



「S/4HANA」などのデータが持つコンテキストを活用可能、ビジネスKPIに対応した分析処理を容易に
新製品「SAP Datasphere」が掲げる“ビジネスデータファブリック”とは
2023年03月23日 07時00分更新

SAPジャパンは2023年3月22日、データ管理ソリューションの新製品「SAP Datasphere」を提供開始した。「SAP S/4HANA」やサードパーティを含むビジネスアプリケーションのデータソースに対して、リアルタイムかつ透過的なデータアクセスを可能にする。
SAP Datasphereは、これまで提供してきた「SAP Data Warehouse Cloud」の「次世代版製品」と位置づけられており、ビジネスユーザーも含むデータユーザーの視点に立って、分析モデル構築やデータカタログ、データ連携といった機能を強化している。データの持つビジネスコンテキストやロジックを損なわずに活用できる点も特徴で、SAPではDatasphereのコンセプトを「ビジネスデータファブリック」と表現している。
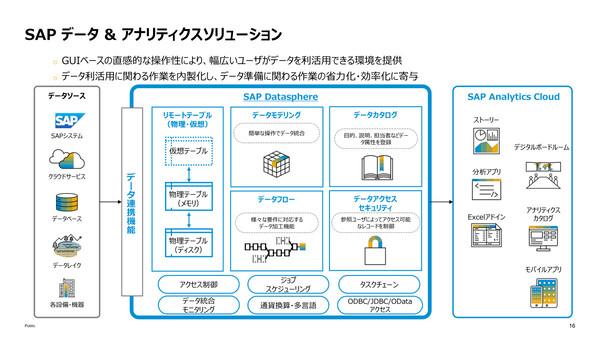
新製品「SAP Datasphere」(中央)の位置づけと主要機能


SAPジャパン ビジネステクノロジープラットフォーム事業部 事業部長の岩渕 聖氏、同社 カスタマーアドバイザリー統括本部 シニアディレクター 椛田后一(かばた きみかず)氏
「データのコンテキスト」がなぜ重要なのか
SAP Datasphereは、さまざまなデータソースからのデータ収集と統合、データカタログ、セマンティックモデリング(分析モデル構築)、データウェアハウス(DWH)、データフェデレーション(透過アクセス)、データ仮想化といった機能群を、単一のプラットフォームとして提供する製品。「SAP Business Technology Platform(SAP BTP)」上に構築したサービスとして提供され、データのセキュリティやガバナンス、暗号化といった機能も備える。

SAP Datasphereが提供する機能群の概要
SAPジャパン ビジネステクノロジープラットフォーム事業部 事業部長の岩渕 聖氏は、SAP Datasphereの開発背景について説明した。
近年ではビジネスアプリケーションのデータがさまざまなシーンで活用され始めている一方で、データソースはオンプレミスとクラウドに散在するようになり、複雑さが増した結果、データのガバナンスや統合が難しくなっている。
また現在行われているような、幅広いデータソースからデータレイクに集約し、DWHを介してデータマートを作成するという一連の処理の中では、それぞれのデータがもともと持っていた意味合いやデータの生成背景といった「データのコンテキスト」が失われる。
そこでSAPが掲げるコンセプトが、単なるデータファブリックとは一線を画する「ビジネスデータファブリック」だ。データの持つビジネスコンテキストとロジックを損なわず「意味のあるデータ」としてユーザーに提供すること、またデータの物理的な配置場所を意識せずに利用できることを実現するという。
「もともとSAPは、業務プロセスの中で部門をまたいで変化していくデータをエンドトゥエンドで把握し、それをきちんとユーザーに使ってもらう、あるいはプロセスをきれいに流すといった全体最適の世界を目指してきた。今回われわれが提供したいのは、前後のプロセスを意識したかたちで、きちんと意味合いを持ったデータを活用いただけるような仕掛けだ」(岩渕氏)
岩渕氏は、データのコンテキストの一例として在庫データを取り上げた。在庫管理システムのデータからは「現時点である製品の在庫が100個ある」ことは把握できるが、「3日後に何個あるか」はわからない。ただし、購買管理や生産管理システムの「3日後に100個入荷する」、受注システムの「明日50個出荷する」といったデータと組み合わせれば、3日後の在庫数も予測可能になる。


