




前回は、EUVでも普通に露光できるのは5nm世代まで、という話をした。今回は、ダブルパターニングとSculptaという新技法を解説しよう。
ちなみにTSMCはN5のプロセスジオメトリー(Contact Poly PitchやFin Pitchなど)を一切説明しておらず、ただN7世代と比較するとSRAMセル(HD:High Density)の寸法が0.78倍(0.021μm)になった、という数字のみを発表している。幸いにSamsungの5nm世代(5LPP:現在はSF5という名称になっている)の数字は公開されている。
| Samsung 5nm世代のプロセスジオメトリー | ||||||
|---|---|---|---|---|---|---|
| Contact Poly Pitch | 60nm(HP)/54nm(HD) | |||||
| Fin Pitch | 27nm | |||||
| M0 Pitch | 36nm | |||||
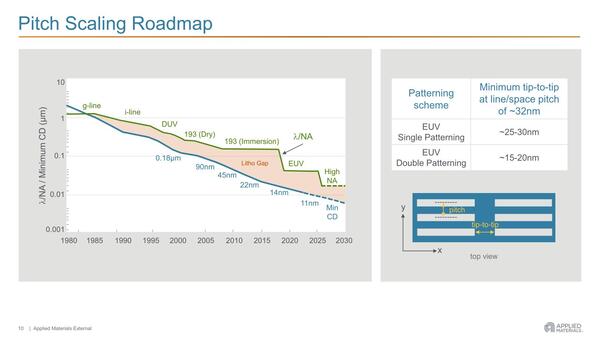
下の画像と比較してもらうとおおむねIntel 7に近いが、FinやM0はもう少し密度が高いという程度で、Intel 4にはやはりおよばないことがわかる。フィンの間隔などはそろそろEUVのシングルパターニングの限界に近いことがわかる。

