




GPT-2の処理の流れ

GPT-2の処理の流れ
まずはこの図を見てほしい。一番左の「GPT2 Phase」はGPT-2のそれぞれの処理(フェーズ)を、「Action」はそれぞれの処理でやっていること、「Tab in Spreadsheet」は対応するExcelのシート名をあらわしている。
Excelで左から右へタブを実行していくことで、この図の上から下まで、つまり入力(Input)から出力(Output)までを再現できるわけだ。
それでは、一番上(Excelでは一番左)の「Input」フェーズから順に見ていくことにしよう。
「Input」フェーズ

「Type_Prompt_Here」シート
「Input」フェーズは文字通りプロンプトを入力するフェーズで「Type_Prompt_Here」シートが使用される。
2列目の「Type Prompt Below Here」の下のセルに、プロンプトを一単語ずつ(カンマやスペースも1単語と換算)入力する。
初期状態ではサンプルとして「Mike」「is」「quick」「.」「He」「moves」と、ピリオドを含む6単語が入力されており、つなげると「Mike is quick. He moves(マイクは早い。彼は〇〇動く)」となる。
そして4列目の「Predicted Next Token(予測された次のトークン)」の下には「quickly」と表示されている。
つまり、GPT-2は「Mike is quick. He moves」という文字列の次に出てくる単語として「quickly(早く)」という形容詞が一番可能性が高いと予測したことになる。

プロンプトを変更
では、新しいプロンプトを入力しよう。今回はサンプルを少し変更して「Lisa」「is」「slow」「.」「She」「moves」の6文字を入力した
つなげると「Lisa is slow. She moves(リサは遅い。彼女は◯◯動く)」となり、正解はおそらく「Slowly」になるはずだ。なってくれ。
Tokenization(BPE)フェーズ

「Tokenization(BPE)」フェーズでは、「Input」に入力した単語をトークンに対応させる処理が実行される。
トークンとは、LLMがテキストデータを処理する際に使用される基本的な単位だ。具体的には、単語、文字、またはサブワード(単語の一部)を指す。

「id_to_tokens」シート
実はGPT-2は(そして他のLLMも)利用するであろうすべてのトークンのリストを持っており、「id_to_tokens」シートで見ることができる。これを見るとサンプルで登場した「Mike」という単語のトークンIDは「16073」ということがわかる。
なお、GPT-2のトークンリストには50256個のトークンが登録されている。このフェーズでは入力された単語をこのシートから探して該当のトークンIDを出力する作業をするわけだ。

サンプルの入力はこのようになっていた。ちなみに「.(ピリオド)」にも「13」というトークンIDが振られている。

処理を進めるために「シート再計算」をクリックしよう。

30秒ほどで結果が表示された。

「id_to_tokens」シート
「id_to_tokens」シートで確かめると「Lisa」のトークンIDは「44203」だ。
ここで1つ疑問が。単語がリスト内になかった場合はどうなるのだろう。

「Prompt_to_Tokens」シート
GPT-2ではBPE(Byte Pair Encoding)というアルゴリズムが採用されており、入力された単語がトークンのリストになかった場合には分割される。例えば仮に「dispense」という単語がリストにない場合は「dis」「pens」のように「サブワード」と呼ばれる単位に分割し、そのサブワードがリストに存在すれば、それぞれのトークンIDを振るという仕組みになっている。

「Constants」シート
「Prompt_to_Tokens」シートの右側の「Constants」シートには各種設定パラメーターが表示されている。これはLLMの基本的な構造と機能を定義するためのものなので、そのままにしておこう。
「Text & Position Embeddings」フェーズ

インプットのトークン化が終わったら、各トークンはそのトークンの意味や文脈を数値で表した「埋め込みベクトル」と呼ばれる高次元の数値ベクトルに変換される。これは、モデルがトークンの意味を理解する上での基礎となる表現だ。
もう少し詳しく説明すると、埋め込みベクトルとは、すべてのトークンを意味的に近い単語が高次元ベクトル空間上で近い位置にマッピングされるように、多次元ベクトル表現に変換する方法だ。
多次元というとSFっぽく聞こえるが、ここでの「次元」とは具体的な物理的空間をあらわすのではなく、データを表現するための「特徴量」や「属性」のことであり、次元数が多ければ多いほど、より詳細な意味関係をエンコーディングできる。例えばGPT-2は726次元、つまり726の値を持つベクトルとして表現されている。
なお、近年の言語モデルはさらに高次元なベクトルを使用する傾向にあり、GPT-3では1万2288次元ものベクトルが使われている。次元数が多ければ多いほど、より細かい意味の違いまでとらえられる可能性がある一方で、次元が増えすぎると、一つ一つの次元がどんな意味をあらわしているのか、人間からはなかなか理解しづらくなってしまうという傾向がある。加えて、次元数が多くなればモデルの大きさや計算リソースの要求量も増え、扱いづらくなる点にも注意が必要だ。
では「シート再計算」を押して処理を実行しよう。

「Token_to_Text_Embeddings」タブ
1行目が入力した単語、2行目がトークンID、そして3行目以降が埋め込みベクトルだ。
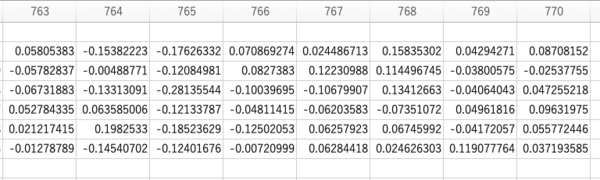
「Token_to_Text_Embeddings」タブ
GPT2の次元数は768なので、770(−2)列まで数値が並んでいるのがわかる。

「Token_to_Text_Embeddings」タブ
GPT-2は文内のトークンの位置も考慮されるため、位置埋め込み(Positional Encoding)と呼ばれる別のベクトルも算出され、その数値は先程のトークン埋込みに加算される。これにより、モデルはトークンの順序や文脈を理解することができるようになる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第47回
AI
9Bなのに120B超え!? Qwen3.5-9BがローカルAIの常識を変えた -
第46回
AI
面倒なファイル整理、AIに丸投げできる? 「Claude Cowork」をガチ検証 -
第45回
AI
面白すぎて危険すぎ! PCを“勝手に動かす”AI、OpenClaw(旧Moltbot/Clawdbot)とは -
第44回
AI
「こんなもの欲しいな」が、わずか数時間で形になる。AIツール「Google Antigravity」が消した“実装”という高い壁 -
第43回
AI
ChatGPT最新「GPT-5.2」の進化点に、“コードレッド”発令の理由が見える -
第42回
AI
ChatGPT、Gemini、Claude、Grokの違いを徹底解説!仕事で役立つ最強の“AI使い分け術”【2025年12月最新版】 -
第41回
AI
中国の“オープンAI”攻撃でゆらぐ常識 1兆パラ級を超格安で開発した「Kimi K2」 の衝撃 -
第40回
AI
無料でここまでできる! AIブラウザー「ChatGPT Atlas」の使い方 -
第39回
AI
xAI「Grok」無料プラン徹底ガイド スマホ&PCの使い方まとめ -
第38回
AI
【無料】「NotebookLM」神機能“音声概要”をスマホで使おう! 難しい論文も長〜いYouTubeも、ポッドキャスト化して分かりやすく -
第37回
AI
OpenAIのローカルAIを無料で試す RTX 4070マシンは普通に動いたが、M1 Macは厳しかった… - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