コンテキストのあるデータをユーザーに提供できる「ビジネスデータファブリック」を実現する
データのコンテキストがなぜ重要なのか。岩渕氏は、さまざまな企業がデータドリブン経営を目指すうえで、プロセスやITシステムから得られるデータを下から積み上げて利用する「プロセス・データ主導型」アプローチと、企業戦略からドリルダウンしてKPIを設定、管理する「戦略主導型」アプローチの両方を実行しているが、「その接合点が難しい」と指摘する。
「戦略主導型とプロセス・データ主導型の『接合点』をいかに精度高く合わせるのか、そこが多くのお客様で課題になっている。データのコンテキストを用いることで、この接合点をなるべく精度高く合わせていくことを狙っている」(岩渕氏)
単純にアプリケーションが持つデータを表示するだけではなく、KPIのようにビジネス的な意味合いを持つかたちに加工してユーザーに提供するといったことが、ビジネスデータファブリックというコンセプトの中心にあるという。
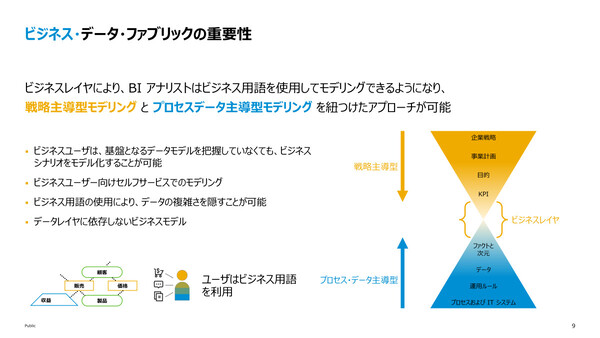
「ビジネスの言葉」と「システム/データの言葉」の整合性を高めるのが狙い
それを容易にするために、SAP Datasphereでは多数のKPIテンプレート、およびビジネスコンテンツを用意している。主要な指標や計算ロジック、データ抽出ロジックなどは簡単に実装できる仕組みだ。
「Datasphereでは、SAP自身が純粋なKPIのロジックだけでなく、ユーザーが見やすいダッシュボードのレベルまで提供していく。さらにはパートナーが持つナレッジやデータモデルを組み合わせた、パートナーによるテンプレートを提供することもできる」(岩渕氏)


