることを勘案すると、単体性能で1番高速なのはCortex-A9であり、Cortex-A53の性能は、Cortex-A9とCortex-A7の間くらいであると想像される。
ちなみにCortex-A7は、「限定的な2命令同時実行」のインオーダーパイプライン構成である。限定的、というのは「どんな命令でも2命令同時に実行できるわけではない」という意味で、インテルの「Atom」と同じタイプと考えればいい。これに比べると、完全2命令同時実行のCortex-A53は、より高い性能を引き出せるはずだ。それでも2命令をアウトオブオーダーで実行できるCortex-A9ほどではないということで、この結果はリーズナブルな性能に思える。
それ以外のベンチマーク結果では、やはりARMのサイトに掲載されているもので、Cortex-A5/A7とA53を比較した数値がある。比較対象はなぜかA9ではない。
| Cortex-A5 | Cortex-A7 | Cortex-A53 | |
|---|---|---|---|
| Dhrystone(DMIPS/MHz) | 1.6 | 1.9 | 2.3 |
| CoreMark(CoreMark/MHz) | 2.3 | 2.6 | 3.0 |
| SPECInt 2000 base | 290 | 350 | 450 |
これと同じベンチマークテストでCortex-A9の数字は、Dhrystoneの場合「2.5 DMIPS/MHz」と以前に発表されている。これと比較しても、Cortex-A53はCortex-A9よりやや遅い程度と推定される。ベンチマーク結果ではもうひとつ、主要なアプリケーションベンチマークの結果も示されている。こちらでもCortex-A53はCortex-A7よりは高速で、Cortex-A9と同程度という結果になっている。
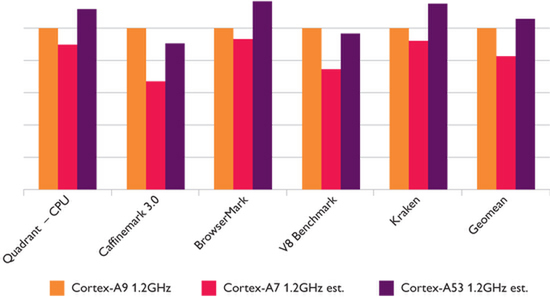
Cortex-A9/A7/A53のアプリケーションベンチマークテスト結果。これも計測環境がはっきりしないが、おそらくは1コア同士での数字と想像される
big.LITTLE Processingを視野に入れて
シンプルな構成にしたCortex-A53
ARMはCortex-A57とCortex-A53で、「big.LITTLE Processing」構成を可能とするとしている。元はと言えば、これはCortex-A15とCortex-A7を組み合わせて搭載した環境の話で、負荷に応じて動作させるコアを動的に切り替えるという仕組みである。
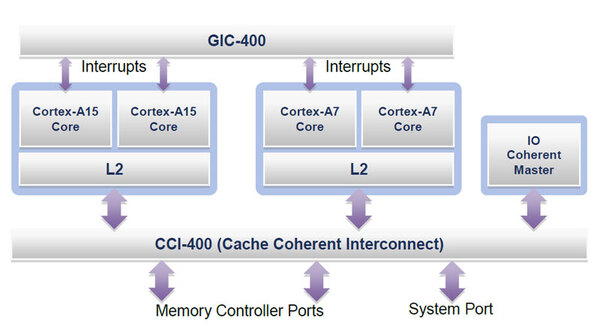
Cortex-A15/A7によるbig.LITTLE Processingの構成図。どうせなら2次キャッシュを共用化してしまえば、余分な転送が大幅に減るし、ダイサイズの無駄も最小限になるのにと思うのだが、それはできないらしい。2次キャッシュの占めるダイサイズは馬鹿にならないため、これはもったいない
例えばCortex-A15が2コアとCotex-A7が2コアという構成の場合、処理負荷が少なかったり待機中といったケースでは、Cortex-A15を完全にシャットダウンしてCortex-A7側を動かす。一方で処理負荷が高まってきたら、Cortex-A15に処理を引き継ぎ、Cortex-A7側をシャットダウンするという仕組みだ。従来のプロセッサーの省電力機構は、せいぜいが動作周波数を下げるとか不要なブロックをクロックゲーティングで止める程度だから、これに比べるとbig.LITTLE構成では、大幅に消費電力を下げることが可能になる。
その一方で、コアそのものの起動/シャットダウンには時間がかかるし、稼働中のプロセッサーの状態を、そのままもう片方のコアにコピーするのにもやはり時間がかかる。煩雑に負荷の状況が変わる状態でコアを切り替えたりすれば、オーバーヘッドが恐ろしく増えるケースも考えられる。また2種類のコアとそれぞれの2次キャッシュを搭載するため、ダイサイズが余分に大きくなることもデメリットとして考えられる。
実際にbig.LITTLEを採用するかはユーザーであるSoCベンダーの判断次第ではあるが、Cortex-A53の簡単な構造は、当然このbig.LITTLEを睨んだものである。つまり2次キャッシュはともかくコアそのものはなるべく小さく抑えることで、big.LITTLE採用時にダイサイズの肥大化を最小限に抑えるとともに、省電力動作時になるべく消費電力を抑える、ということが目的である。こう考えると、Cortex-A53の構成がCortex-A7+α程度のものであることの必然性が理解しやすい。
ARMはCortex-A57/A53をどんなアプリケーションに使おうとしているのか? それについては、次回にAMDのロードマップに絡めて説明したい。
この連載の記事
-
第781回
PC
Lunar LakeのGPU動作周波数はおよそ1.65GHz インテル CPUロードマップ -
第780回
PC
Lunar Lakeに搭載される正体不明のメモリーサイドキャッシュ インテル CPUロードマップ -
第779回
PC
Lunar LakeではEコアの「Skymont」でもAI処理を実行するようになった インテル CPUロードマップ -
第778回
PC
Lunar LakeではPコアのハイパースレッディングを廃止 インテル CPUロードマップ -
第777回
PC
Lunar Lakeはウェハー1枚からMeteor Lakeの半分しか取れない インテル CPUロードマップ -
第776回
PC
COMPUTEXで判明したZen 5以降のプロセッサー戦略 AMD CPU/GPUロードマップ -
第775回
PC
安定した転送速度を確保できたSCSI 消え去ったI/F史 -
第774回
PC
日本の半導体メーカーが開発協力に名乗りを上げた次世代Esperanto ET-SoC AIプロセッサーの昨今 -
第773回
PC
Sound Blasterが普及に大きく貢献したGame Port 消え去ったI/F史 -
第772回
PC
スーパーコンピューターの系譜 本格稼働で大きく性能を伸ばしたAuroraだが世界一には届かなかった -
第771回
PC
277もの特許を使用して標準化した高速シリアルバスIEEE 1394 消え去ったI/F史 - この連載の一覧へ




































