




音声や動画からも“同じ人物”を生成できる時代へ
Stable Diffusionは追加学習データの「LoRA」を使って似たキャラクターを作れる点が強みの一つですが、その作成環境も整ってきており、以前よりも作りやすくなってきています。
LoRAの作成には「Kohya_ss」という環境が普及していますが、それを利用するためのガイドも多く書かれ、設定用のJSONファイルも様々なものが配布されています。
学習元となる複数枚の画像にタグ付けをしたり、その修正をしたりする事前作業も、Stable Diffusion WebUI用の拡張機能の「Tagger」や「Dataset Tag Editor」の登場で、かなり容易になりました。10枚程度の画像にタグを付けて設定すれば、10分程度で独自LoRAを作成することができます。
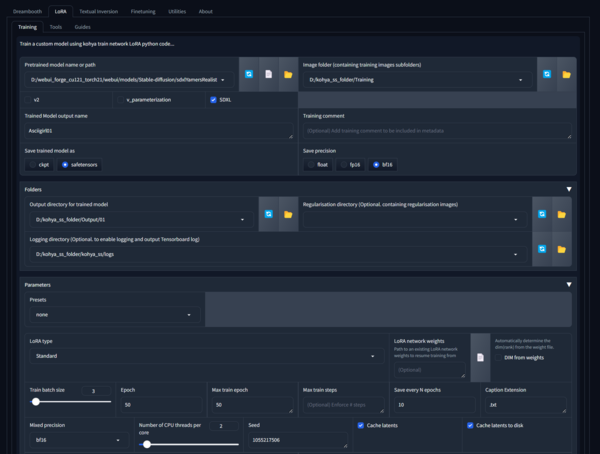
Kohya_ssの画面。今回の設定では、SDXLで14枚を学習元として、50ステップで実施。RTX4090環境で約10分で生成された
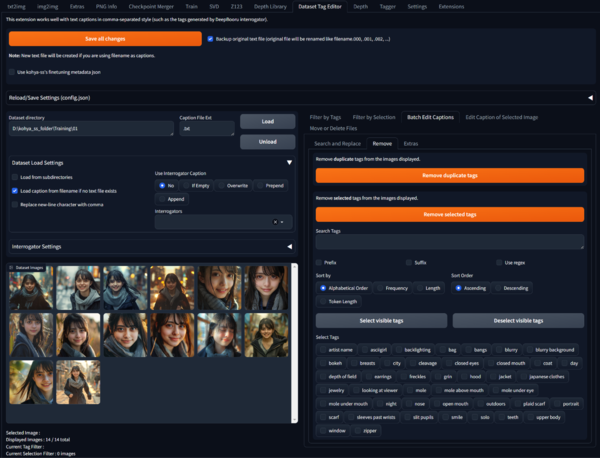
Stable Diffusion WebUIのDetaset Tag Editorの画面。それぞれの画像に設定されているタグを、まとめて削除したり、トリガーとなる共通するタグを仕込むことができる。左下がMidjourneyで作成した学習元とする14枚の画像。トリガータグを「asciigirl」としている

Stable Diffusion WebUI ForgeでのSDXLモデルで「LoRA asciigirl」を使っての生成結果。たった14枚からでも、精度高く似た顔を生成できる(筆者作成)
3月23日に渋谷で開かれた「東京AI祭」のパネルディスカッションでは、Midjourneyと共同でNijijourneyを開発しているSpellbrush Japanのジン・ヤンファ(Jin Yanghua)氏が、Creative Reference機能について、やはり高いニーズがあったことに触れ、「時間を掛けて、一貫性を持つ方法を開発した」と話す場面がありました。
ジン・ヤンファ氏は「キャラクターLoRAを作成する場合、GPUが必要になるので、プロダクトとしてMidjourneyと合わないので、もっと簡単な入力でコントロールできるように」と狙いを語り、「1枚のイラストではキャラの細かいところが反応しないとか、今のCreative Referenceは理想ではない。これからもっと改良していく」と話しました。
同じくStable Diffusionを開発しているStability AIのリードエンジニアのメン・リー(Meng Lee)氏は、「一貫性はLoRAが有名だが、今後もキャラ生成のために使い続けられる」と話しました。「ひとつのLoRAのファインチューニングで、いろいろな条件でも一貫性を保つ方法が出てくるだろう。テキストと画像だけでなく、オーディオやビデオから、ずっと同じ人を出すといった手法が出てくる」と、可能性を指摘しています。

Spellbrush Japanのジン・ヤンファ氏(左)とStability AIのメン・リー氏(右)
生成AIの弱点は、そのランダム性による生成過程の弱点から、キャラクターの首尾一貫性を維持できないところにありました。しかし、画像生成AI技術の発展によって、こうした問題も乗り越えられつつあります。同じキャラクターを連続的に生成したいというニーズは高く、今後も広くその方法はまだまだ発展が進むと考えられます。
一方で、課題もあります。現実に存在する人を使ったフェイク画像の作成も容易になっているとも言えます。Midjourneyのような画像生成のサービス事業者にはより対策が求められるでしょうし、利用者も他者の権利を侵害していないか注意をしつつ利用することが必要です。
筆者紹介:新清士(しんきよし)

1970年生まれ。株式会社AI Frog Interactive代表。デジタルハリウッド大学大学院教授。慶應義塾大学商学部及び環境情報学部卒。ゲームジャーナリストとして活躍後、VRマルチプレイ剣戟アクションゲーム「ソード・オブ・ガルガンチュア」の開発を主導。現在は、新作のインディゲームの開発をしている。著書に『メタバースビジネス覇権戦争』(NHK出版新書)がある。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第150回
AI
無料でここまで? 動画生成AI「LTX-2.3」はWan2.2の牙城を崩すか -
第149回
AI
AIと8回話しただけで“性格が変わる” 研究が警告する「おべっかAI」の影響 -
第148回
AI
AIが15万字の小説を1週間で執筆──「Claude Opus 4.6」が示した創作の未来 -
第147回
AI
ゲーム開発開始から3年、AIは“必須”になった──Steam新作「Exelio」の舞台裏 -
第146回
AI
ローカル音楽生成AIの新定番? ACE-Step 1.5はSuno連携で化ける -
第145回
AI
ComfyUI、画像生成AI「Anima」共同開発 アニメ系モデルで“SDXL超え”狙う -
第144回
AI
わずか4秒の音声からクローン完成 音声生成AIの実力が想像以上だった -
第143回
AI
AIエージェントが書いた“異世界転生”、人間が書いた小説と見分けるのが難しいレベルに -
第142回
AI
数枚の画像とAI動画で“VTuber”ができる!? 「MotionPNG Tuber」という新発想 -
第141回
AI
AIエージェントにお金を払えば、誰でもゲームを作れてしまうという衝撃の事実 開発者の仕事はどうなる? -
第140回
AI
3Dモデル生成AIのレベルが上がった 画像→3Dキャラ→動画化が現実的に - この連載の一覧へ














の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