インテルの22nmと14nmのピッチサイズ比較
そしてTSMCで言えばN3、Samsungで言えば旧3GAE(3nm GAA Early:現在はSF3A)以降、インテルのIntel 4以降ではもうシングルパターニングでは限界に達している。そこでダブルパターニングが登場することになった。
ここからはApplied Materialsの発表資料より。右の図で青が配線がある場所、白は配線がない場所である。2組のフィンの間隔が、シングルパターニングでは最小25~30nmなのに対し、ダブルパターニングでは15~20nmまで縮められるとする
EUV露光を2回実行する
ダブルパターニング
具体的にどうするか? であるが、例えば上の画像にも出てきた上下方向に並ぶフィンを貫くように縦方向に配線を構築するというケースでは、以下の工程で実装することになる。
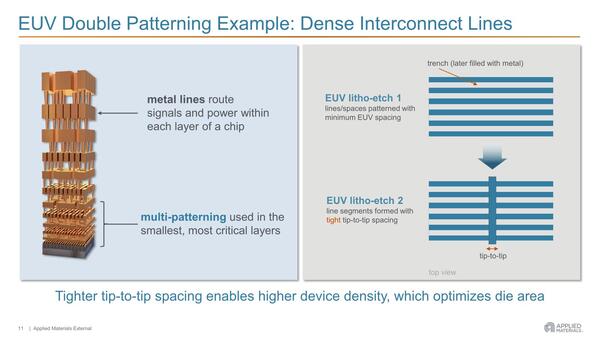
ダブルパターニングの例。チップ間の間隔が狭くなるためデバイス密度が高くなり、ダイ領域が最適化される。これは主に下部の配線層(M0~M3あたり)で重要になってくる技術である
(1) まずフィンを最初のEUV露光→エッチングで構築する。縦方向の配線は考えない。
(2) エッチングした溝を一旦金属で埋める。
(3) 2度目のEUV露光→エッチングで、今度は縦方向の溝を作る。
(4) (2)で埋めた余分な金属を取り除く。
これは穴を掘る場合も同じだ。DRAMやフラッシュでは深い穴を掘る必要があるが、それとは別にロジック向けでもVIA(貫通電極)向けに穴を構築する必要がしばしばある。
これはトランジスタと配線層、あるいは配線層同士の接続に使われるし、最近ではチップ同士の3D積層(AMDの3D V-Cacheなどこの最右翼だ)には膨大な数のTSV(シリコン貫通電極)が使われるから、高密度の穴開けが要求されることもある(*1)。
ただしEUVのシングルパターニングでは穴の直径はともかく、穴の間隔をそれほど詰められなかった。そこでダブルパターニングで2回に分けて穴を開けることで密度を高める方策がとられていた。要するに以下の工程になるわだ。
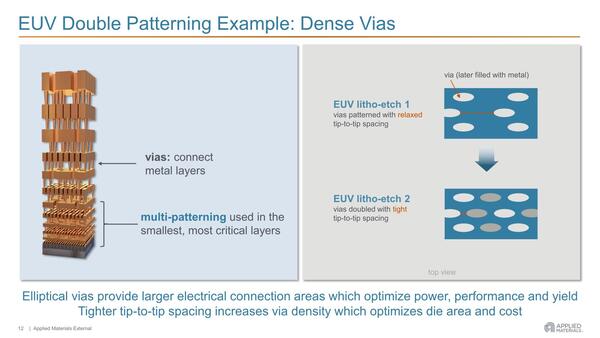
ダブルパターニングの例。楕円形の穴は、より大きな電気接続領域を提供し、性能と歩留まりを最適化する。こちらも同じく、下部の配線層で重要になる
(1) まず白い穴を最初のEUV露光→エッチングで空ける。
(2) エッチングした溝を一旦金属で埋める。
(3) 2度目のEUV露光→エッチングで、今度は灰色の穴を空ける。
(4) (2)で埋めた余分な金属を取り除く。
この方式の問題はいろいろある。まず2回のEUV露光→エッチングの際に位置のずれがあると、それでアウトである。ダブルパターニングはArF(フッ化アルゴン)時代にはさんざん行なわれていた技術であるが、透過式マスクと反射式マスクではやり方が違うし、位置合わせの精度はArF時代よりもさらに厳しい。
またEUV露光を2回実施するので、それだけ消費電力(や薬品類)の消費も大きく、スループットもそれだけ落ちる。ということはウェハーコストの増大につながるわけだ。1回のダブルパターニングあたりおおむね70ドル程製造コストが上がる、というのがApplied Materialsの試算であるが、このダブルパターニングをどれだけする必要があるのか? というのが次の問題だ。
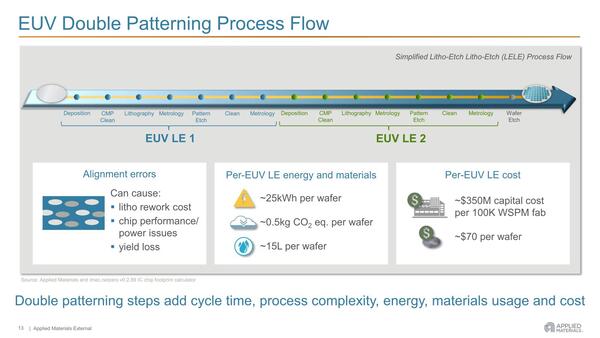
スループットに関しては、もうEUV露光機の数を増やすしか手が無いわけで、ざっくり言えばシングルパターニングの場合の倍の数のEUV露光機が必要になる。ただそこまでやってもリードタイムが倍になることそのものは変わらない
例えばTSMCのN3の場合、25回のEUV露光が必要で、しかもそのほとんどがダブルパターニングだった。ということは、仮に20回だとしても1400ドルほど原価が上がることになる。
N3Eは露光を19回に減らし、しかもシングルパターニングで済むようにプロセスジオメトリーを変更したことで、大幅に製造難易度とコストを下げたことで広く採用されるようになったことを考えると、できればEUVのダブルパターニングは避けたいという意向が働くのは無理もない。
ただN3Eはともかく、今後登場する予定のTSMCのN3P/N3X/N2やSamsungのSF3(旧3GAP:2024年量産開始予定)、Intel 3/20A/18Aなどではダブルパターニングの利用は避けられないと見られていた。
(*1) 3D積層用のTSVは、現在は双方のダイの熱などに起因する歪みに対応する「遊び」を確保するために、あまり高密度での実装にはなっていない。ただ今はともかく今後も密度が低いままか? というのはまた別の話である。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ










とBTO PCならではの特注PCパーツに大興奮")
























ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












