





グーグルの研究部門Google Researchは1月30日、フランスの研究機関IRCAM(Institut de Recherche et Coordination Acoustique/Musique)と共同で、入力された歌声にあわせた伴奏を生成するAIモデル「SingSong」を発表した。
Excited to share SingSong, a system which can generate instrumental accompaniments to pair with input vocals!
— Chris Donahue (@chrisdonahuey) January 31, 2023
📄https://t.co/1mRUaXvqVy
🔊https://t.co/8RGezPu5YQ
Work co-led by myself, @antoine_caillon, and @ada_rob as part of @GoogleMagenta and the broader MusicLM project 🧵 pic.twitter.com/3FXYM69N77
ボーカルと楽器のペアーを使って学習
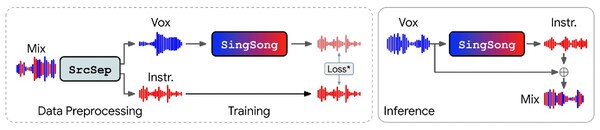
このモデルは最新の音源分離(ボーカルと楽器を分離する)技術と音楽生成技術をベースに開発されている。
具体的には、大量の音楽データに最新の音源分離アルゴリズムを適用し、ボーカルと楽器を分離。次に、同じくグーグルが開発した音楽生成AIの「AudioLM」で、ボーカルと楽器のペアーを学習させた。(図左)
この際、AudioLMをこの機能に特化するための様々な「特徴量化(Featurizations)」を行ななった結果、デフォルトのAudioLMと比べて性能が53%向上したという。
こうして学習させたSingSongにボーカルのみのファイルを入力すると、それにあわせた楽器(伴奏)のデータが生成される。これを元のボーカルと合成して伴奏付きの曲として出力するという仕組みだ。(図右)
ラジカセで録音した歌声からでも生成可能
ではその結果を聞いてみよう。このボーカルデータを使ってSingSongが生成したのがこの曲だ。アコースティックギターとコンガによる伴奏が生成されており実に自然に聞ける。
もう1曲、このボーカルデータを使って生成したのがこちら。データがラップだということを認識してヒップホップ調の伴奏が生成されている。
SingSongは10秒間の音楽データを使って学習されているが、この曲やこの曲のような少し長いボーカルデータでも自然な伴奏を生成できている。
さらに、市販のラジカセを使って録音された素人の歌声サンプルを使って生成したのがこの曲やこの曲だ。多少コード感がおかしいような気がしないでもないが、これはこれで味があると言えなくもない。
クオリティも高いとの実験結果
研究チームはSingSongが生成した音楽のクオリティを調べるために、同じボーカルを使ってSingSongが伴奏を付けた曲と、楽器データベース(MUSDB18)からランダムもしくは適切に選んだ伴奏を付けた曲を比較し、どちらが音楽的に優れているかを判断する実験を行なった。
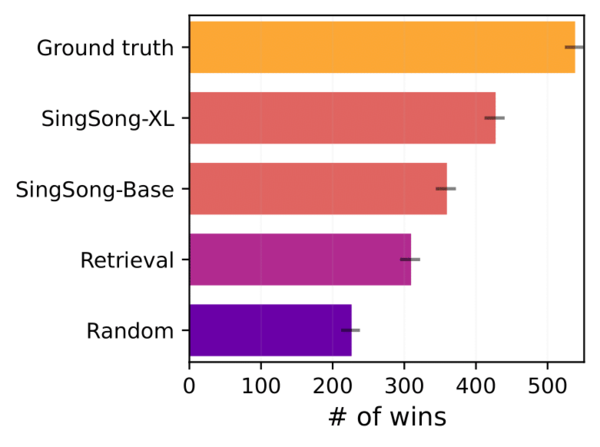
その結果が上図。一番評価が高いのが「Ground truth」。これは分離する前の元となる音源なので評価が高いのは当然だ。2番目の「SingSong-XL」と3番めの「SingSong-Base」がSingSongが伴奏を生成した曲。両者の違いは学習データ量であり、量が多いSingSong-XLの方が高い評価を得られた。
その次の「Retrieve」がデータベースから適切に選んだ伴奏を付けたもの、適当に伴奏を付けた「Random」は当然最下位になっている。
歌が歌えれば誰でも曲が作れる世界に
開発者のひとりChris Donahue氏は自身のツイートで「歌はわたしたちが音楽と関わる最も直感的な方法の1つです。(SingSongがあれば)歌える人なら誰でも豊かな楽器編成で新しい音楽を作ることができるかもしれないのです」とその可能性を示している。
楽器が弾けなくても、DAW(Digital Audio Workstation)が使えなくても、スマホに鼻歌を録音するだけでAIが伴奏を付けてくれる日も遠い未来ではないようだ。
なお、同氏はSingSongを今後数ヵ月のうちに一般公開したいと考えているとツイートを結んでいる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























