




システムの稼働率は51.2%ほど
稼働率100%での性能は2069.11PFlops
もう少し細かく見ていきたい。まず(1)の「いまだにフルシステムでの稼働ができていない」である。Auroraの場合は1つのノードにXeon Max×2とData Center GPU Max×6が搭載される。以前の推定では、Xeon Max 9480とData Center GPU Max 1550が搭載されているのではないかとしたのだが、実際の詳細を見ると、CPUは52コアのXeon Max 9470が搭載され、動作周波数は2.4GHzになっていた(これは一覧のページには掲載されていないが、TOP500の結果をcsvファイルでダウンロードすると明記されている)。
一方のGPUの方はData Center GPU Maxとだけ記載されている。Data Center MaxはIntel Arkに掲載された128コアの1550以外に、112コアのData Center Max 1350が存在することがわかっている。ノード数を計算すると以下のとおりだ。
| GPUによるノード数の違い | ||||||
|---|---|---|---|---|---|---|
| Data Center GPU Max 1550の場合 | ノードあたり872コア。なので474万2808コア=5439ノード | |||||
| Data Center GPU Max 1350の場合 | ノードあたり776コア。なので474万2808コア=6111.866ノード | |||||
これを見る限りはData Center GPU Max 1550を採用していると考えるのが普通だろう。総ノード数1万624に対して5439ノードなので、51.2%ほどのノードが稼働している計算になる。これは「ざっくり半分」としてしまって問題ないだろう。1350を使った場合は約6111.9ノードというのは58%ほどに相当するため、半分よりはやや多く「6割程度」と表現すべきなのがこの傍証である。
さて、では5439ノードが稼働しているという前提のもとに理論性能を計算してみる。Xeon Max 9470は2.4GHz駆動であると示されているので、こちらはXeon Max 1個あたり1996.8GFlops。不明なのがData Center Max 1550の動作周波数で、連載723回で試算したようにBase 900MHz/Max Dynamic 1.6GHzで演算性能はそれぞれ29491.2GFlops/52428.8GFlopsという数字になる。
AuroraはRpeakが105万9325.75TFlopsとされているので、ノードあたりで言えば194.76TFlopsほど。ここから計算すると、1GHzにやや満たない970MHzで194.70TFlopsほどになる。おおむねこのあたりが動作周波数として設定されていると考えて良さそうだ。
意外に低めという見方もあるが、動作周波数を上げると簡単に消費電力が増えてしまい、さらに発熱も増えるので長時間の連続稼働が厳しくなる。なるべく低めに抑えて長時間動作を可能にするのが狙いだろう。これはFrontierも同じ、という話は連載670回で説明した。
ちなみにここまでの推定が正しいとすると、フルノードで稼働した際のAuroraの理論ピーク性能は2069.11PFlopsになり、一応2EFlops超えを果たす。連載723回では「実質2EFlops」と書いたが、実際にはもっと低めに抑えられていたわけだ。インテルの公約は「今年サービス開始されるAuroraは、『ピークの』倍精度浮動小数点演算性能が2EFlopsを超える」だったので、嘘はついていないことになる。
それにしても、なぜまだ半分しかシステムが稼働できないのか? に関する説明はインテルからもその他の筋からも今のところ流れて来ていない。あるいはハードウェアではなくソフトウェア側の問題なのかもしれない。
フルシステムの消費電力は
39.5MW~42.0MW程度か
次が(2)の「半分のシステムで消費電力が24.6MWに達する」問題。冒頭に引用したCutress博士のPostにもあるが、このシステムではコンピュート・ノードこそ半分しか稼働していないものの、その他(ストレージや管理システム、ネットワーク、水冷システムや空調)などはフル稼働している状態での数字だそうである。それでも24.7MWというのはかなり大きいのだが、だからといってフルシステムで倍になるわけではない、という話である。
連載635回でThomas Sterling教授が示したスライドでは1EFlops以上を60MW以下、という数字だったからこれよりはマシではある。マシではあるのだが、Top 10での性能消費電力比を示したのが下表である。
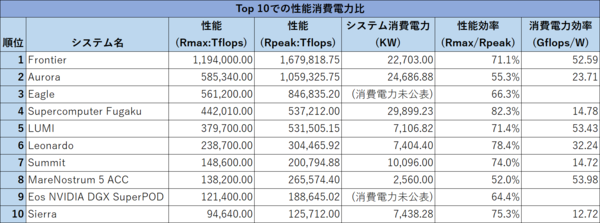
2018年に初登録されたSummitやSierra、あるいは完全なCPUのみの構成なので性能/消費電力比が低めの富嶽には勝っているものの、昨年11月に稼働したイタリアのLeonardo(今回6位:ちなみにXeon Platinum+NVIDIA A100の構成)にも負けているのは少しいただけない。Frontierと比較すると半分以下でしかない。
加えて言えば、このTop 10で最高効率なのは8位のMareNostrum 5 ACCだが、Xeon Platinum 8460YにNVIDIA H100を組み合わせている構成であり、別にSapphire Rapidsに問題があると考えるのは早計だろう。
ではAuroraがフル稼働するとどの程度の消費電力になるかを考えていこう。Cutress博士はもう少し細かい考察をすでに掲載しており、コンピュート・ノード以外の消費電力が2~4MWだとするとフルシステムでは36MW/EFlops程度とかなり数字が悪いが、これが8~10MWクラスだとすると効率は22MW/EFlopsになり、Frontier(19.0MW/EFlops)に近づくとしている。
ただこの計算、Frontierの方もインフラとコンピュート・ノードの数字を分けて計算する必要があるわけで、同じ算出方法だと仮にインフラを8MWとすれば17.3MW/EFlops程度になることを考えると、まだ差は大きいように思う。
話を戻すと、フルシステムの消費電力を推定するには、そうしたインフラの分をある程度考慮する必要がある。筆者はフルシステムでは2倍よりずっと低い、1.6倍~1.7倍程度と想定している。つまり39.5MW~42.0MW程度だ。性能はノード数に直線的に比例すると仮定すると1143TFlopsほど。効率は27.2~29.0GFlops/W程度に収まると想定している。60MWよりだいぶ低いだけでもマシではないかと思う。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