ビジネス知識や業界ノウハウも盛り込まれた「KPIテンプレート」や「ビジネスコンテンツ」も提供する
さらに、パートナーを通じてサードパーティアプリケーションとの連携強化、データマーケットプレイスを通じた外部データの取り込みなどにも対応する。前者は今回、Databricks、Confluent、Collibra、DataRobotとのパートナー連携をグローバルで発表している(日本での協業は今後の予定)。後者はデータプロバイダーパートナーからデータを購入し取り込むだけでなく、企業間での非公開データ交換にも対応する仕組みを備えている。
旧製品からの強化ポイントは3つ
SAPジャパン カスタマーアドバイザリー統括本部 シニアディレクター 椛田后一氏は、SAP Datasphereのアーキテクチャや製品機能の概要を説明した。
椛田氏はまず、旧来のデータ管理プラットフォームとSAP Datasphereのアーキテクチャの違いに触れた。旧来のアーキテクチャでは、データソースにあるデータをいったんデータレイクに蓄積し、それを成形したうえでDWHに取り込み、データマートを作成するという手順が必要だった。そのため、ユーザーが必要とするデータを準備するまでに長いリードタイムが発生し、なおかつバッチ処理のため最新データを活用することもできなかった。
Datasphereでは、データ仮想化の技術を用いてこうした課題を解消するという。仮想テーブルを介してデータソースにあるリアルタイムデータへの透過的なアクセスが可能であり、高速なパフォーマンスが必要な場合はインメモリDBへのレプリケーションを実行して物理テーブルを用意することも可能だ。
さらに、データソースがS/4HANAなどのSAPアプリケーションであれば、データのビジネスコンテキストを失うことなくユーザーが活用することができると説明する。
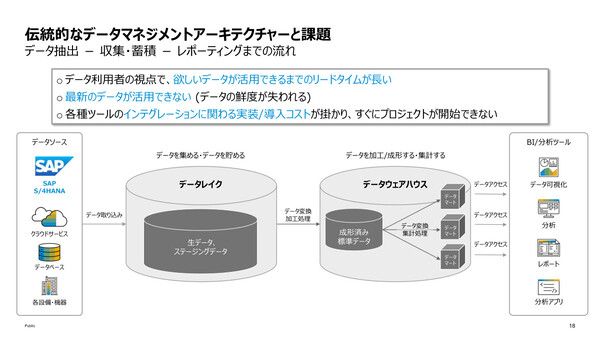
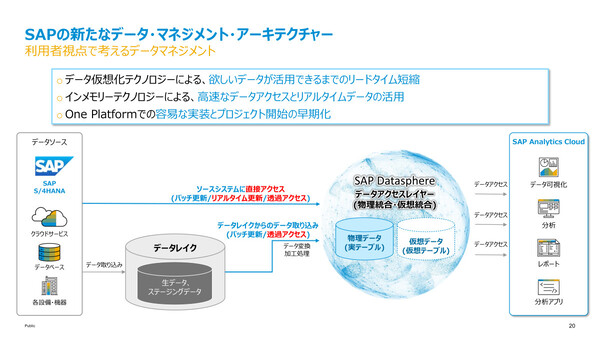
旧来のデータ管理アーキテクチャとSAP Datasphereのアーキテクチャの違い
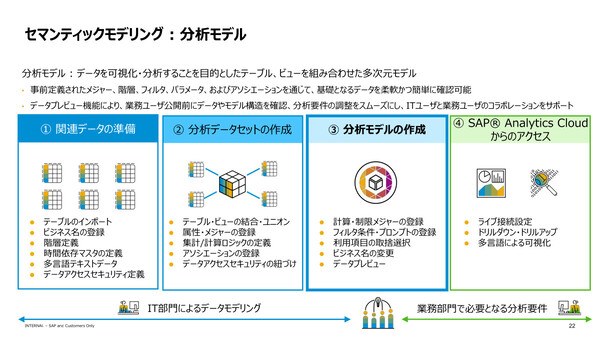
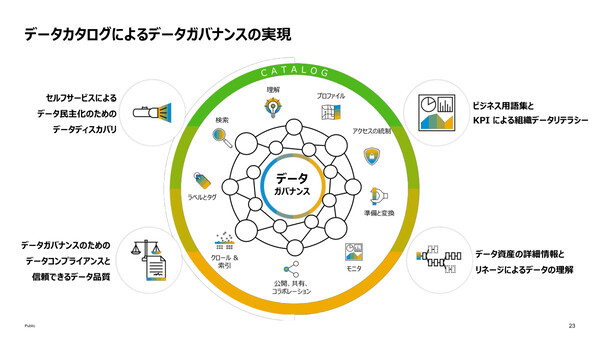
旧製品であるSAP Data Warehouse Cloudからの強化点として椛田氏は、「分析モデルの作成機能(セマンティックモデリング)」「データカタログによるデータガバナンスの実現」「データ連携機能の強化」の3点を挙げた。
1点目のセマンティックモデリングでは、さまざまなデータやアプリ、意味の定義、データエンティティ間の関連付けを行った分析モデル(データの可視化/分析を目的とした多次元モデル)の作成ができる。プレビュー機能も備えており、分析モデルの公開前にIT部門とビジネス部門の双方でビジネス要件に沿ったモデルになっているかどうかを確認しながら設計が進められるという。
2点目のデータカタログでは、分析モデルに組み込まれたセマンティック情報、全社共通のビジネス用語、KPIをデータまで連携させて(ひも付けて)管理できる機能を備える。ビジネス用語やKPIの定義、データ資産の詳細情報やリネージュによるデータコンテキストの理解や品質の維持、セルフサービスのデータディスカバリによるデータ民主化などを実現する。
3点目のデータ連携機能では、従来(SAP Data Warehouse Cloud)から提供してきたデータのリアルタイムレプリケーション、仮想データアクセスなどにおいて、データソース側にエージェントソフトをインストールすることなく、データ連携が可能になっている。
セマンティックモデリング、データカタログの概要
「このようなかたちで、SAP Datasphereでは各システムのデータ品質を高めて現場に提供し、現場主導のセルフサービス型データ活用環境を提供する。過去のデータではなくリアルタイムのデータを活用することで、ビジネス意思決定の早期化も実現する。さらにシステムが散在して複雑化している中でも、データ活用環境のシンプル化を目指す。特にS/4HANAなどのSAPアプリケーションに関しては、そこに定義されたビジネスコンテキスト、それをそのまま利用できるので、データを集めた先でもう一度データの定義をし直す必要がなく、すぐに活用できる。データ利活用のハードルを下げ、DXのスピード感をさらに上げて、現場主導型のビジネスの実現を支援する」(椛田氏)
本記事はアフィリエイトプログラムによる収益を得ている場合があります



